 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoTandemML: Active Learning Enhanced Tandem Neural Networks for Inverse Design Problems
Feb 21, 2025Inverse design in science and engineering involves determining optimal design parameters that achieve desired performance outcomes, a process often hindered by the complexity and high dimensionality of design spaces, leading to significant computational costs. To tackle this challenge, we propose a novel hybrid approach that combines active learning with Tandem Neural Networks to enhance the efficiency and effectiveness of solving inverse design problems. Active learning allows to selectively sample the most informative data points, reducing the required dataset size without compromising accuracy. We investigate this approach using three benchmark problems: airfoil inverse design, photonic surface inverse design, and scalar boundary condition reconstruction in diffusion partial differential equations. We demonstrate that integrating active learning with Tandem Neural Networks outperforms standard approaches across the benchmark suite, achieving better accuracy with fewer training samples.
AI Driven Laser Parameter Search: Inverse Design of Photonic Surfaces using Greedy Surrogate-based Optimization
Jun 20, 2024Photonic surfaces designed with specific optical characteristics are becoming increasingly important for use in in various energy harvesting and storage systems. , In this study, we develop a surrogate-based optimization approach for designing such surfaces. The surrogate-based optimization framework employs the Random Forest algorithm and uses a greedy, prediction-based exploration strategy to identify the laser fabrication parameters that minimize the discrepancy relative to a user-defined target optical characteristics. We demonstrate the approach on two synthetic benchmarks and two specific cases of photonic surface inverse design targets. It exhibits superior performance when compared to other optimization algorithms across all benchmarks. Additionally, we demonstrate a technique of inverse design warm starting for changed target optical characteristics which enhances the performance of the introduced approach.
Inverse design of photonic surfaces on Inconel via multi-fidelity machine learning ensemble framework and high throughput femtosecond laser processing
Jun 03, 2024We demonstrate a multi-fidelity (MF) machine learning ensemble framework for the inverse design of photonic surfaces, trained on a dataset of 11,759 samples that we fabricate using high throughput femtosecond laser processing. The MF ensemble combines an initial low fidelity model for generating design solutions, with a high fidelity model that refines these solutions through local optimization. The combined MF ensemble can generate multiple disparate sets of laser-processing parameters that can each produce the same target input spectral emissivity with high accuracy (root mean squared errors < 2%). SHapley Additive exPlanations analysis shows transparent model interpretability of the complex relationship between laser parameters and spectral emissivity. Finally, the MF ensemble is experimentally validated by fabricating and evaluating photonic surface designs that it generates for improved efficiency energy harvesting devices. Our approach provides a powerful tool for advancing the inverse design of photonic surfaces in energy harvesting applications.
Efficient Inverse Design Optimization through Multi-fidelity Simulations, Machine Learning, and Search Space Reduction Strategies
Dec 06, 2023This paper introduces a methodology designed to augment the inverse design optimization process in scenarios constrained by limited compute, through the strategic synergy of multi-fidelity evaluations, machine learning models, and optimization algorithms. The proposed methodology is analyzed on two distinct engineering inverse design problems: airfoil inverse design and the scalar field reconstruction problem. It leverages a machine learning model trained with low-fidelity simulation data, in each optimization cycle, thereby proficiently predicting a target variable and discerning whether a high-fidelity simulation is necessitated, which notably conserves computational resources. Additionally, the machine learning model is strategically deployed prior to optimization to reduce the search space, thereby further accelerating convergence toward the optimal solution. The methodology has been employed to enhance two optimization algorithms, namely Differential Evolution and Particle Swarm Optimization. Comparative analyses illustrate performance improvements across both algorithms. Notably, this method is adeptly adaptable across any inverse design application, facilitating a harmonious synergy between a representative low-fidelity machine learning model, and high-fidelity simulation, and can be seamlessly applied across any variety of population-based optimization algorithms.
Learning from learning machines: a new generation of AI technology to meet the needs of science
Nov 27, 2021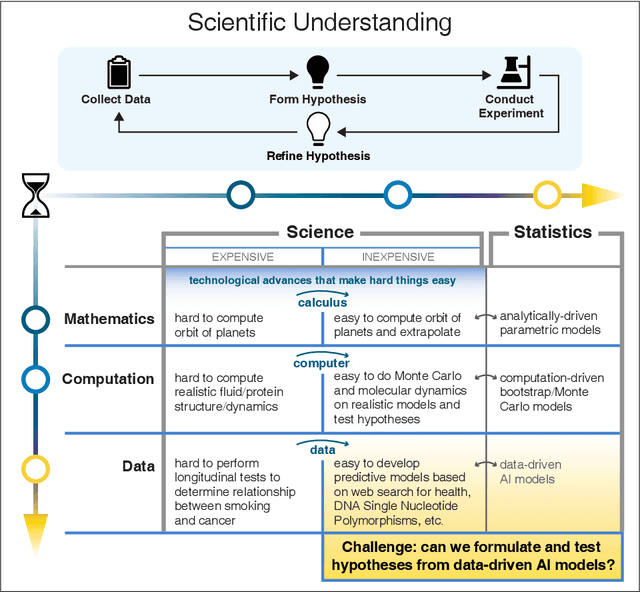

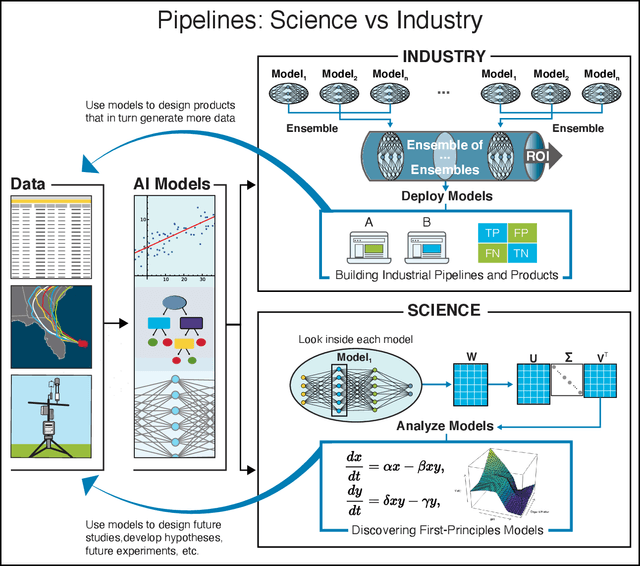
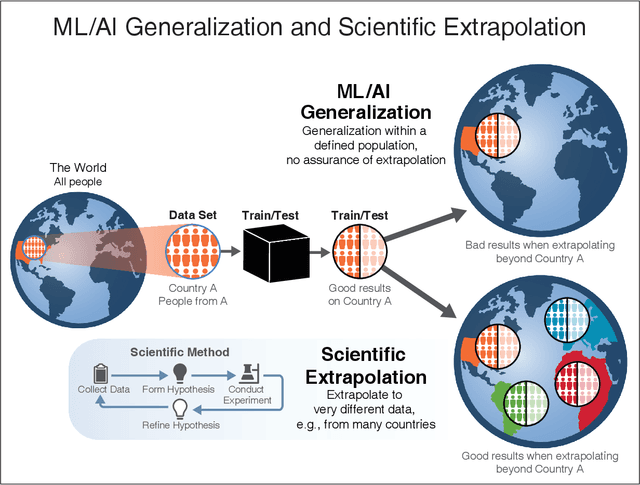
We outline emerging opportunities and challenges to enhance the utility of AI for scientific discovery. The distinct goals of AI for industry versus the goals of AI for science create tension between identifying patterns in data versus discovering patterns in the world from data. If we address the fundamental challenges associated with "bridging the gap" between domain-driven scientific models and data-driven AI learning machines, then we expect that these AI models can transform hypothesis generation, scientific discovery, and the scientific process itself.
Adaptive Gaussian process surrogates for Bayesian inference
Sep 27, 2018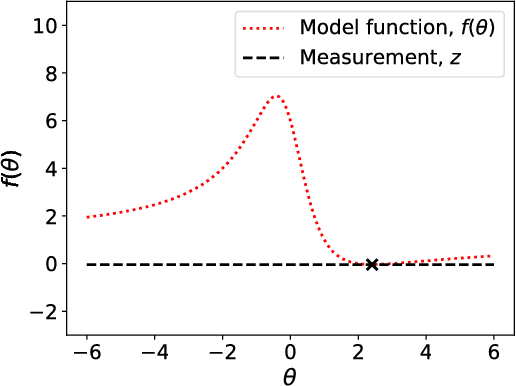
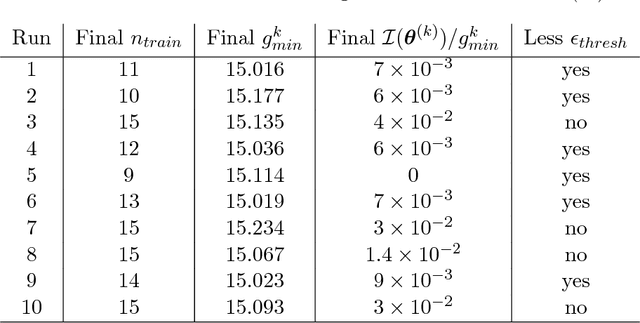
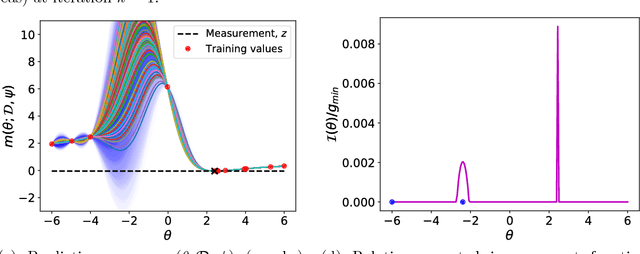
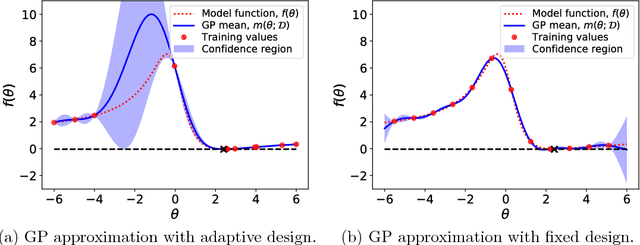
We present an adaptive approach to the construction of Gaussian process surrogates for Bayesian inference with expensive-to-evaluate forward models. Our method relies on the fully Bayesian approach to training Gaussian process models and utilizes the expected improvement idea from Bayesian global optimization. We adaptively construct training designs by maximizing the expected improvement in fit of the Gaussian process model to the noisy observational data. Numerical experiments on model problems with synthetic data demonstrate the effectiveness of the obtained adaptive designs compared to the fixed non-adaptive designs in terms of accurate posterior estimation at a fraction of the cost of inference with forward models.