 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Set Domain Adaptation for Image and Action Recognition
Jul 30, 2019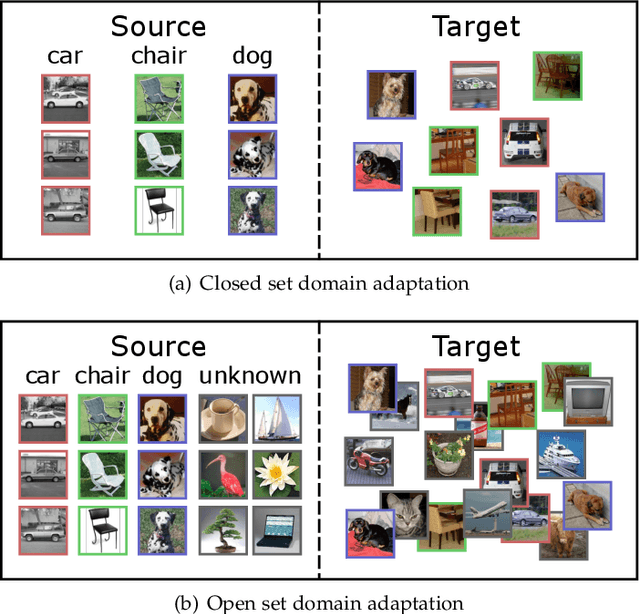
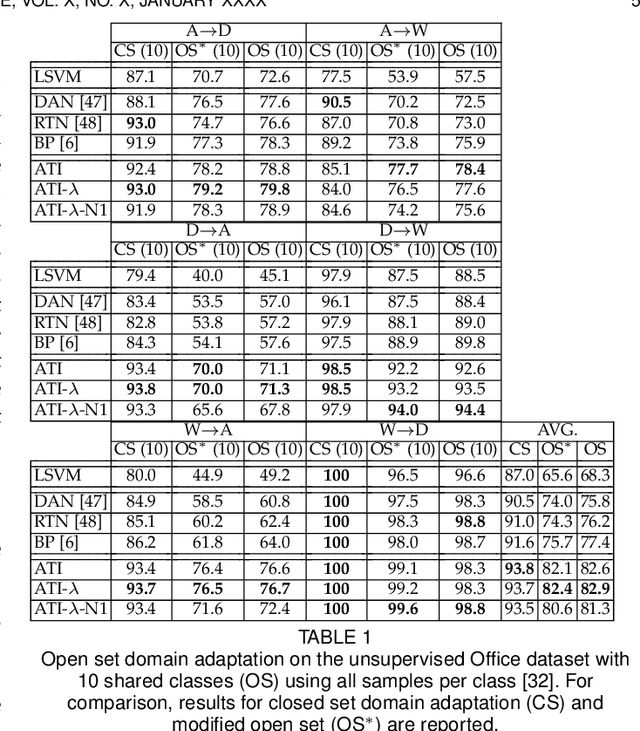
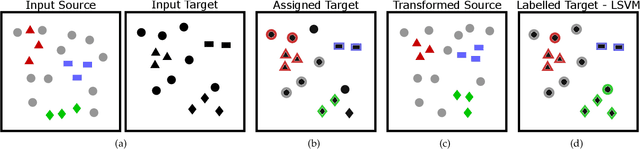

Since annotating and curating large datasets is very expensive, there is a need to transfer the knowledge from existing annotated datasets to unlabelled data. Data that is relevant for a specific application, however, usually differs from publicly available datasets since it is sampled from a different domain. While domain adaptation methods compensate for such a domain shift, they assume that all categories in the target domain are known and match the categories in the source domain. Since this assumption is violated under real-world conditions, we propose an approach for open set domain adaptation where the target domain contains instances of categories that are not present in the source domain. The proposed approach achieves state-of-the-art results on various datasets for image classification and action recognition. Since the approach can be used for open set and closed set domain adaptation, as well as unsupervised and semi-supervised domain adaptation, it is a versatile tool for many applications.
A Hybrid RNN-HMM Approach for Weakly Supervised Temporal Action Segmentation
Jun 03, 2019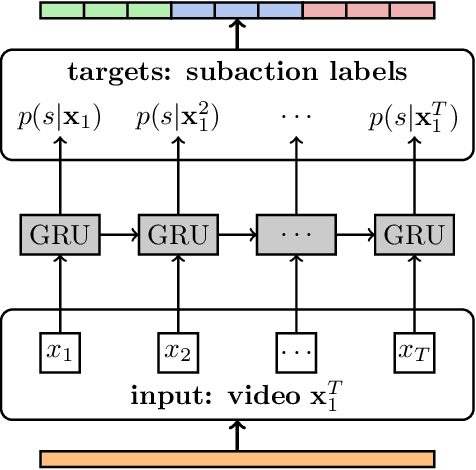
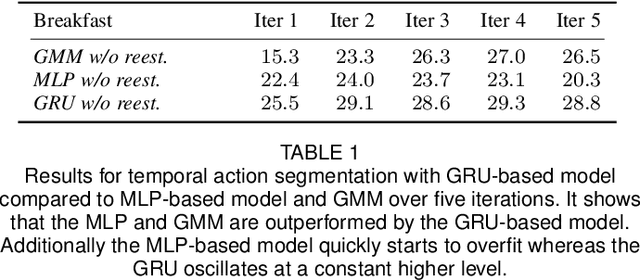

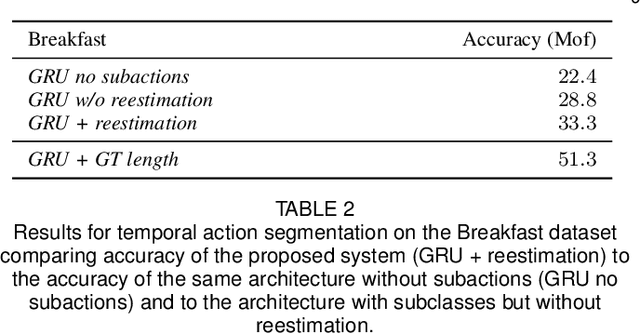
Action recognition has become a rapidly developing research field within the last decade. But with the increasing demand for large scale data, the need of hand annotated data for the training becomes more and more impractical. One way to avoid frame-based human annotation is the use of action order information to learn the respective action classes. In this context, we propose a hierarchical approach to address the problem of weakly supervised learning of human actions from ordered action labels by structuring recognition in a coarse-to-fine manner. Given a set of videos and an ordered list of the occurring actions, the task is to infer start and end frames of the related action classes within the video and to train the respective action classifiers without any need for hand labeled frame boundaries. We address this problem by combining a framewise RNN model with a coarse probabilistic inference. This combination allows for the temporal alignment of long sequences and thus, for an iterative training of both elements. While this system alone already generates good results, we show that the performance can be further improved by approximating the number of subactions to the characteristics of the different action classes as well as by the introduction of a regularizing length prior. The proposed system is evaluated on two benchmark datasets, the Breakfast and the Hollywood extended dataset, showing a competitive performance on various weak learning tasks such as temporal action segmentation and action alignment.
Mining YouTube - A dataset for learning fine-grained action concepts from webly supervised video data
Jun 03, 2019
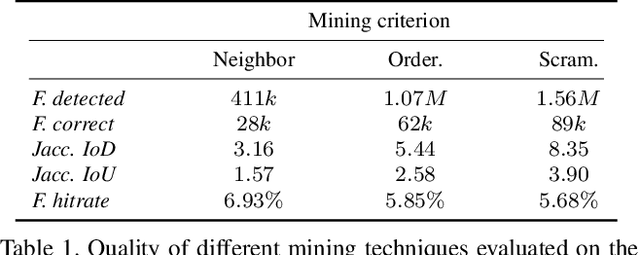

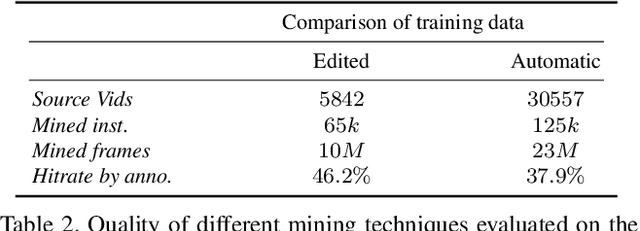
Action recognition is so far mainly focusing on the problem of classification of hand selected preclipped actions and reaching impressive results in this field. But with the performance even ceiling on current datasets, it also appears that the next steps in the field will have to go beyond this fully supervised classification. One way to overcome those problems is to move towards less restricted scenarios. In this context we present a large-scale real-world dataset designed to evaluate learning techniques for human action recognition beyond hand-crafted datasets. To this end we put the process of collecting data on its feet again and start with the annotation of a test set of 250 cooking videos. The training data is then gathered by searching for the respective annotated classes within the subtitles of freely available videos. The uniqueness of the dataset is attributed to the fact that the whole process of collecting the data and training does not involve any human intervention. To address the problem of semantic inconsistencies that arise with this kind of training data, we further propose a semantical hierarchical structure for the mined classes.
Harvesting Information from Captions for Weakly Supervised Semantic Segmentation
May 16, 2019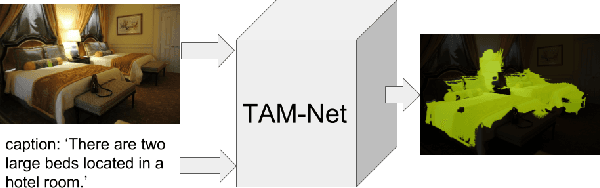
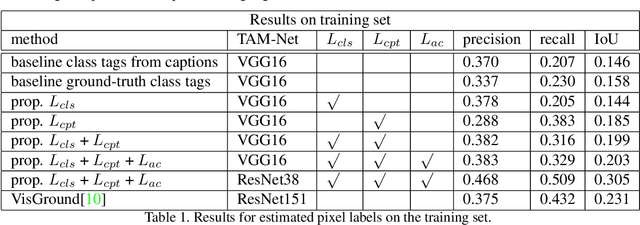
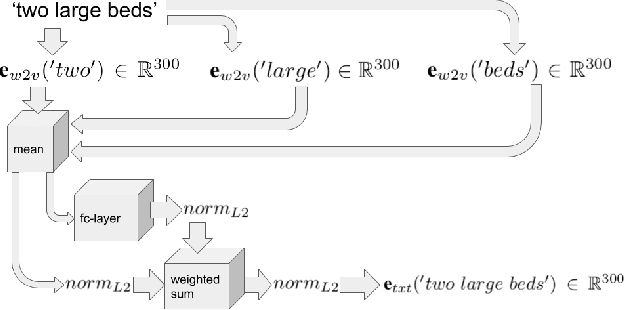

Since acquiring pixel-wise annotations for training convolutional neural networks for semantic image segmentation is time-consuming, weakly supervised approaches that only require class tags have been proposed. In this work, we propose another form of supervision, namely image captions as they can be found on the Internet. These captions have two advantages. They do not require additional curation as it is the case for the clean class tags used by current weakly supervised approaches and they provide textual context for the classes present in an image. To leverage such textual context, we deploy a multi-modal network that learns a joint embedding of the visual representation of the image and the textual representation of the caption. The network estimates text activation maps (TAMs) for class names as well as compound concepts, i.e. combinations of nouns and their attributes. The TAMs of compound concepts describing classes of interest substantially improve the quality of the estimated class activation maps which are then used to train a network for semantic segmentation. We evaluate our method on the COCO dataset where it achieves state of the art results for weakly supervised image segmentation.
3D Semantic Scene Completion from a Single Depth Image using Adversarial Training
May 15, 2019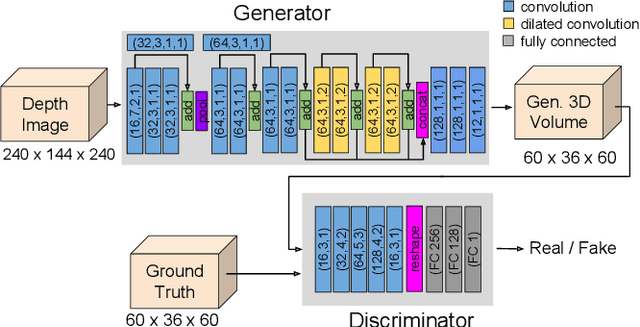
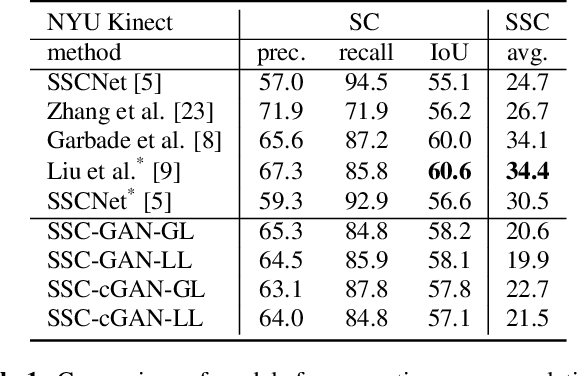
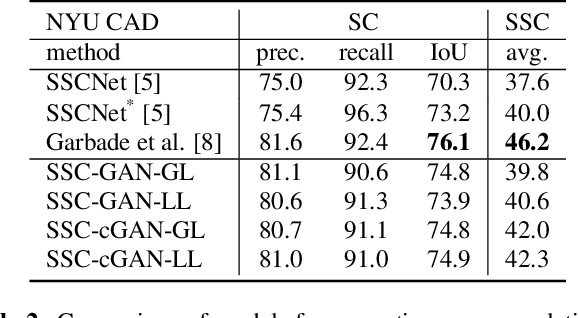

We address the task of 3D semantic scene completion, i.e. , given a single depth image, we predict the semantic labels and occupancy of voxels in a 3D grid representing the scene. In light of the recently introduced generative adversarial networks (GAN), our goal is to explore the potential of this model and the efficiency of various important design choices. Our results show that using conditional GANs outperforms the vanilla GAN setup. We evaluate these architecture designs on several datasets. Based on our experiments, we demonstrate that GANs are able to outperform the performance of a baseline 3D CNN in case of clean annotations, but they suffer from poorly aligned annotations.
Unifying Part Detection and Association for Recurrent Multi-Person Pose Estimation
Apr 26, 2019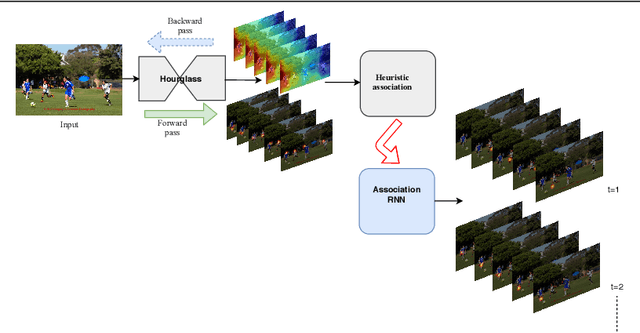
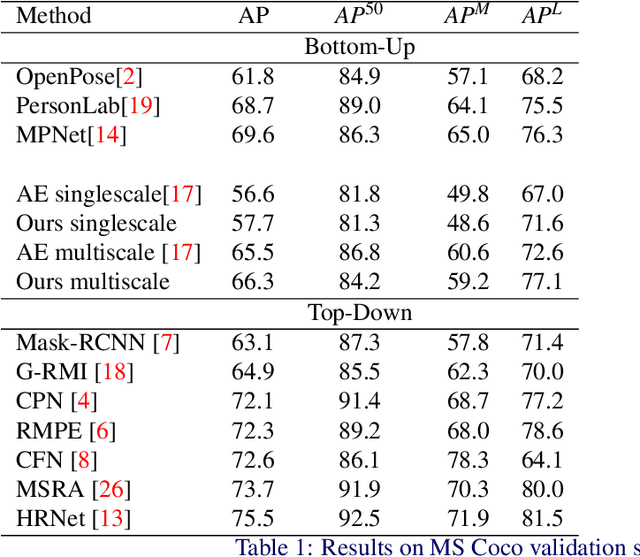


We propose a joint model of human joint detection and association for 2D multi-person pose estimation (MPPE). The approach unifies training of joint detection and association without a need for further processing or sophisticated heuristics in order to associate the joints with people individually. The approach consists of two stages, where in the first stage joint detection heatmaps and association features are extracted, and in the second stage, whose input are the extracted features of the first stage, we introduce a recurrent neural network (RNN) which predicts the heatmaps of a single person's joints in each iteration. In addition, the network learns a stopping criterion in order to halt once it has identified all individuals in the image. This approach allowed us to eliminate several heuristic assumptions and parameters needed for association which do not necessarily hold true. Additionally, such an end-to-end approach allows the final objective to be known and directly optimized over during training. We evaluated our model on the challenging MSCOCO dataset and obtained an improvement over the baseline, particularly in challenging scenes with occlusions.
Unsupervised learning of action classes with continuous temporal embedding
Apr 08, 2019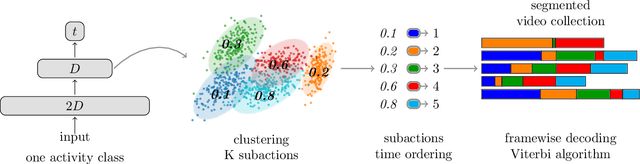


The task of temporally detecting and segmenting actions in untrimmed videos has seen an increased attention recently. One problem in this context arises from the need to define and label action boundaries to create annotations for training which is very time and cost intensive. To address this issue, we propose an unsupervised approach for learning action classes from untrimmed video sequences. To this end, we use a continuous temporal embedding of framewise features to benefit from the sequential nature of activities. Based on the latent space created by the embedding, we identify clusters of temporal segments across all videos that correspond to semantic meaningful action classes. The approach is evaluated on three challenging datasets, namely the Breakfast dataset, YouTube Instructions, and the 50Salads dataset. While previous works assumed that the videos contain the same high level activity, we furthermore show that the proposed approach can also be applied to a more general setting where the content of the videos is unknown.
Weakly Supervised Action Segmentation Using Mutual Consistency
Apr 05, 2019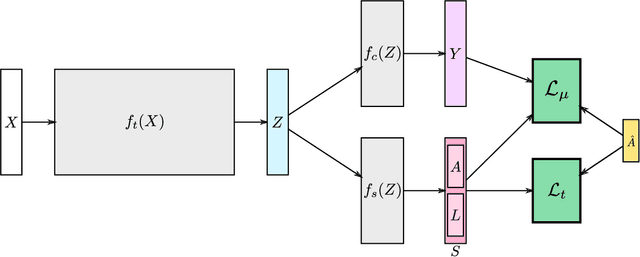

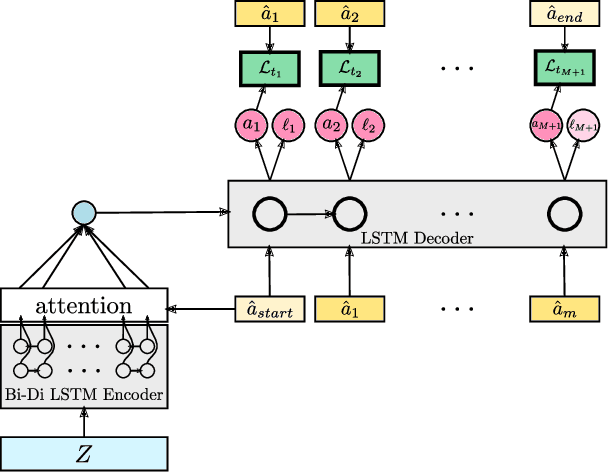
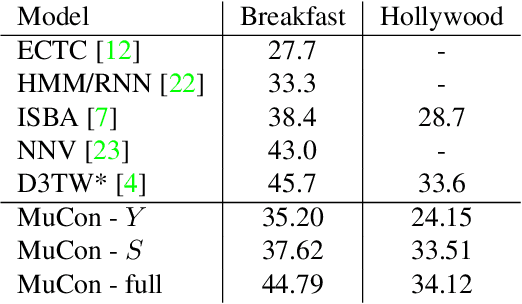
Action segmentation is the task of predicting the actions in each frame of a video. Because of the high cost of preparing training videos with full supervision for action segmentation, weakly supervised approaches which are able to learn only from transcripts are very appealing. In this paper, we propose a new approach for weakly supervised action segmentation based on a two branch network. The two branches of our network predict two redundant but different representations for action segmentation. During training we introduce a new mutual consistency loss (MuCon) that enforces that these two representations are consistent. Using MuCon and a transcript prediction loss, our network achieves state-of-the-art results for action segmentation and action alignment while being fully differentiable and faster to train since it does not require a costly alignment step during training.
What Object Should I Use? - Task Driven Object Detection
Apr 05, 2019
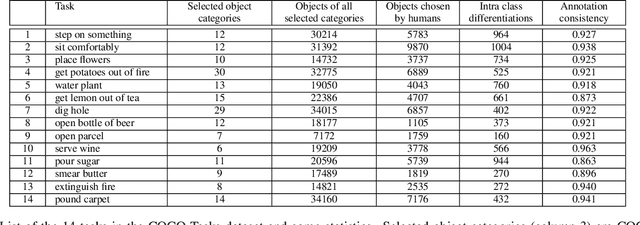

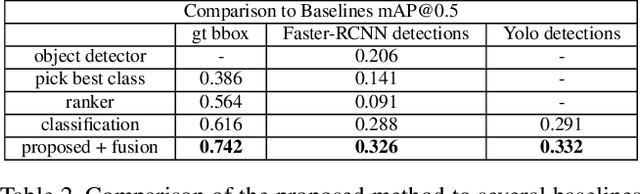
When humans have to solve everyday tasks, they simply pick the objects that are most suitable. While the question which object should one use for a specific task sounds trivial for humans, it is very difficult to answer for robots or other autonomous systems. This issue, however, is not addressed by current benchmarks for object detection that focus on detecting object categories. We therefore introduce the COCO-Tasks dataset which comprises about 40,000 images where the most suitable objects for 14 tasks have been annotated. We furthermore propose an approach that detects the most suitable objects for a given task. The approach builds on a Gated Graph Neural Network to exploit the appearance of each object as well as the global context of all present objects in the scene. In our experiments, we show that the proposed approach outperforms other approaches that are evaluated on the dataset like classification or ranking approaches.
MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation
Apr 02, 2019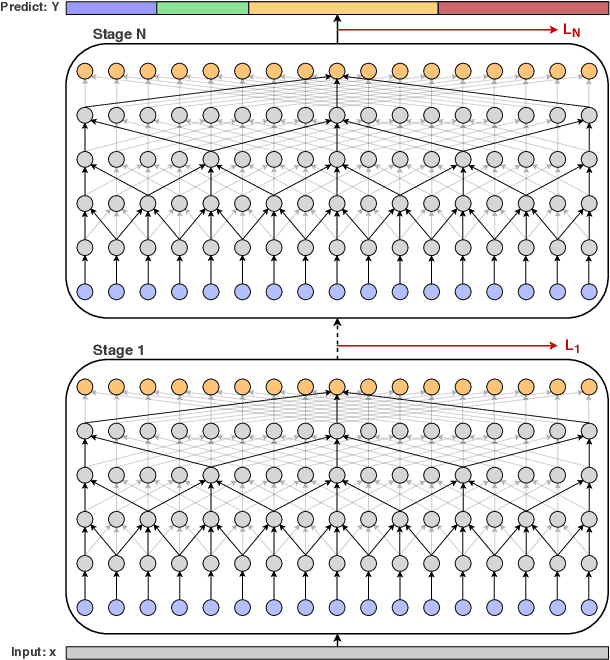
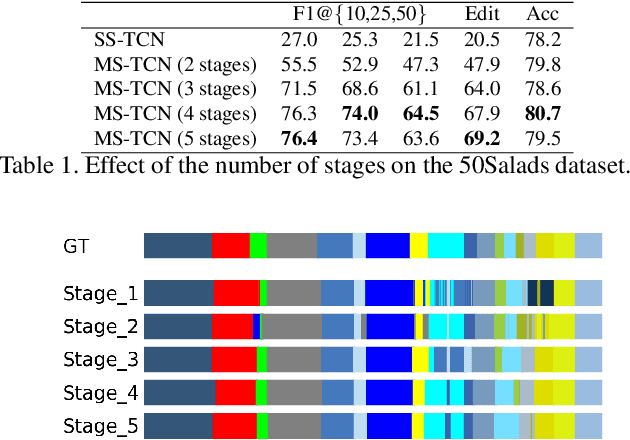
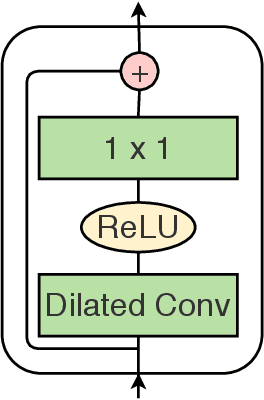

Temporally locating and classifying action segments in long untrimmed videos is of particular interest to many applications like surveillance and robotics. While traditional approaches follow a two-step pipeline, by generating frame-wise probabilities and then feeding them to high-level temporal models, recent approaches use temporal convolutions to directly classify the video frames. In this paper, we introduce a multi-stage architecture for the temporal action segmentation task. Each stage features a set of dilated temporal convolutions to generate an initial prediction that is refined by the next one. This architecture is trained using a combination of a classification loss and a proposed smoothing loss that penalizes over-segmentation errors. Extensive evaluation shows the effectiveness of the proposed model in capturing long-range dependencies and recognizing action segments. Our model achieves state-of-the-art results on three challenging datasets: 50Salads, Georgia Tech Egocentric Activities (GTEA), and the Breakfast dataset.