 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Set Domain Adaptation for Image and Action Recognition
Jul 30, 2019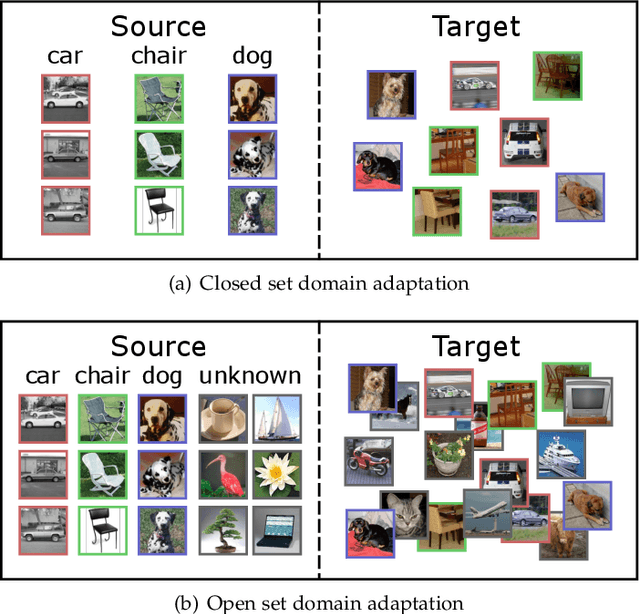
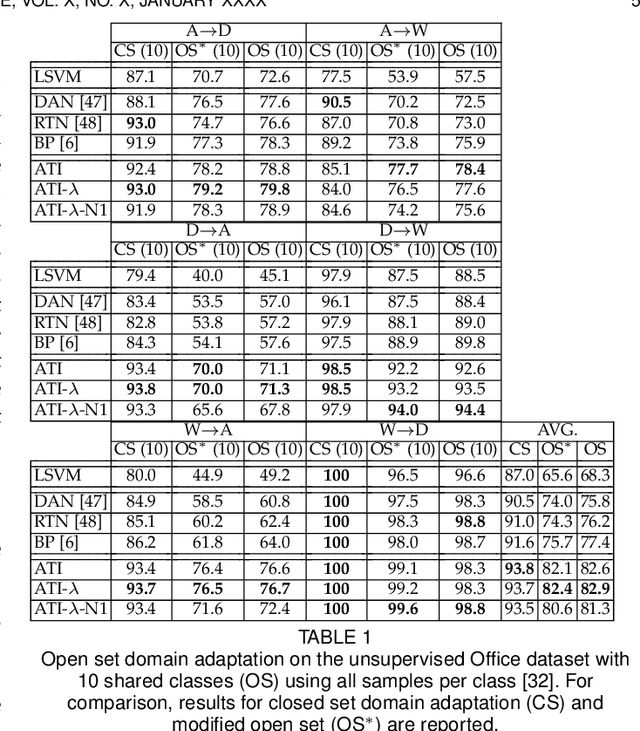
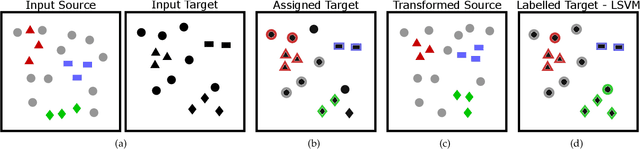

Since annotating and curating large datasets is very expensive, there is a need to transfer the knowledge from existing annotated datasets to unlabelled data. Data that is relevant for a specific application, however, usually differs from publicly available datasets since it is sampled from a different domain. While domain adaptation methods compensate for such a domain shift, they assume that all categories in the target domain are known and match the categories in the source domain. Since this assumption is violated under real-world conditions, we propose an approach for open set domain adaptation where the target domain contains instances of categories that are not present in the source domain. The proposed approach achieves state-of-the-art results on various datasets for image classification and action recognition. Since the approach can be used for open set and closed set domain adaptation, as well as unsupervised and semi-supervised domain adaptation, it is a versatile tool for many applications.
Mining YouTube - A dataset for learning fine-grained action concepts from webly supervised video data
Jun 03, 2019
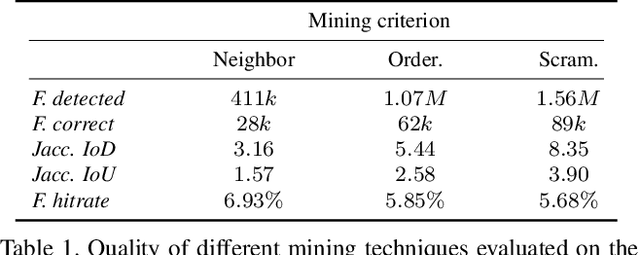

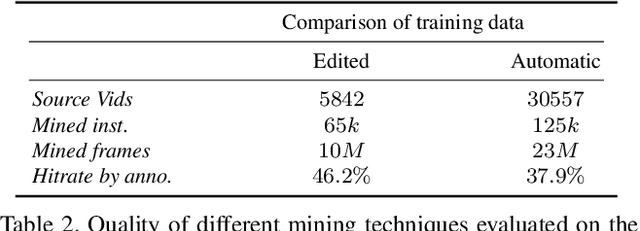
Action recognition is so far mainly focusing on the problem of classification of hand selected preclipped actions and reaching impressive results in this field. But with the performance even ceiling on current datasets, it also appears that the next steps in the field will have to go beyond this fully supervised classification. One way to overcome those problems is to move towards less restricted scenarios. In this context we present a large-scale real-world dataset designed to evaluate learning techniques for human action recognition beyond hand-crafted datasets. To this end we put the process of collecting data on its feet again and start with the annotation of a test set of 250 cooking videos. The training data is then gathered by searching for the respective annotated classes within the subtitles of freely available videos. The uniqueness of the dataset is attributed to the fact that the whole process of collecting the data and training does not involve any human intervention. To address the problem of semantic inconsistencies that arise with this kind of training data, we further propose a semantical hierarchical structure for the mined classes.
NeuralNetwork-Viterbi: A Framework for Weakly Supervised Video Learning
May 17, 2018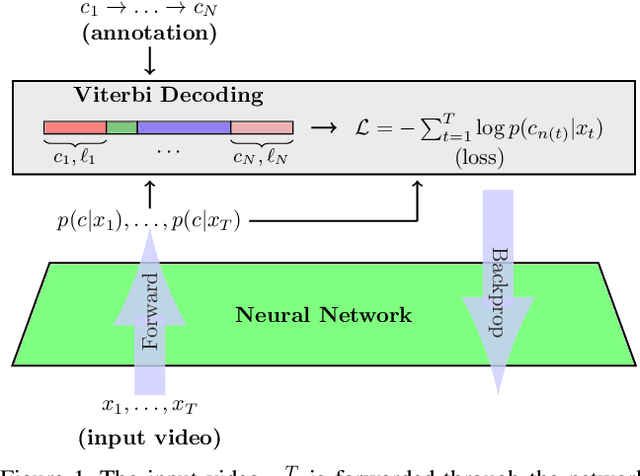

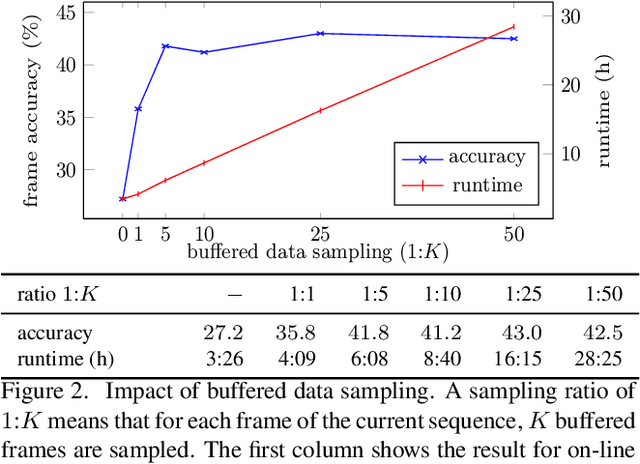

Video learning is an important task in computer vision and has experienced increasing interest over the recent years. Since even a small amount of videos easily comprises several million frames, methods that do not rely on a frame-level annotation are of special importance. In this work, we propose a novel learning algorithm with a Viterbi-based loss that allows for online and incremental learning of weakly annotated video data. We moreover show that explicit context and length modeling leads to huge improvements in video segmentation and labeling tasks andinclude these models into our framework. On several action segmentation benchmarks, we obtain an improvement of up to 10% compared to current state-of-the-art methods.
Recurrent Residual Learning for Action Recognition
Jun 27, 2017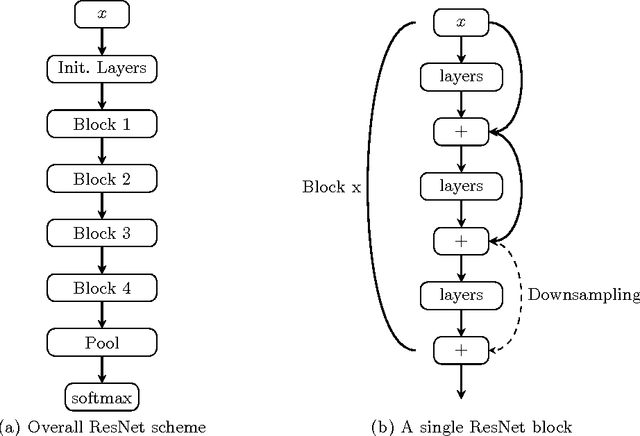


Action recognition is a fundamental problem in computer vision with a lot of potential applications such as video surveillance, human computer interaction, and robot learning. Given pre-segmented videos, the task is to recognize actions happening within videos. Historically, hand crafted video features were used to address the task of action recognition. With the success of Deep ConvNets as an image analysis method, a lot of extensions of standard ConvNets were purposed to process variable length video data. In this work, we propose a novel recurrent ConvNet architecture called recurrent residual networks to address the task of action recognition. The approach extends ResNet, a state of the art model for image classification. While the original formulation of ResNet aims at learning spatial residuals in its layers, we extend the approach by introducing recurrent connections that allow to learn a spatio-temporal residual. In contrast to fully recurrent networks, our temporal connections only allow a limited range of preceding frames to contribute to the output for the current frame, enabling efficient training and inference as well as limiting the temporal context to a reasonable local range around each frame. On a large-scale action recognition dataset, we show that our model improves over both, the standard ResNet architecture and a ResNet extended by a fully recurrent layer.