 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Aggregation R-CNN for 2D Multi-person Pose Estimation
May 10, 2019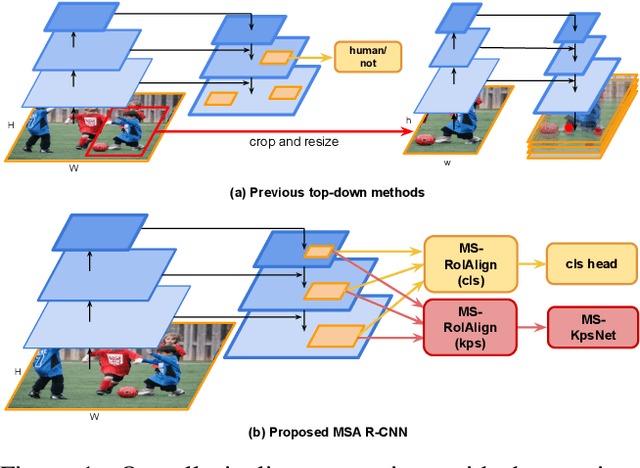
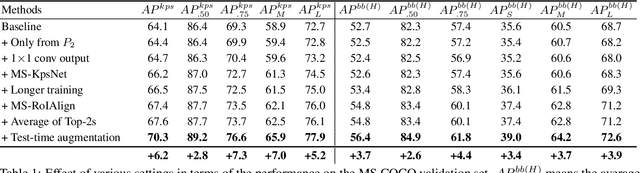
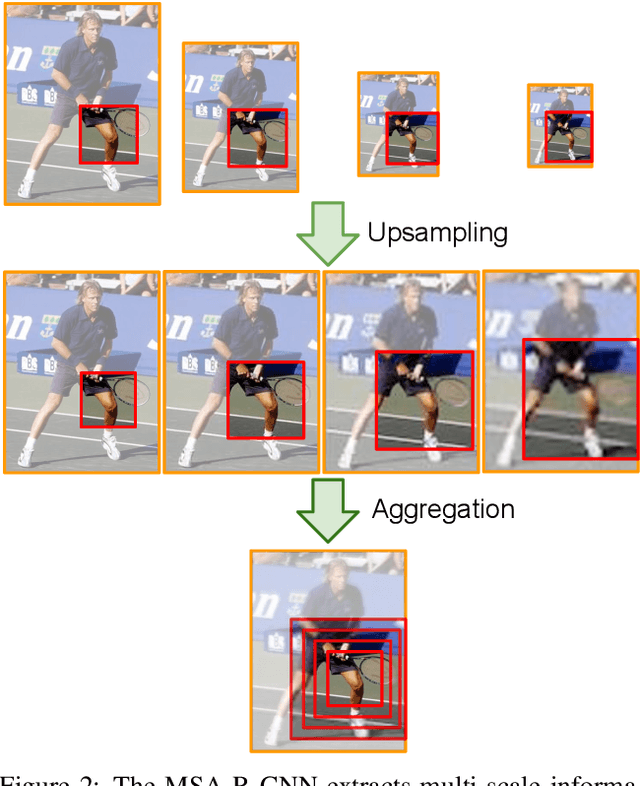
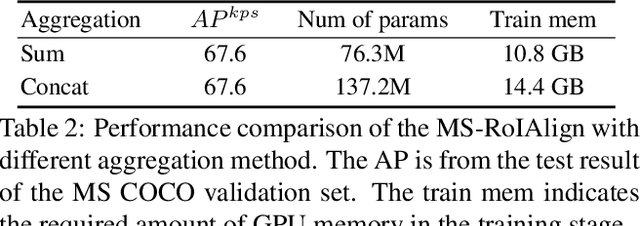
Multi-person pose estimation from a 2D image is challenging because it requires not only keypoint localization but also human detection. In state-of-the-art top-down methods, multi-scale information is a crucial factor for the accurate pose estimation because it contains both of local information around the keypoints and global information of the entire person. Although multi-scale information allows these methods to achieve the state-of-the-art performance, the top-down methods still require a huge amount of computation because they need to use an additional human detector to feed the cropped human image to their pose estimation model. To effectively utilize multi-scale information with the smaller computation, we propose a multi-scale aggregation R-CNN (MSA R-CNN). It consists of multi-scale RoIAlign block (MS-RoIAlign) and multi-scale keypoint head network (MS-KpsNet) which are designed to effectively utilize multi-scale information. Also, in contrast to previous top-down methods, the MSA R-CNN performs human detection and keypoint localization in a single model, which results in reduced computation. The proposed model achieved the best performance among single model-based methods and its results are comparable to those of separated model-based methods with a smaller amount of computation on the publicly available 2D multi-person keypoint localization dataset.
PoseFix: Model-agnostic General Human Pose Refinement Network
Dec 10, 2018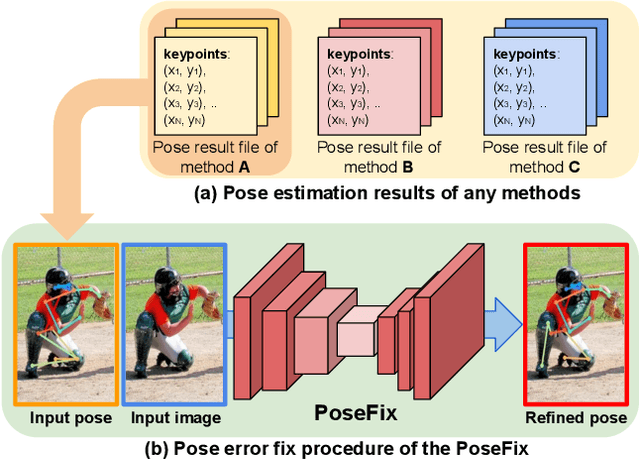

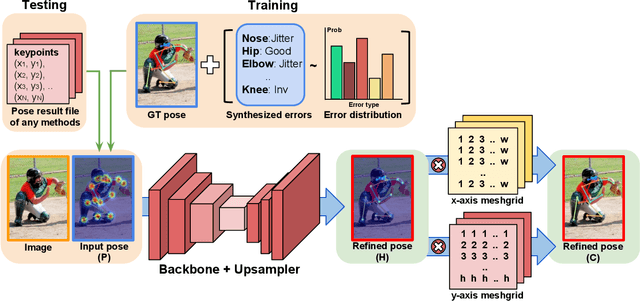
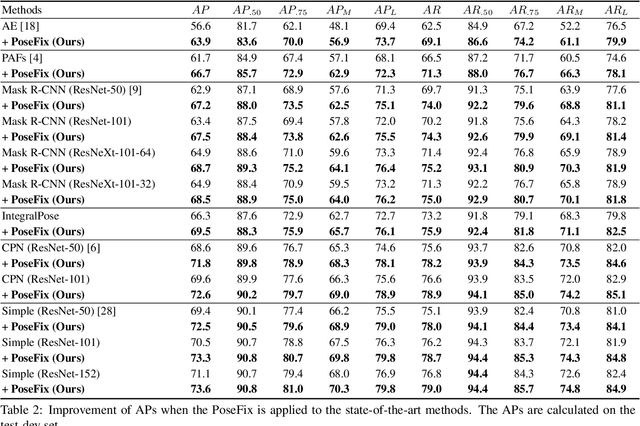
Multi-person pose estimation from a 2D image is an essential technique for human behavior understanding. In this paper, we propose a human pose refinement network that estimates a refined pose from a tuple of an input image and input pose. The pose refinement was performed mainly through an end-to-end trainable multi-stage architecture in previous methods. However, they are highly dependent on pose estimation models and require careful model design. By contrast, we propose a model-agnostic pose refinement method. According to a recent study, state-of-the-art 2D human pose estimation methods have similar error distributions. We use this error statistics as prior information to generate synthetic poses and use the synthesized poses to train our model. In the testing stage, pose estimation results of any other methods can be input to the proposed method. Moreover, the proposed model does not require code or knowledge about other methods, which allows it to be easily used in the post-processing step. We show that the proposed approach achieves better performance than the conventional multi-stage refinement models and consistently improves the performance of various state-of-the-art pose estimation methods on the commonly used benchmark. We will release the code and pre-trained model for easy access.
V2V-PoseNet: Voxel-to-Voxel Prediction Network for Accurate 3D Hand and Human Pose Estimation from a Single Depth Map
Aug 16, 2018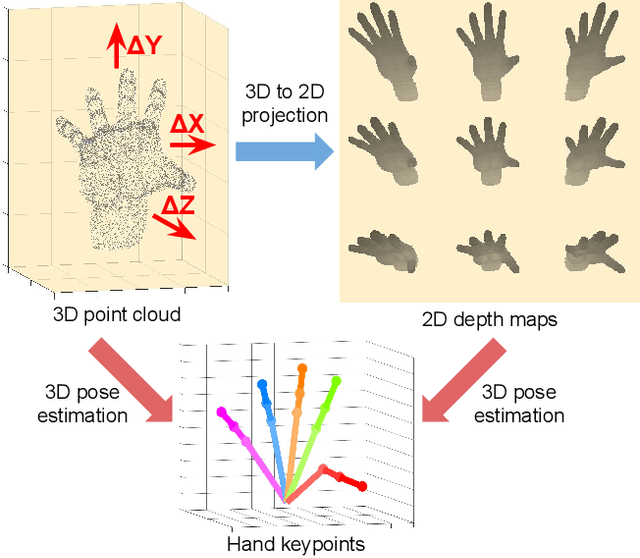



Most of the existing deep learning-based methods for 3D hand and human pose estimation from a single depth map are based on a common framework that takes a 2D depth map and directly regresses the 3D coordinates of keypoints, such as hand or human body joints, via 2D convolutional neural networks (CNNs). The first weakness of this approach is the presence of perspective distortion in the 2D depth map. While the depth map is intrinsically 3D data, many previous methods treat depth maps as 2D images that can distort the shape of the actual object through projection from 3D to 2D space. This compels the network to perform perspective distortion-invariant estimation. The second weakness of the conventional approach is that directly regressing 3D coordinates from a 2D image is a highly non-linear mapping, which causes difficulty in the learning procedure. To overcome these weaknesses, we firstly cast the 3D hand and human pose estimation problem from a single depth map into a voxel-to-voxel prediction that uses a 3D voxelized grid and estimates the per-voxel likelihood for each keypoint. We design our model as a 3D CNN that provides accurate estimates while running in real-time. Our system outperforms previous methods in almost all publicly available 3D hand and human pose estimation datasets and placed first in the HANDS 2017 frame-based 3D hand pose estimation challenge. The code is available in https://github.com/mks0601/V2V-PoseNet_RELEASE.
Depth-Based 3D Hand Pose Estimation: From Current Achievements to Future Goals
Mar 29, 2018
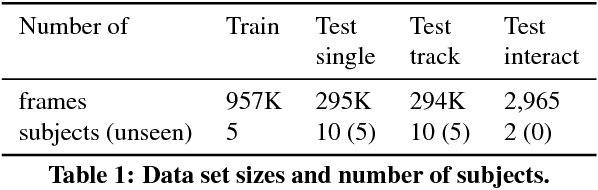
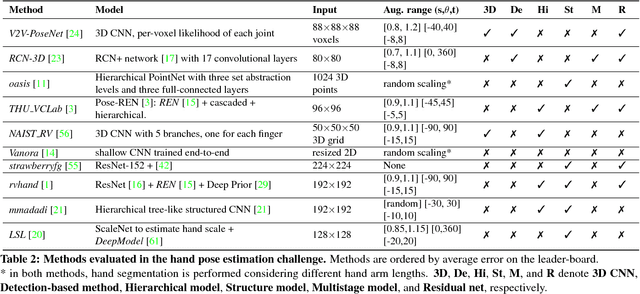
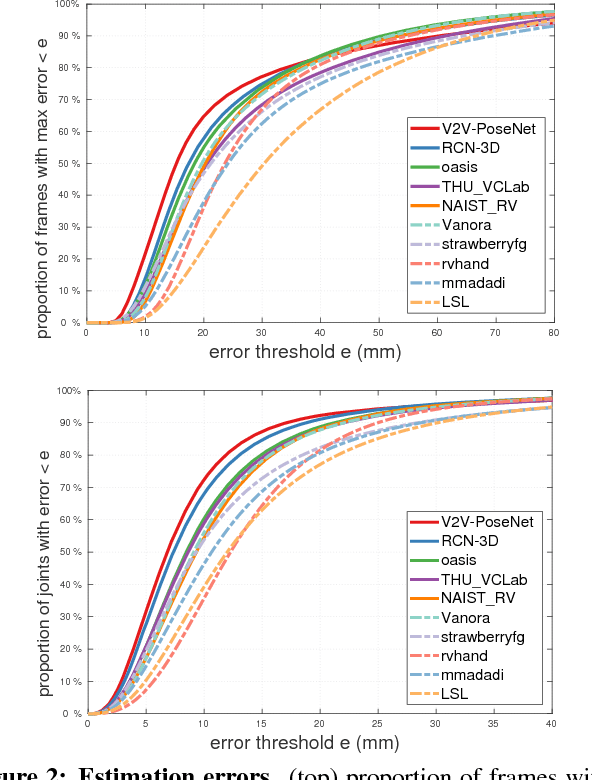
In this paper, we strive to answer two questions: What is the current state of 3D hand pose estimation from depth images? And, what are the next challenges that need to be tackled? Following the successful Hands In the Million Challenge (HIM2017), we investigate the top 10 state-of-the-art methods on three tasks: single frame 3D pose estimation, 3D hand tracking, and hand pose estimation during object interaction. We analyze the performance of different CNN structures with regard to hand shape, joint visibility, view point and articulation distributions. Our findings include: (1) isolated 3D hand pose estimation achieves low mean errors (10 mm) in the view point range of [70, 120] degrees, but it is far from being solved for extreme view points; (2) 3D volumetric representations outperform 2D CNNs, better capturing the spatial structure of the depth data; (3) Discriminative methods still generalize poorly to unseen hand shapes; (4) While joint occlusions pose a challenge for most methods, explicit modeling of structure constraints can significantly narrow the gap between errors on visible and occluded joints.
2D-3D Pose Consistency-based Conditional Random Fields for 3D Human Pose Estimation
Dec 28, 2017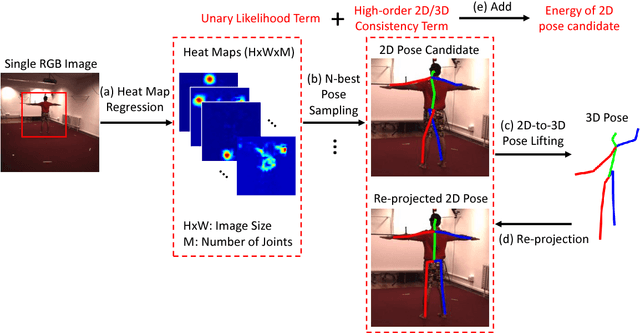

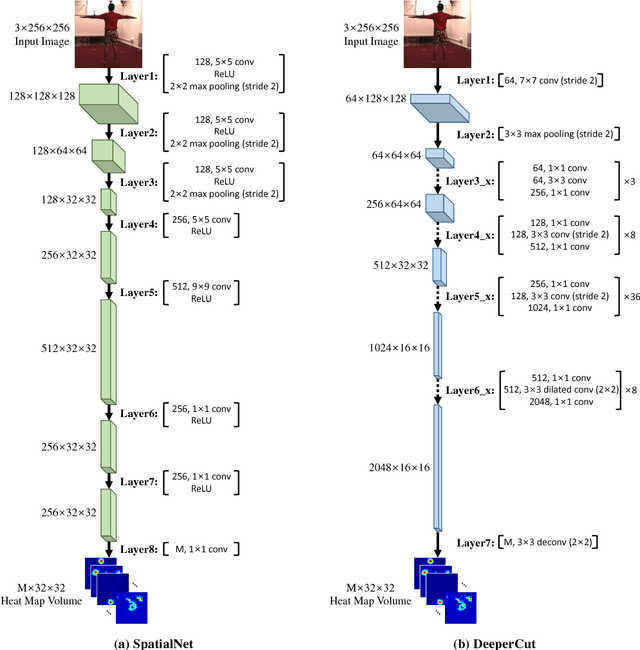
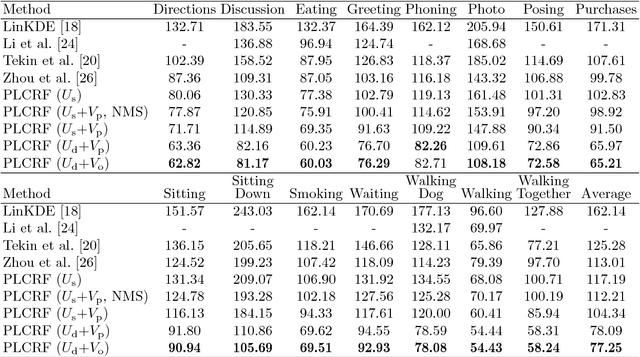
This study considers the 3D human pose estimation problem in a single RGB image by proposing a conditional random field (CRF) model over 2D poses, in which the 3D pose is obtained as a byproduct of the inference process. The unary term of the proposed CRF model is defined based on a powerful heat-map regression network, which has been proposed for 2D human pose estimation. This study also presents a regression network for lifting the 2D pose to 3D pose and proposes the prior term based on the consistency between the estimated 3D pose and the 2D pose. To obtain the approximate solution of the proposed CRF model, the N-best strategy is adopted. The proposed inference algorithm can be viewed as sequential processes of bottom-up generation of 2D and 3D pose proposals from the input 2D image based on deep networks and top-down verification of such proposals by checking their consistencies. To evaluate the proposed method, we use two large-scale datasets: Human3.6M and HumanEva. Experimental results show that the proposed method achieves the state-of-the-art 3D human pose estimation performance.
Holistic Planimetric prediction to Local Volumetric prediction for 3D Human Pose Estimation
Jul 08, 2017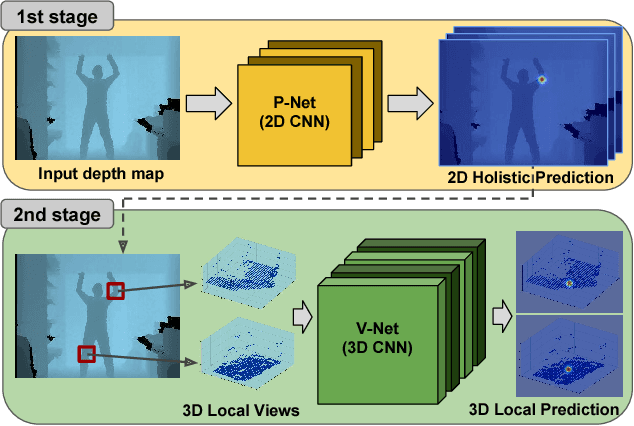
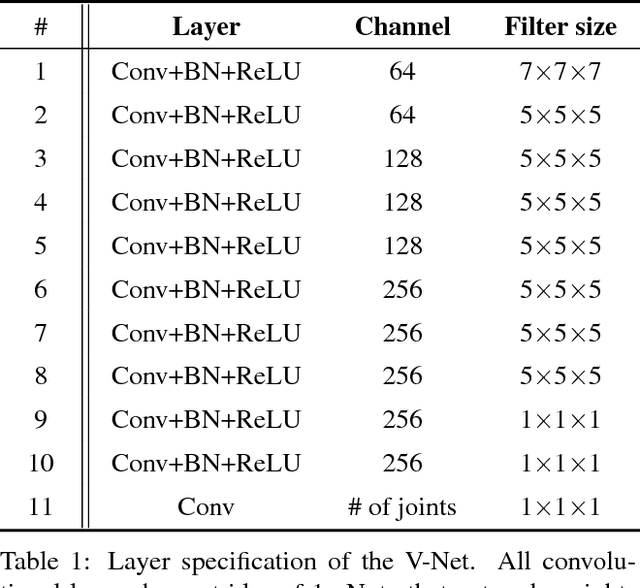
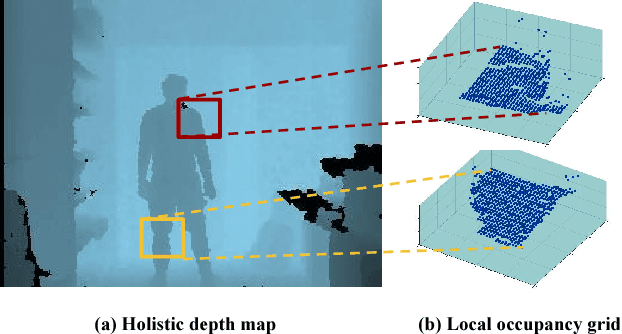

We propose a novel approach to 3D human pose estimation from a single depth map. Recently, convolutional neural network (CNN) has become a powerful paradigm in computer vision. Many of computer vision tasks have benefited from CNNs, however, the conventional approach to directly regress 3D body joint locations from an image does not yield a noticeably improved performance. In contrast, we formulate the problem as estimating per-voxel likelihood of key body joints from a 3D occupancy grid. We argue that learning a mapping from volumetric input to volumetric output with 3D convolution consistently improves the accuracy when compared to learning a regression from depth map to 3D joint coordinates. We propose a two-stage approach to reduce the computational overhead caused by volumetric representation and 3D convolution: Holistic 2D prediction and Local 3D prediction. In the first stage, Planimetric Network (P-Net) estimates per-pixel likelihood for each body joint in the holistic 2D space. In the second stage, Volumetric Network (V-Net) estimates the per-voxel likelihood of each body joints in the local 3D space around the 2D estimations of the first stage, effectively reducing the computational cost. Our model outperforms existing methods by a large margin in publicly available datasets.