 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Bayesian Factor Analysis for Dynamic Count Matrices
Dec 30, 2015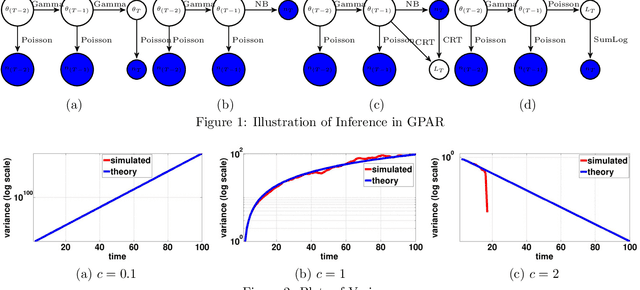
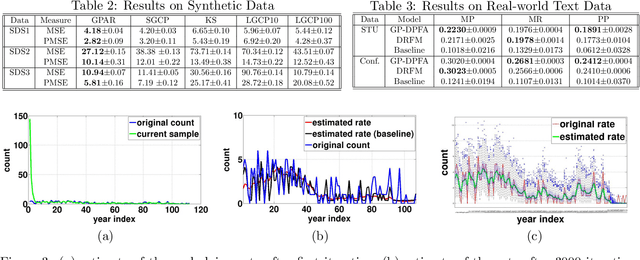
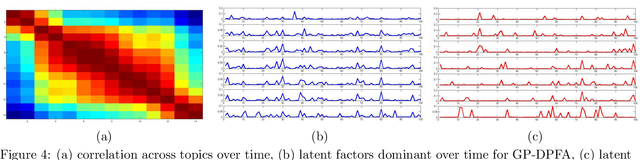

A gamma process dynamic Poisson factor analysis model is proposed to factorize a dynamic count matrix, whose columns are sequentially observed count vectors. The model builds a novel Markov chain that sends the latent gamma random variables at time $(t-1)$ as the shape parameters of those at time $t$, which are linked to observed or latent counts under the Poisson likelihood. The significant challenge of inferring the gamma shape parameters is fully addressed, using unique data augmentation and marginalization techniques for the negative binomial distribution. The same nonparametric Bayesian model also applies to the factorization of a dynamic binary matrix, via a Bernoulli-Poisson link that connects a binary observation to a latent count, with closed-form conditional posteriors for the latent counts and efficient computation for sparse observations. We apply the model to text and music analysis, with state-of-the-art results.
Exponential Family Matrix Completion under Structural Constraints
Sep 15, 2015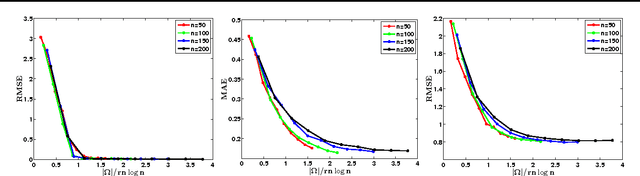
We consider the matrix completion problem of recovering a structured matrix from noisy and partial measurements. Recent works have proposed tractable estimators with strong statistical guarantees for the case where the underlying matrix is low--rank, and the measurements consist of a subset, either of the exact individual entries, or of the entries perturbed by additive Gaussian noise, which is thus implicitly suited for thin--tailed continuous data. Arguably, common applications of matrix completion require estimators for (a) heterogeneous data--types, such as skewed--continuous, count, binary, etc., (b) for heterogeneous noise models (beyond Gaussian), which capture varied uncertainty in the measurements, and (c) heterogeneous structural constraints beyond low--rank, such as block--sparsity, or a superposition structure of low--rank plus elementwise sparseness, among others. In this paper, we provide a vastly unified framework for generalized matrix completion by considering a matrix completion setting wherein the matrix entries are sampled from any member of the rich family of exponential family distributions; and impose general structural constraints on the underlying matrix, as captured by a general regularizer $\mathcal{R}(.)$. We propose a simple convex regularized $M$--estimator for the generalized framework, and provide a unified and novel statistical analysis for this general class of estimators. We finally corroborate our theoretical results on simulated datasets.
* 20 pages, 9 figures
A Constrained Matrix-Variate Gaussian Process for Transposable Data
Apr 27, 2014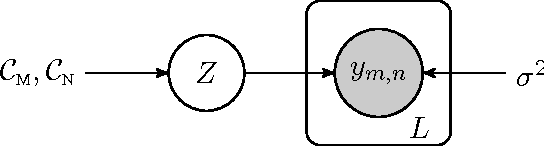
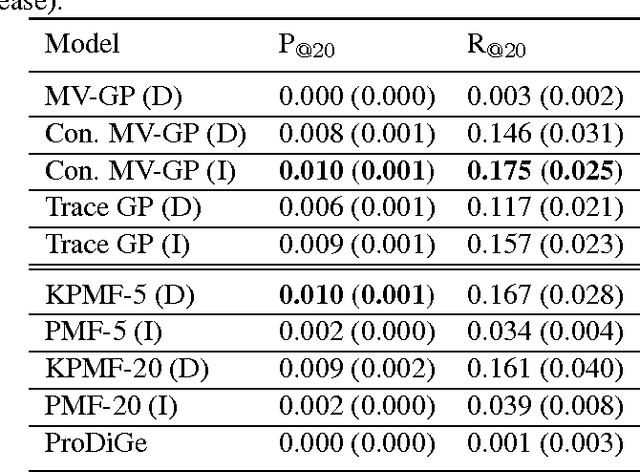
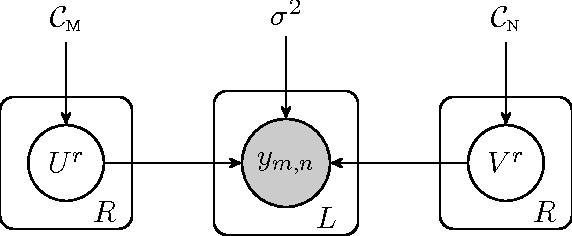
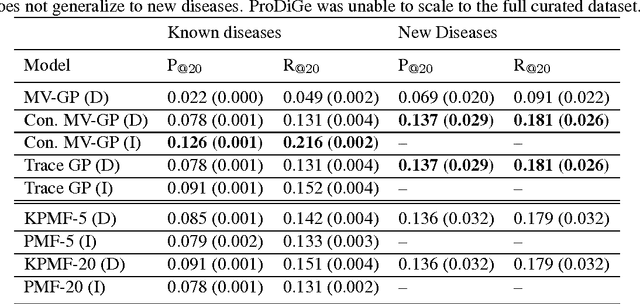
Transposable data represents interactions among two sets of entities, and are typically represented as a matrix containing the known interaction values. Additional side information may consist of feature vectors specific to entities corresponding to the rows and/or columns of such a matrix. Further information may also be available in the form of interactions or hierarchies among entities along the same mode (axis). We propose a novel approach for modeling transposable data with missing interactions given additional side information. The interactions are modeled as noisy observations from a latent noise free matrix generated from a matrix-variate Gaussian process. The construction of row and column covariances using side information provides a flexible mechanism for specifying a-priori knowledge of the row and column correlations in the data. Further, the use of such a prior combined with the side information enables predictions for new rows and columns not observed in the training data. In this work, we combine the matrix-variate Gaussian process model with low rank constraints. The constrained Gaussian process approach is applied to the prediction of hidden associations between genes and diseases using a small set of observed associations as well as prior covariances induced by gene-gene interaction networks and disease ontologies. The proposed approach is also applied to recommender systems data which involves predicting the item ratings of users using known associations as well as prior covariances induced by social networks. We present experimental results that highlight the performance of constrained matrix-variate Gaussian process as compared to state of the art approaches in each domain.
Perturbed Gibbs Samplers for Synthetic Data Release
Dec 18, 2013
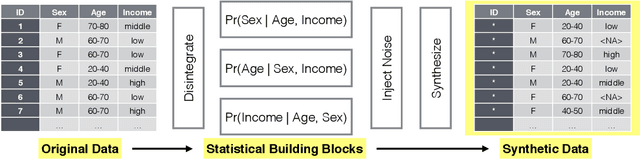


We propose a categorical data synthesizer with a quantifiable disclosure risk. Our algorithm, named Perturbed Gibbs Sampler, can handle high-dimensional categorical data that are often intractable to represent as contingency tables. The algorithm extends a multiple imputation strategy for fully synthetic data by utilizing feature hashing and non-parametric distribution approximations. California Patient Discharge data are used to demonstrate statistical properties of the proposed synthesizing methodology. Marginal and conditional distributions, as well as the coefficients of regression models built on the synthesized data are compared to those obtained from the original data. Intruder scenarios are simulated to evaluate disclosure risks of the synthesized data from multiple angles. Limitations and extensions of the proposed algorithm are also discussed.
Constrained Bayesian Inference for Low Rank Multitask Learning
Sep 26, 2013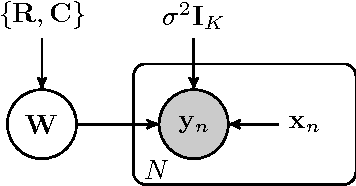
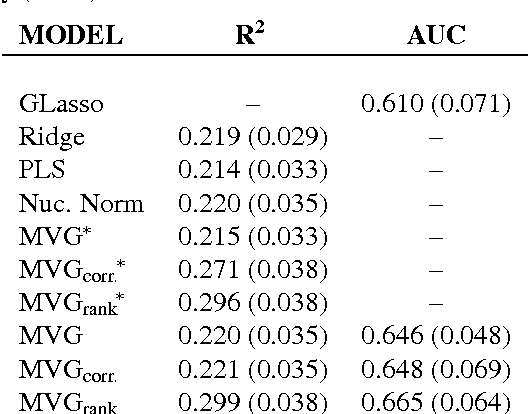

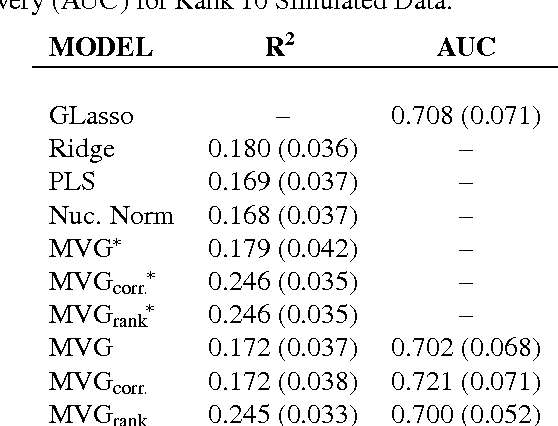
We present a novel approach for constrained Bayesian inference. Unlike current methods, our approach does not require convexity of the constraint set. We reduce the constrained variational inference to a parametric optimization over the feasible set of densities and propose a general recipe for such problems. We apply the proposed constrained Bayesian inference approach to multitask learning subject to rank constraints on the weight matrix. Further, constrained parameter estimation is applied to recover the sparse conditional independence structure encoded by prior precision matrices. Our approach is motivated by reverse inference for high dimensional functional neuroimaging, a domain where the high dimensionality and small number of examples requires the use of constraints to ensure meaningful and effective models. For this application, we propose a model that jointly learns a weight matrix and the prior inverse covariance structure between different tasks. We present experimental validation showing that the proposed approach outperforms strong baseline models in terms of predictive performance and structure recovery.
The trace norm constrained matrix-variate Gaussian process for multitask bipartite ranking
Feb 11, 2013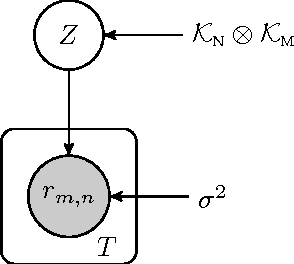
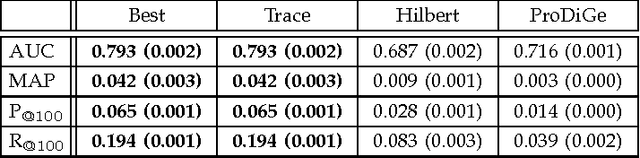
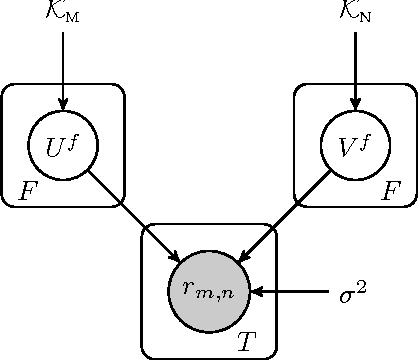
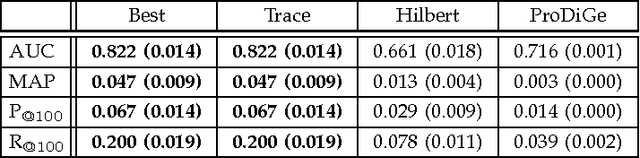
We propose a novel hierarchical model for multitask bipartite ranking. The proposed approach combines a matrix-variate Gaussian process with a generative model for task-wise bipartite ranking. In addition, we employ a novel trace constrained variational inference approach to impose low rank structure on the posterior matrix-variate Gaussian process. The resulting posterior covariance function is derived in closed form, and the posterior mean function is the solution to a matrix-variate regression with a novel spectral elastic net regularizer. Further, we show that variational inference for the trace constrained matrix-variate Gaussian process combined with maximum likelihood parameter estimation for the bipartite ranking model is jointly convex. Our motivating application is the prioritization of candidate disease genes. The goal of this task is to aid the identification of unobserved associations between human genes and diseases using a small set of observed associations as well as kernels induced by gene-gene interaction networks and disease ontologies. Our experimental results illustrate the performance of the proposed model on real world datasets. Moreover, we find that the resulting low rank solution improves the computational scalability of training and testing as compared to baseline models.
Probabilistic Combination of Classifier and Cluster Ensembles for Non-transductive Learning
Nov 10, 2012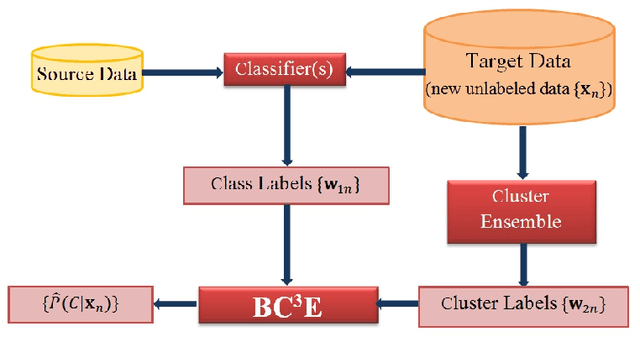

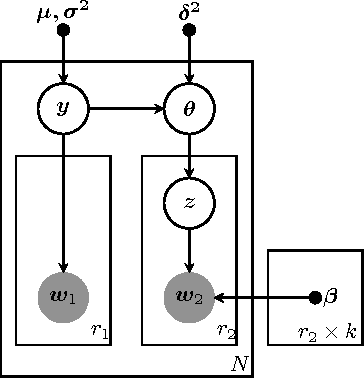
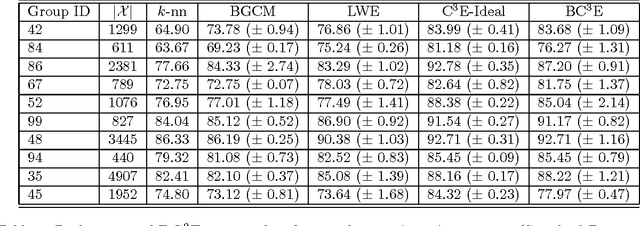
Unsupervised models can provide supplementary soft constraints to help classify new target data under the assumption that similar objects in the target set are more likely to share the same class label. Such models can also help detect possible differences between training and target distributions, which is useful in applications where concept drift may take place. This paper describes a Bayesian framework that takes as input class labels from existing classifiers (designed based on labeled data from the source domain), as well as cluster labels from a cluster ensemble operating solely on the target data to be classified, and yields a consensus labeling of the target data. This framework is particularly useful when the statistics of the target data drift or change from those of the training data. We also show that the proposed framework is privacy-aware and allows performing distributed learning when data/models have sharing restrictions. Experiments show that our framework can yield superior results to those provided by applying classifier ensembles only.
Dating Texts without Explicit Temporal Cues
Nov 10, 2012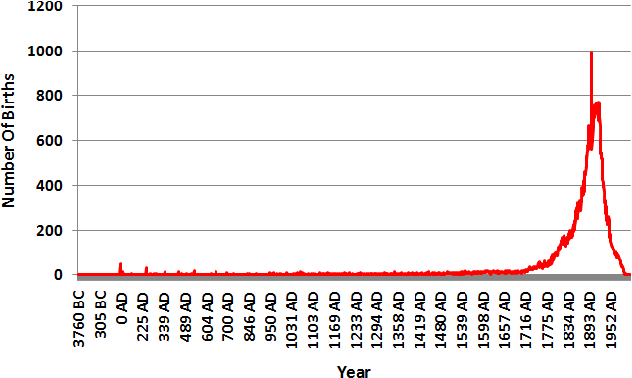

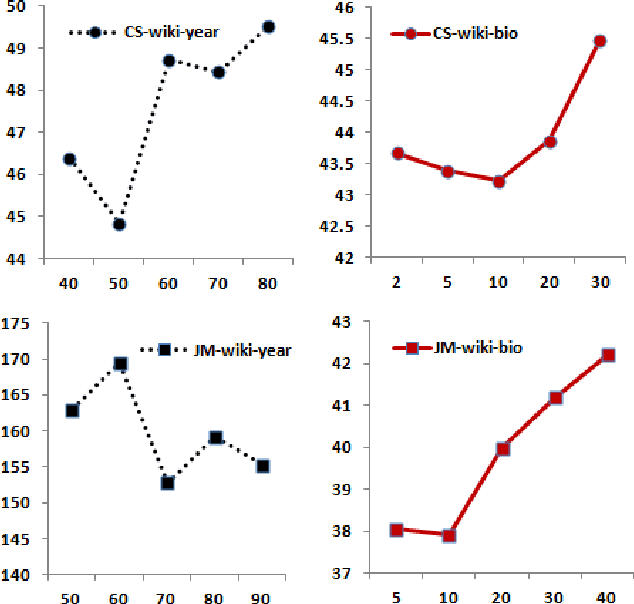
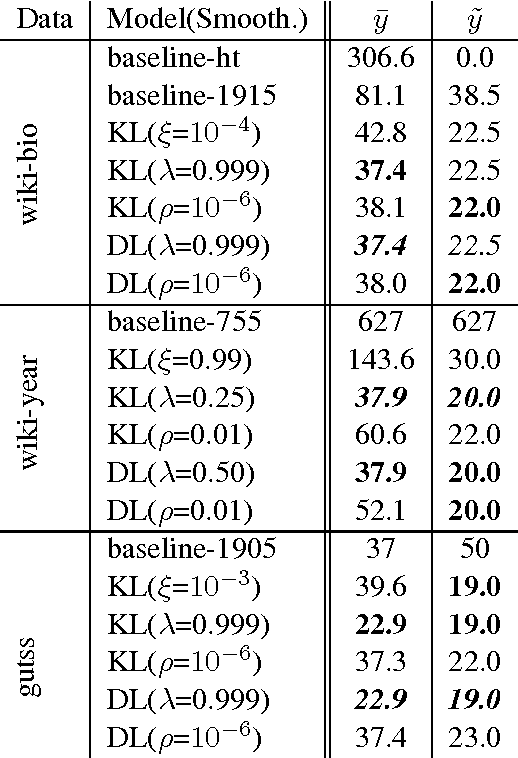
This paper tackles temporal resolution of documents, such as determining when a document is about or when it was written, based only on its text. We apply techniques from information retrieval that predict dates via language models over a discretized timeline. Unlike most previous works, we rely {\it solely} on temporal cues implicit in the text. We consider both document-likelihood and divergence based techniques and several smoothing methods for both of them. Our best model predicts the mid-point of individuals' lives with a median of 22 and mean error of 36 years for Wikipedia biographies from 3800 B.C. to the present day. We also show that this approach works well when training on such biographies and predicting dates both for non-biographical Wikipedia pages about specific years (500 B.C. to 2010 A.D.) and for publication dates of short stories (1798 to 2008). Together, our work shows that, even in absence of temporal extraction resources, it is possible to achieve remarkable temporal locality across a diverse set of texts.
Learning to Rank With Bregman Divergences and Monotone Retargeting
Oct 16, 2012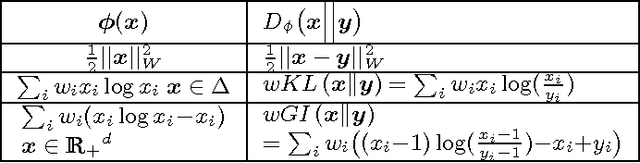
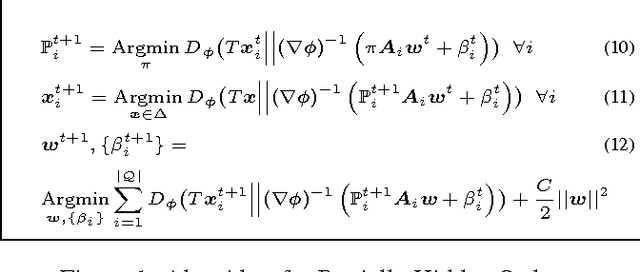
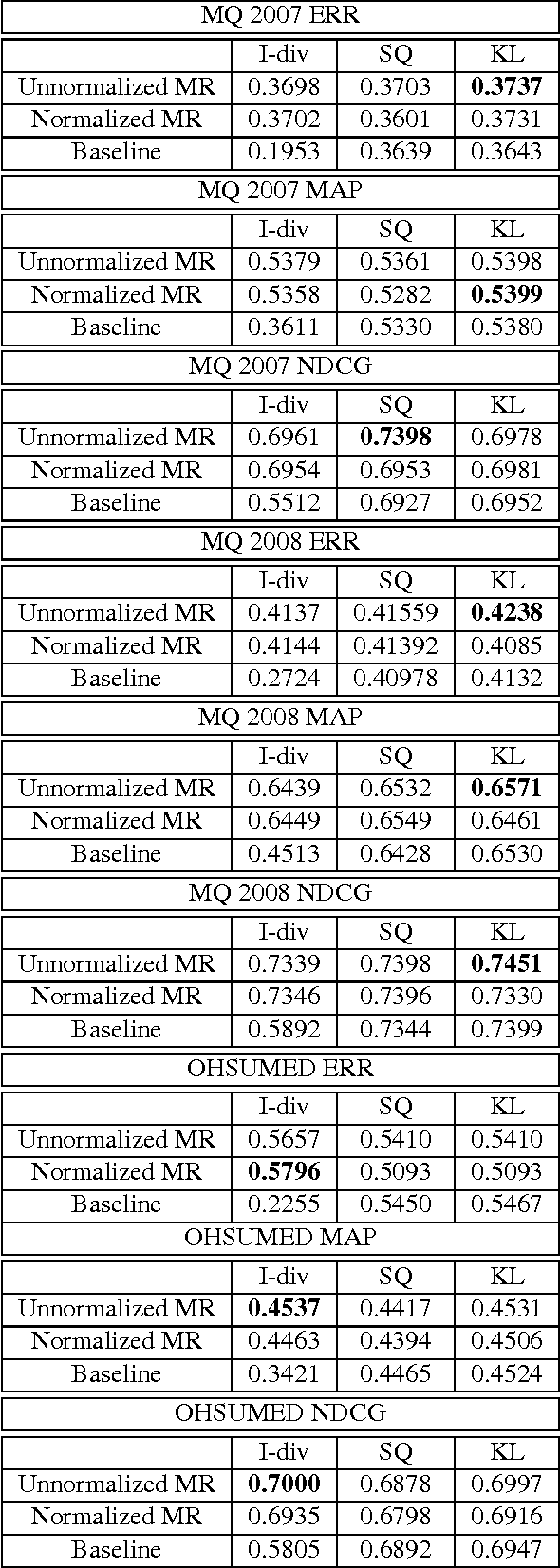
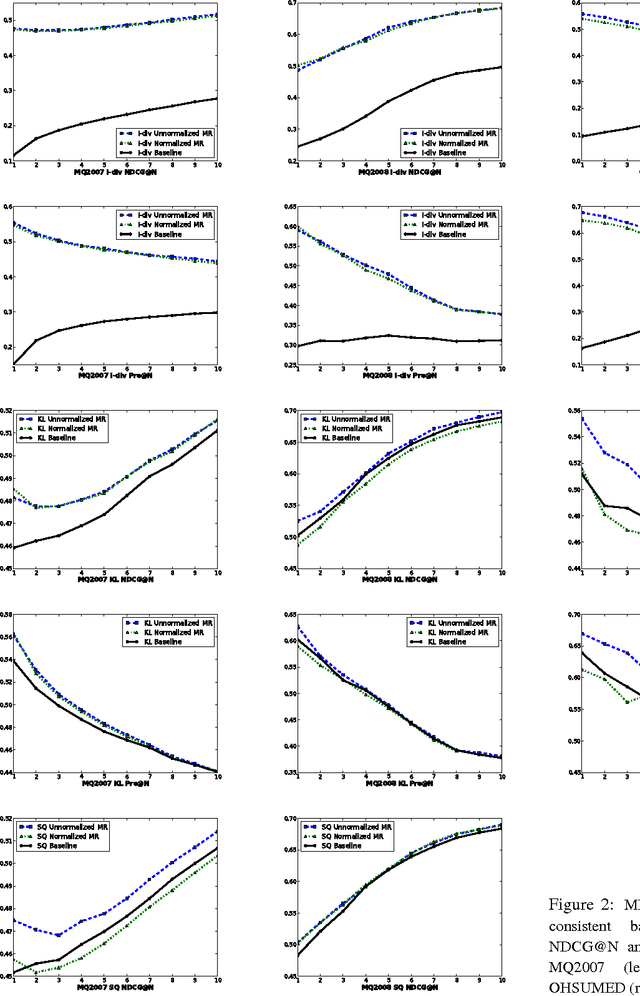
This paper introduces a novel approach for learning to rank (LETOR) based on the notion of monotone retargeting. It involves minimizing a divergence between all monotonic increasing transformations of the training scores and a parameterized prediction function. The minimization is both over the transformations as well as over the parameters. It is applied to Bregman divergences, a large class of "distance like" functions that were recently shown to be the unique class that is statistically consistent with the normalized discounted gain (NDCG) criterion [19]. The algorithm uses alternating projection style updates, in which one set of simultaneous projections can be computed independent of the Bregman divergence and the other reduces to parameter estimation of a generalized linear model. This results in easily implemented, efficiently parallelizable algorithm for the LETOR task that enjoys global optimum guarantees under mild conditions. We present empirical results on benchmark datasets showing that this approach can outperform the state of the art NDCG consistent techniques.
A Privacy-Aware Bayesian Approach for Combining Classifier and Cluster Ensembles
Apr 20, 2012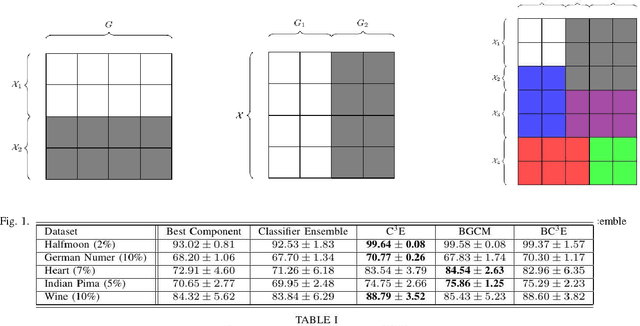
This paper introduces a privacy-aware Bayesian approach that combines ensembles of classifiers and clusterers to perform semi-supervised and transductive learning. We consider scenarios where instances and their classification/clustering results are distributed across different data sites and have sharing restrictions. As a special case, the privacy aware computation of the model when instances of the target data are distributed across different data sites, is also discussed. Experimental results show that the proposed approach can provide good classification accuracies while adhering to the data/model sharing constraints.