 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Framework for AI Systems in "the Wild"
Apr 23, 2025Generative AI (GenAI) models have become vital across industries, yet current evaluation methods have not adapted to their widespread use. Traditional evaluations often rely on benchmarks and fixed datasets, frequently failing to reflect real-world performance, which creates a gap between lab-tested outcomes and practical applications. This white paper proposes a comprehensive framework for how we should evaluate real-world GenAI systems, emphasizing diverse, evolving inputs and holistic, dynamic, and ongoing assessment approaches. The paper offers guidance for practitioners on how to design evaluation methods that accurately reflect real-time capabilities, and provides policymakers with recommendations for crafting GenAI policies focused on societal impacts, rather than fixed performance numbers or parameter sizes. We advocate for holistic frameworks that integrate performance, fairness, and ethics and the use of continuous, outcome-oriented methods that combine human and automated assessments while also being transparent to foster trust among stakeholders. Implementing these strategies ensures GenAI models are not only technically proficient but also ethically responsible and impactful.
Analyzing Assumptions in Conversation Disentanglement Research Through the Lens of a New Dataset and Model
Oct 25, 2018
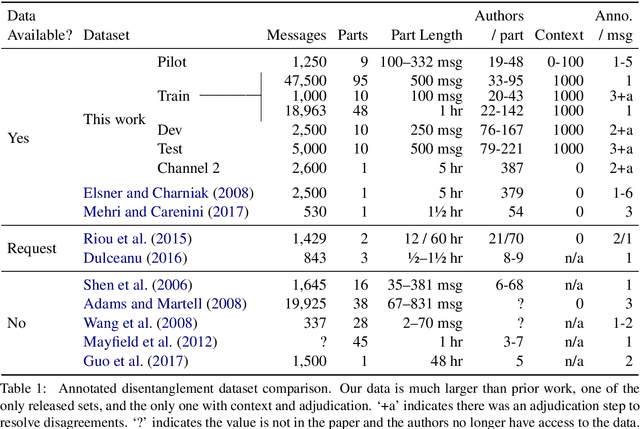

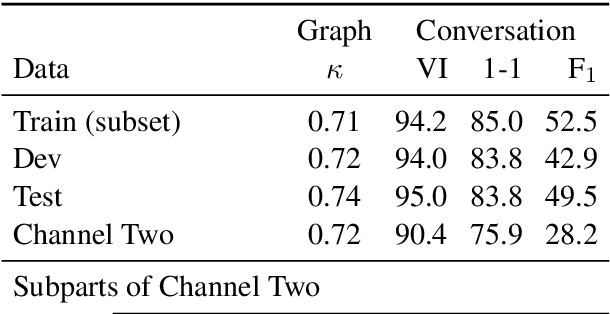
Disentangling conversations mixed together in a single stream of messages is a difficult task with no large annotated datasets. We created a new dataset that is 25 times the size of any previous publicly available resource, has samples of conversation from 152 points in time across a decade, and is annotated with both threads and a within-thread reply-structure graph. We also developed a new neural network model, which extracts conversation threads substantially more accurately than prior work. Using our annotated data and our model we tested assumptions in prior work, revealing major issues in heuristically constructed resources, and identifying how small datasets have biased our understanding of multi-party multi-conversation chat.