 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive yet Tractable Bayesian Deep Learning via Subnetwork Inference
Oct 28, 2020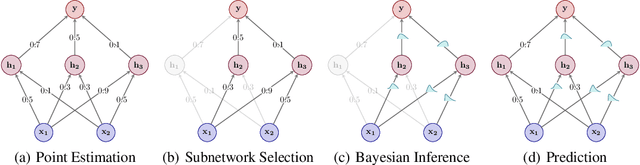

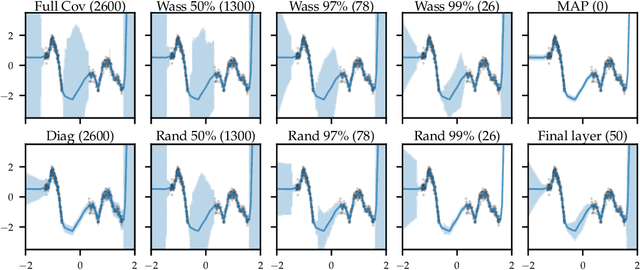

The Bayesian paradigm has the potential to solve some of the core issues in modern deep learning, such as poor calibration, data inefficiency, and catastrophic forgetting. However, scaling Bayesian inference to the high-dimensional parameter spaces of deep neural networks requires restrictive approximations. In this paper, we propose performing inference over only a small subset of the model parameters while keeping all others as point estimates. This enables us to use expressive posterior approximations that would otherwise be intractable for the full model. In particular, we develop a practical and scalable Bayesian deep learning method that first trains a point estimate, and then infers a full covariance Gaussian posterior approximation over a subnetwork. We propose a subnetwork selection procedure which aims to optimally preserve posterior uncertainty. We empirically demonstrate the effectiveness of our approach compared to point-estimated networks and methods that use less expressive posterior approximations over the full network.
Compressing Images by Encoding Their Latent Representations with Relative Entropy Coding
Oct 27, 2020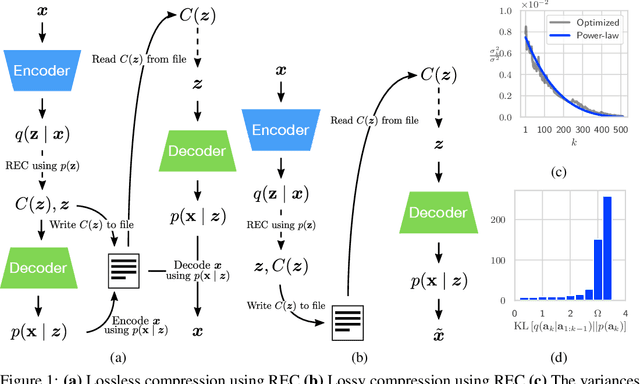
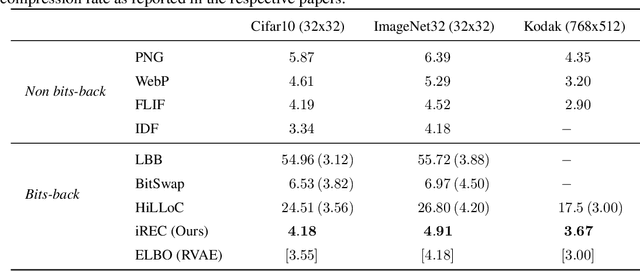
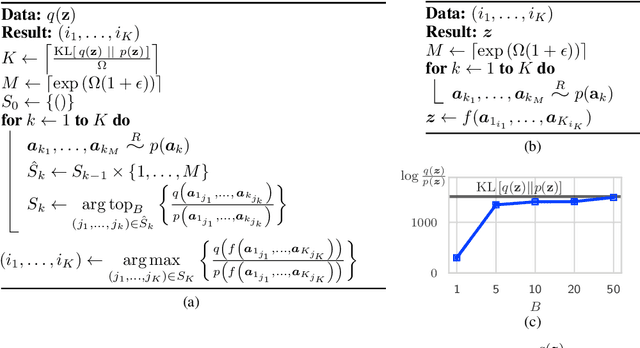
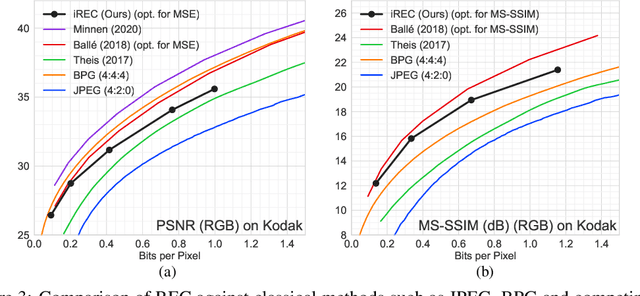
Variational Autoencoders (VAEs) have seen widespread use in learned image compression. They are used to learn expressive latent representations on which downstream compression methods can operate with high efficiency. Recently proposed 'bits-back' methods can indirectly encode the latent representation of images with codelength close to the relative entropy between the latent posterior and the prior. However, due to the underlying algorithm, these methods can only be used for lossless compression, and they only achieve their nominal efficiency when compressing multiple images simultaneously; they are inefficient for compressing single images. As an alternative, we propose a novel method, Relative Entropy Coding (REC), that can directly encode the latent representation with codelength close to the relative entropy for single images, supported by our empirical results obtained on the Cifar10, ImageNet32 and Kodak datasets. Moreover, unlike previous bits-back methods, REC is immediately applicable to lossy compression, where it is competitive with the state-of-the-art on the Kodak dataset.
Diagnostic Questions:The NeurIPS 2020 Education Challenge
Aug 03, 2020

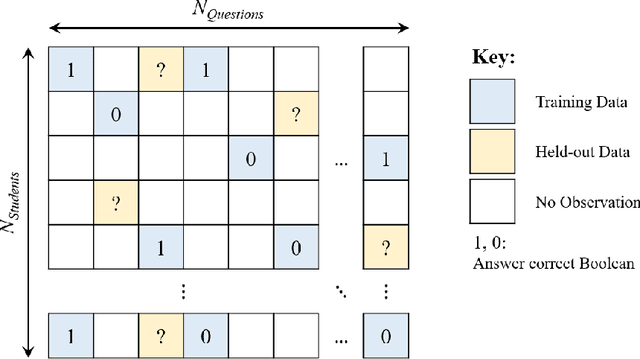
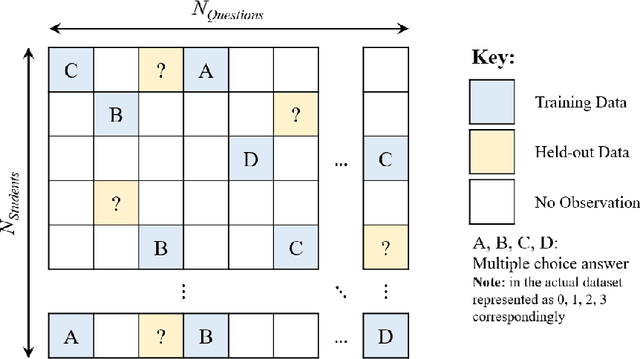
Digital technologies are becoming increasingly prevalent in education, enabling personalized, high quality education resources to be accessible by students across the world. Importantly, among these resources are diagnostic questions: the answers that the students give to these questions reveal key information about the specific nature of misconceptions that the students may hold. Analyzing the massive quantities of data stemming from students' interactions with these diagnostic questions can help us more accurately understand the students' learning status and thus allow us to automate learning curriculum recommendations. In this competition, participants will focus on the students' answer records to these multiple-choice diagnostic questions, with the aim of 1) accurately predicting which answers the students provide; 2) accurately predicting which questions have high quality; and 3) determining a personalized sequence of questions for each student that best predicts the student's answers. These tasks closely mimic the goals of a real-world educational platform and are highly representative of the educational challenges faced today. We provide over 20 million examples of students' answers to mathematics questions from Eedi, a leading educational platform which thousands of students interact with daily around the globe. Participants to this competition have a chance to make a lasting, real-world impact on the quality of personalized education for millions of students across the world.
DRIFT: Deep Reinforcement Learning for Functional Software Testing
Jul 16, 2020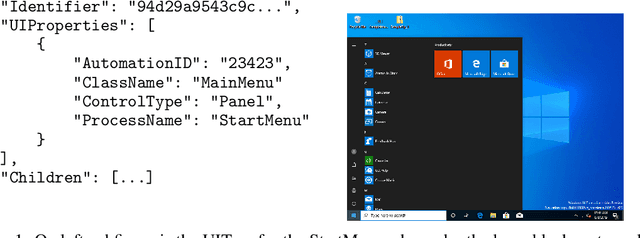
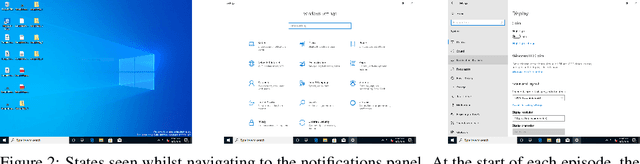
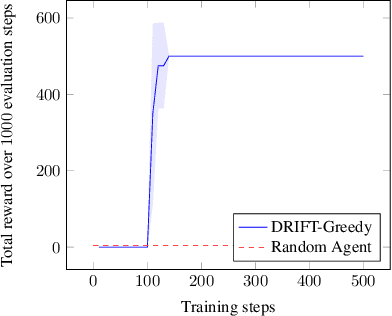

Efficient software testing is essential for productive software development and reliable user experiences. As human testing is inefficient and expensive, automated software testing is needed. In this work, we propose a Reinforcement Learning (RL) framework for functional software testing named DRIFT. DRIFT operates on the symbolic representation of the user interface. It uses Q-learning through Batch-RL and models the state-action value function with a Graph Neural Network. We apply DRIFT to testing the Windows 10 operating system and show that DRIFT can robustly trigger the desired software functionality in a fully automated manner. Our experiments test the ability to perform single and combined tasks across different applications, demonstrating that our framework can efficiently test software with a large range of testing objectives.
Predictive Complexity Priors
Jul 01, 2020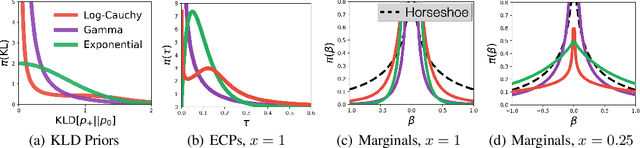
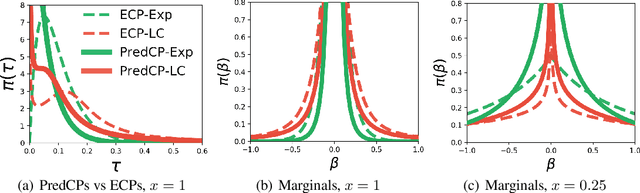

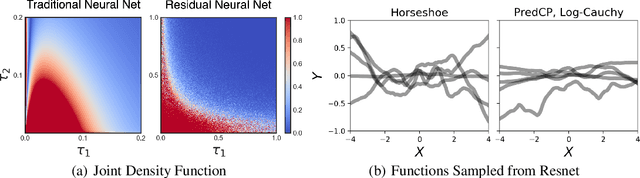
Specifying a Bayesian prior is notoriously difficult for complex models such as neural networks. Reasoning about parameters is made challenging by the high-dimensionality and over-parameterization of the space. Priors that seem benign and uninformative can have unintuitive and detrimental effects on a model's predictions. For this reason, we propose predictive complexity priors: a functional prior that is defined by comparing the model's predictions to those of a reference function. Although originally defined on the model outputs, we transfer the prior to the model parameters via a change of variables. The traditional Bayesian workflow can then proceed as usual. We apply our predictive complexity prior to modern machine learning tasks such as reasoning over neural network depth and sharing of statistical strength for few-shot learning.
Sliced Kernelized Stein Discrepancy
Jun 30, 2020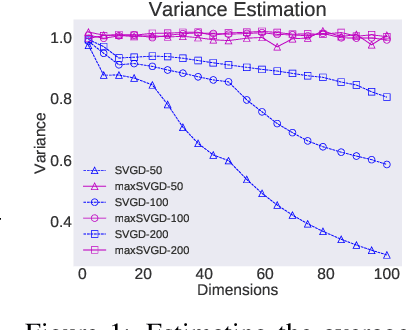

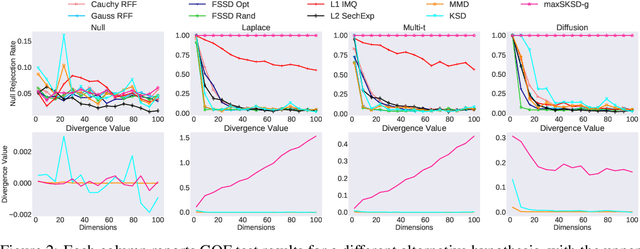

Kernelized Stein discrepancy (KSD), though being extensively used in goodness-of-fit tests and model learning, suffers from the curse-of-dimensionality. We address this issue by proposing the sliced Stein discrepancy and its scalable and kernelized variants, which employs kernel-based test functions defined on the optimal onedimensional projections instead of the full input in high dimensions. When applied to goodness-of-fit tests, extensive experiments show the proposed discrepancy significantly outperforms KSD and various baselines in high dimensions. For model learning, we show its advantages by training an independent component analysis when compared with existing Stein discrepancy baselines. We further propose a novel particle inference method called sliced Stein variational gradient descent (S-SVGD) which alleviates the mode-collapse issue of SVGD in training variational autoencoders.
VAEM: a Deep Generative Model for Heterogeneous Mixed Type Data
Jun 21, 2020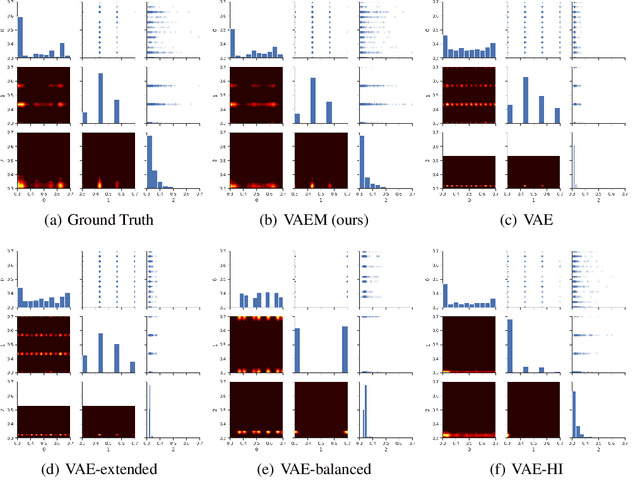

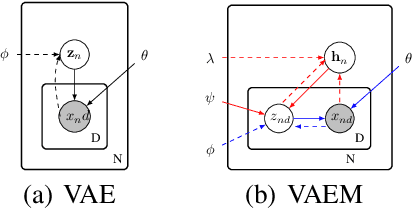
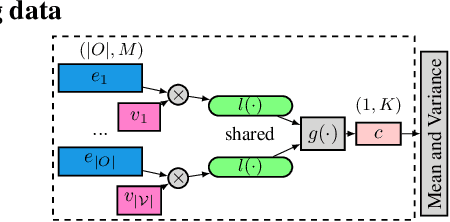
Deep generative models often perform poorly in real-world applications due to the heterogeneity of natural data sets. Heterogeneity arises from data containing different types of features (categorical, ordinal, continuous, etc.) and features of the same type having different marginal distributions. We propose an extension of variational autoencoders (VAEs) called VAEM to handle such heterogeneous data. VAEM is a deep generative model that is trained in a two stage manner such that the first stage provides a more uniform representation of the data to the second stage, thereby sidestepping the problems caused by heterogeneous data. We provide extensions of VAEM to handle partially observed data, and demonstrate its performance in data generation, missing data prediction and sequential feature selection tasks. Our results show that VAEM broadens the range of real-world applications where deep generative models can be successfully deployed.
Sample-Efficient Optimization in the Latent Space of Deep Generative Models via Weighted Retraining
Jun 16, 2020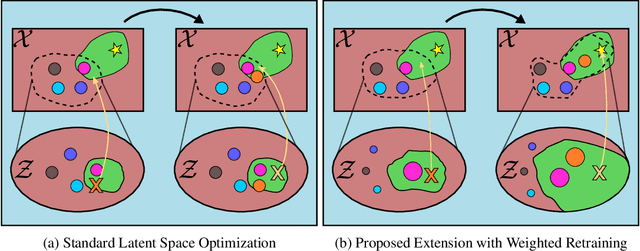
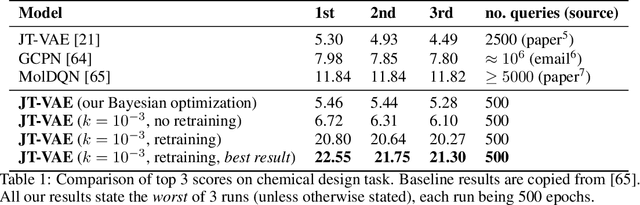


Many important problems in science and engineering, such as drug design, involve optimizing an expensive black-box objective function over a complex, high-dimensional, and structured input space. Although machine learning techniques have shown promise in solving such problems, existing approaches substantially lack sample efficiency. We introduce an improved method for efficient black-box optimization, which performs the optimization in the low-dimensional, continuous latent manifold learned by a deep generative model. In contrast to previous approaches, we actively steer the generative model to maintain a latent manifold that is highly useful for efficiently optimizing the objective. We achieve this by periodically retraining the generative model on the data points queried along the optimization trajectory, as well as weighting those data points according to their objective function value. This weighted retraining can be easily implemented on top of existing methods, and is empirically shown to significantly improve their efficiency and performance on synthetic and real-world optimization problems.
Depth Uncertainty in Neural Networks
Jun 15, 2020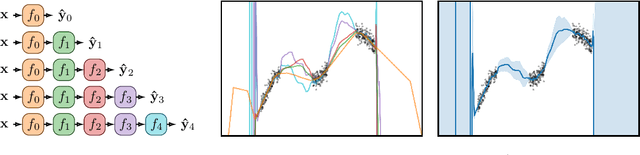

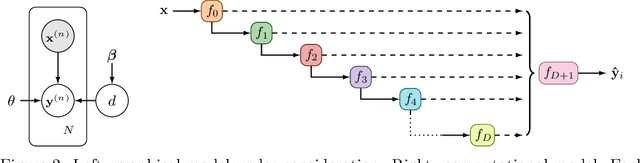

Existing methods for estimating uncertainty in deep learning tend to require multiple forward passes, making them unsuitable for applications where computational resources are limited. To solve this, we perform probabilistic reasoning over the depth of neural networks. Different depths correspond to subnetworks which share weights and whose predictions are combined via marginalisation, yielding model uncertainty. By exploiting the sequential structure of feed-forward networks, we are able to both evaluate our training objective and make predictions with a single forward pass. We validate our approach on real-world regression and image classification tasks. Our approach provides uncertainty calibration, robustness to dataset shift, and accuracies competitive with more computationally expensive baselines.
Getting a CLUE: A Method for Explaining Uncertainty Estimates
Jun 11, 2020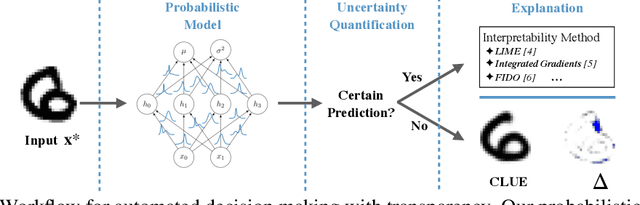
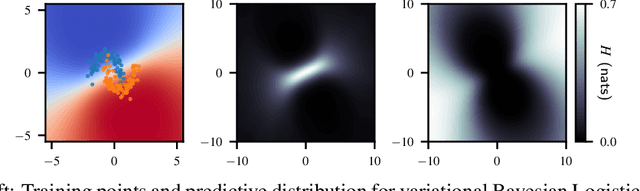


Both uncertainty estimation and interpretability are important factors for trustworthy machine learning systems. However, there is little work at the intersection of these two areas. We address this gap by proposing a novel method for interpreting uncertainty estimates from differentiable probabilistic models, like Bayesian Neural Networks (BNNs). Our method, Counterfactual Latent Uncertainty Explanations (CLUE), indicates how to change an input, while keeping it on the data manifold, such that a BNN becomes more confident about the input's prediction. We validate CLUE through 1) a novel framework for evaluating counterfactual explanations of uncertainty, 2) a series of ablation experiments, and 3) a user study. Our experiments show that CLUE outperforms baselines and enables practitioners to better understand which input patterns are responsible for predictive uncertainty.