 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Empowerment as Representation Learning for Goal-Based Reinforcement Learning
Jun 02, 2021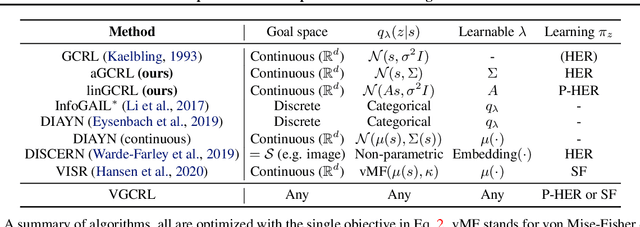

Learning to reach goal states and learning diverse skills through mutual information (MI) maximization have been proposed as principled frameworks for self-supervised reinforcement learning, allowing agents to acquire broadly applicable multitask policies with minimal reward engineering. Starting from a simple observation that the standard goal-conditioned RL (GCRL) is encapsulated by the optimization objective of variational empowerment, we discuss how GCRL and MI-based RL can be generalized into a single family of methods, which we name variational GCRL (VGCRL), interpreting variational MI maximization, or variational empowerment, as representation learning methods that acquire functionally-aware state representations for goal reaching. This novel perspective allows us to: (1) derive simple but unexplored variants of GCRL to study how adding small representation capacity can already expand its capabilities; (2) investigate how discriminator function capacity and smoothness determine the quality of discovered skills, or latent goals, through modifying latent dimensionality and applying spectral normalization; (3) adapt techniques such as hindsight experience replay (HER) from GCRL to MI-based RL; and lastly, (4) propose a novel evaluation metric, named latent goal reaching (LGR), for comparing empowerment algorithms with different choices of latent dimensionality and discriminator parameterization. Through principled mathematical derivations and careful experimental studies, our work lays a novel foundation from which to evaluate, analyze, and develop representation learning techniques in goal-based RL.
Meta Reinforcement Learning with Autonomous Inference of Subtask Dependencies
Jan 01, 2020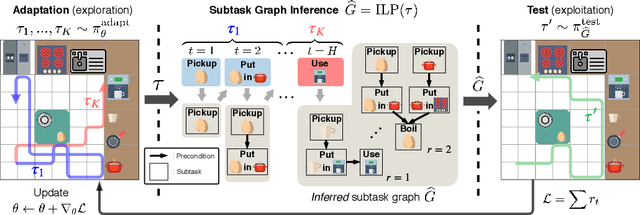
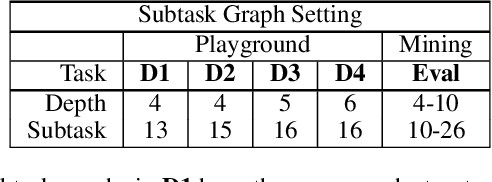
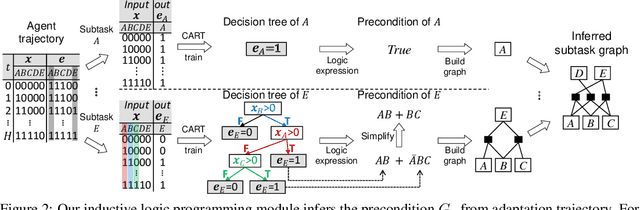
We propose and address a novel few-shot RL problem, where a task is characterized by a subtask graph which describes a set of subtasks and their dependencies that are unknown to the agent. The agent needs to quickly adapt to the task over few episodes during adaptation phase to maximize the return in the test phase. Instead of directly learning a meta-policy, we develop a Meta-learner with Subtask Graph Inference(MSGI), which infers the latent parameter of the task by interacting with the environment and maximizes the return given the latent parameter. To facilitate learning, we adopt an intrinsic reward inspired by upper confidence bound (UCB) that encourages efficient exploration. Our experiment results on two grid-world domains and StarCraft II environments show that the proposed method is able to accurately infer the latent task parameter, and to adapt more efficiently than existing meta RL and hierarchical RL methods.
Efficient Exploration with Self-Imitation Learning via Trajectory-Conditioned Policy
Jul 24, 2019
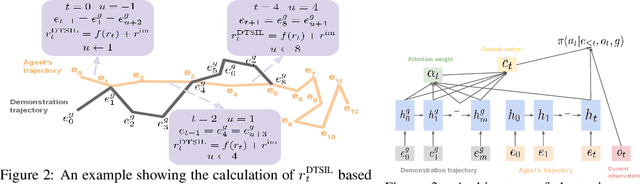
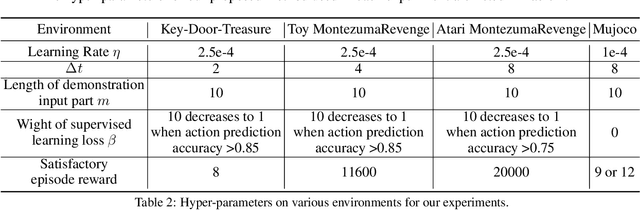
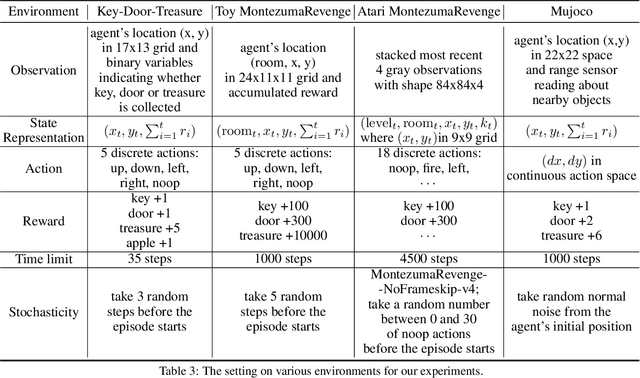
This paper proposes a method for learning a trajectory-conditioned policy to imitate diverse demonstrations from the agent's own past experiences. We demonstrate that such self-imitation drives exploration in diverse directions and increases the chance of finding a globally optimal solution in reinforcement learning problems, especially when the reward is sparse and deceptive. Our method significantly outperforms existing self-imitation learning and count-based exploration methods on various sparse-reward reinforcement learning tasks with local optima. In particular, we report a state-of-the-art score of more than 25,000 points on Montezuma's Revenge without using expert demonstrations or resetting to arbitrary states.
Contingency-Aware Exploration in Reinforcement Learning
Nov 05, 2018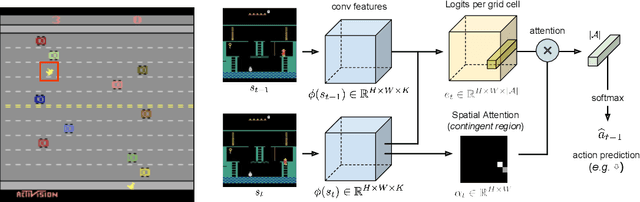
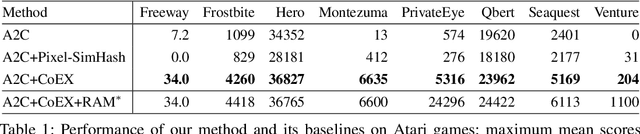
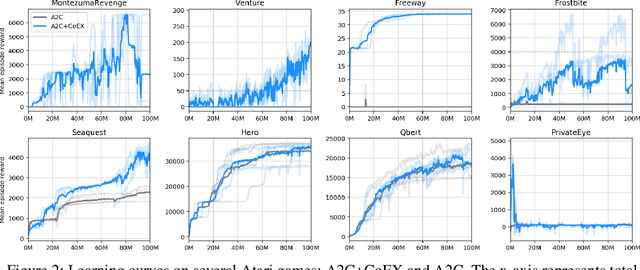
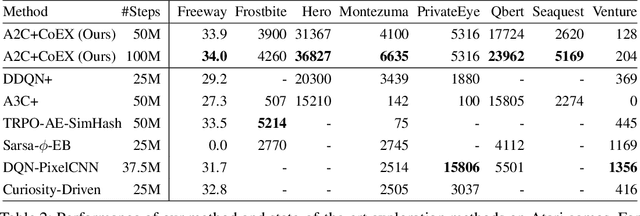
This paper investigates whether learning contingency-awareness and controllable aspects of an environment can lead to better exploration in reinforcement learning. To investigate this question, we consider an instantiation of this hypothesis evaluated on the Arcade Learning Element (ALE). In this study, we develop an attentive dynamics model (ADM) that discovers controllable elements of the observations, which are often associated with the location of the character in Atari games. The ADM is trained in a self-supervised fashion to predict the actions taken by the agent. The learned contingency information is used as a part of the state representation for exploration purposes. We demonstrate that combining A2C with count-based exploration using our representation achieves impressive results on a set of notoriously challenging Atari games due to sparse rewards. For example, we report a state-of-the-art score of >6600 points on Montezuma's Revenge without using expert demonstrations, explicit high-level information (e.g., RAM states), or supervised data. Our experiments confirm that indeed contingency-awareness is an extremely powerful concept for tackling exploration problems in reinforcement learning and opens up interesting research questions for further investigations.
Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis
Jul 26, 2018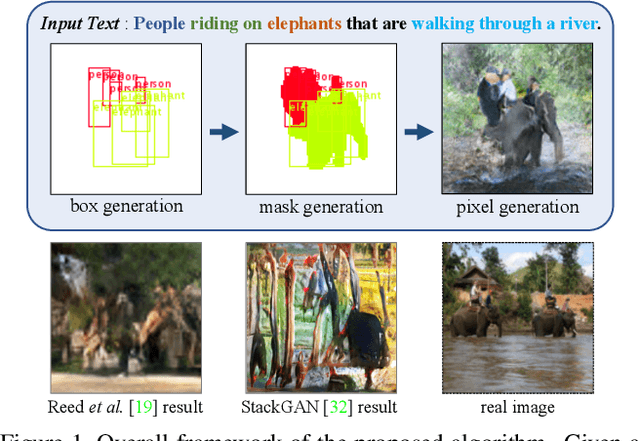
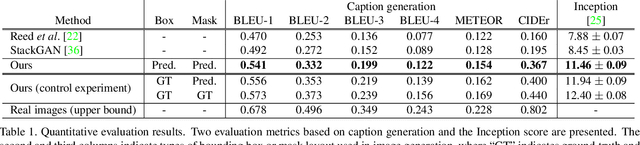
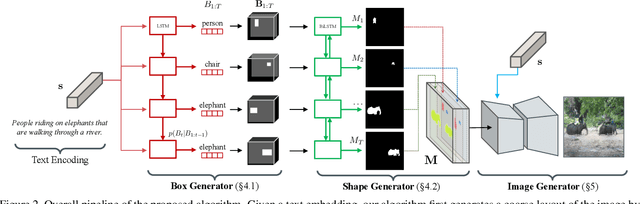
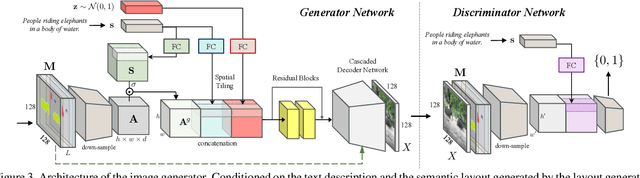
We propose a novel hierarchical approach for text-to-image synthesis by inferring semantic layout. Instead of learning a direct mapping from text to image, our algorithm decomposes the generation process into multiple steps, in which it first constructs a semantic layout from the text by the layout generator and converts the layout to an image by the image generator. The proposed layout generator progressively constructs a semantic layout in a coarse-to-fine manner by generating object bounding boxes and refining each box by estimating object shapes inside the box. The image generator synthesizes an image conditioned on the inferred semantic layout, which provides a useful semantic structure of an image matching with the text description. Our model not only generates semantically more meaningful images, but also allows automatic annotation of generated images and user-controlled generation process by modifying the generated scene layout. We demonstrate the capability of the proposed model on challenging MS-COCO dataset and show that the model can substantially improve the image quality, interpretability of output and semantic alignment to input text over existing approaches.
End-to-end Concept Word Detection for Video Captioning, Retrieval, and Question Answering
Jul 25, 2017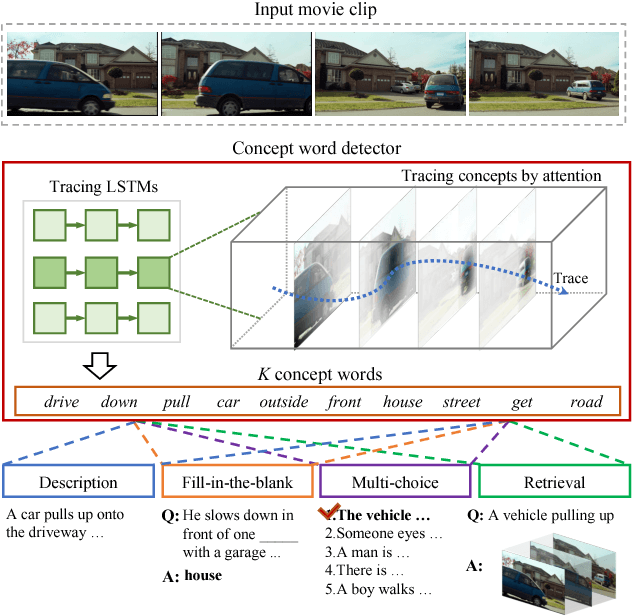
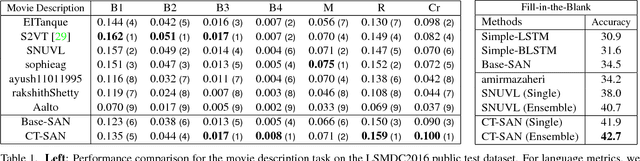
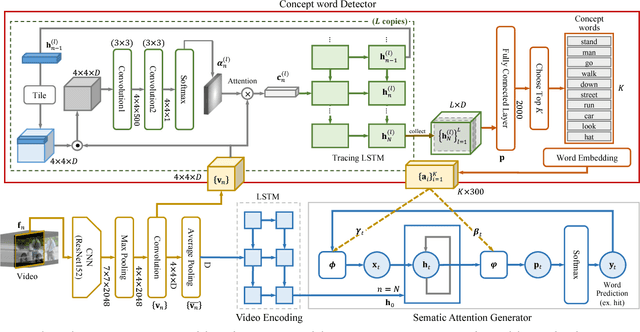
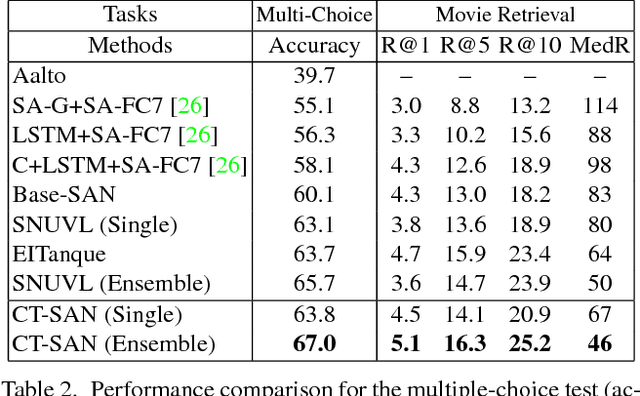
We propose a high-level concept word detector that can be integrated with any video-to-language models. It takes a video as input and generates a list of concept words as useful semantic priors for language generation models. The proposed word detector has two important properties. First, it does not require any external knowledge sources for training. Second, the proposed word detector is trainable in an end-to-end manner jointly with any video-to-language models. To maximize the values of detected words, we also develop a semantic attention mechanism that selectively focuses on the detected concept words and fuse them with the word encoding and decoding in the language model. In order to demonstrate that the proposed approach indeed improves the performance of multiple video-to-language tasks, we participate in four tasks of LSMDC 2016. Our approach achieves the best accuracies in three of them, including fill-in-the-blank, multiple-choice test, and movie retrieval. We also attain comparable performance for the other task, movie description.
* In CVPR 2017. Winner of three (fill-in-the-blank, multiple-choice test, and movie retrieval) out of four tasks of the LSMDC 2016 Challenge. 22 pages
Supervising Neural Attention Models for Video Captioning by Human Gaze Data
Jul 19, 2017

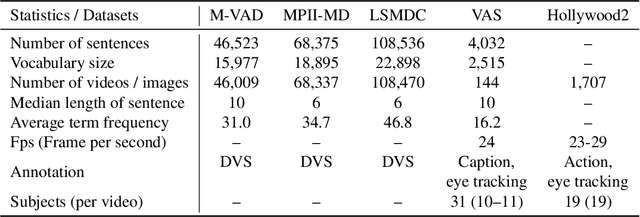
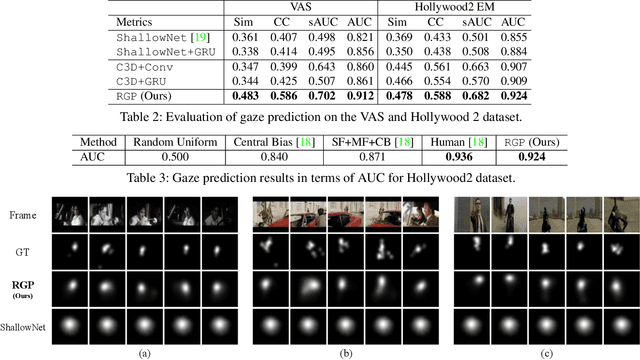
The attention mechanisms in deep neural networks are inspired by human's attention that sequentially focuses on the most relevant parts of the information over time to generate prediction output. The attention parameters in those models are implicitly trained in an end-to-end manner, yet there have been few trials to explicitly incorporate human gaze tracking to supervise the attention models. In this paper, we investigate whether attention models can benefit from explicit human gaze labels, especially for the task of video captioning. We collect a new dataset called VAS, consisting of movie clips, and corresponding multiple descriptive sentences along with human gaze tracking data. We propose a video captioning model named Gaze Encoding Attention Network (GEAN) that can leverage gaze tracking information to provide the spatial and temporal attention for sentence generation. Through evaluation of language similarity metrics and human assessment via Amazon mechanical Turk, we demonstrate that spatial attentions guided by human gaze data indeed improve the performance of multiple captioning methods. Moreover, we show that the proposed approach achieves the state-of-the-art performance for both gaze prediction and video captioning not only in our VAS dataset but also in standard datasets (e.g. LSMDC and Hollywood2).
* In CVPR 2017. 9 pages + supplementary 17 pages