 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaGScale: Viewpoint-Adaptive Gaussian Scaling in 3D Gaussian Splatting to Reduce Gaussian-Tile Pairs
Apr 21, 2026Reducing the number of Gaussian-tile pairs is one of the most promising approaches to improve 3D Gaussian Splatting (3D-GS) rendering speed on GPUs. However, the importance difference existing among Gaussian-tile pairs has never been considered in the previous works. In this paper, we propose AdaGScale, a novel viewpoint-adaptive Gaussian scaling technique for reducing the number of Gaussian-tile pairs. AdaGScale is based on the observation that the peripheral tiles located far from Gaussian center contribute negligibly to pixel color accumulation. This suggests an opportunity for reducing the number of Gaussian-tile pairs based on color contribution. AdaGScale efficiently estimates the color contribution in the peripheral region of each Gaussian during a preprocessing stage and adaptively scales its size based on the peripheral score. As a result, Gaussians with lower importance intersect with fewer tiles during the intersection test, which improves rendering speed while maintaining image quality. The adjusted size is used only for tile intersection test, and the original size is retained during color accumulation to preserve visual fidelity. Experimental results show that AdaGScale achieves a geometric mean speedup of 13.8x over original 3D-GS on a GPU, with only about 0.5 dB degradation in PSNR on city-scale scenes.
GLOVA: Global and Local Variation-Aware Analog Circuit Design with Risk-Sensitive Reinforcement Learning
May 16, 2025Analog/mixed-signal circuit design encounters significant challenges due to performance degradation from process, voltage, and temperature (PVT) variations. To achieve commercial-grade reliability, iterative manual design revisions and extensive statistical simulations are required. While several studies have aimed to automate variation aware analog design to reduce time-to-market, the substantial mismatches in real-world wafers have not been thoroughly addressed. In this paper, we present GLOVA, an analog circuit sizing framework that effectively manages the impact of diverse random mismatches to improve robustness against PVT variations. In the proposed approach, risk-sensitive reinforcement learning is leveraged to account for the reliability bound affected by PVT variations, and ensemble-based critic is introduced to achieve sample-efficient learning. For design verification, we also propose $\mu$-$\sigma$ evaluation and simulation reordering method to reduce simulation costs of identifying failed designs. GLOVA supports verification through industrial-level PVT variation evaluation methods, including corner simulation as well as global and local Monte Carlo (MC) simulations. Compared to previous state-of-the-art variation-aware analog sizing frameworks, GLOVA achieves up to 80.5$\times$ improvement in sample efficiency and 76.0$\times$ reduction in time.
Identifying Unnecessary 3D Gaussians using Clustering for Fast Rendering of 3D Gaussian Splatting
Feb 21, 20243D Gaussian splatting (3D-GS) is a new rendering approach that outperforms the neural radiance field (NeRF) in terms of both speed and image quality. 3D-GS represents 3D scenes by utilizing millions of 3D Gaussians and projects these Gaussians onto the 2D image plane for rendering. However, during the rendering process, a substantial number of unnecessary 3D Gaussians exist for the current view direction, resulting in significant computation costs associated with their identification. In this paper, we propose a computational reduction technique that quickly identifies unnecessary 3D Gaussians in real-time for rendering the current view without compromising image quality. This is accomplished through the offline clustering of 3D Gaussians that are close in distance, followed by the projection of these clusters onto a 2D image plane during runtime. Additionally, we analyze the bottleneck associated with the proposed technique when executed on GPUs and propose an efficient hardware architecture that seamlessly supports the proposed scheme. For the Mip-NeRF360 dataset, the proposed technique excludes 63% of 3D Gaussians on average before the 2D image projection, which reduces the overall rendering computation by almost 38.3% without sacrificing peak-signal-to-noise-ratio (PSNR). The proposed accelerator also achieves a speedup of 10.7x compared to a GPU.
A Charge Domain P-8T SRAM Compute-In-Memory with Low-Cost DAC/ADC Operation for 4-bit Input Processing
Nov 29, 2022This paper presents a low cost PMOS-based 8T (P-8T) SRAM Compute-In-Memory (CIM) architecture that efficiently per-forms the multiply-accumulate (MAC) operations between 4-bit input activations and 8-bit weights. First, bit-line (BL) charge-sharing technique is employed to design the low-cost and reliable digital-to-analog conversion of 4-bit input activations in the pro-posed SRAM CIM, where the charge domain analog computing provides variation tolerant and linear MAC outputs. The 16 local arrays are also effectively exploited to implement the analog mul-tiplication unit (AMU) that simultaneously produces 16 multipli-cation results between 4-bit input activations and 1-bit weights. For the hardware cost reduction of analog-to-digital converter (ADC) without sacrificing DNN accuracy, hardware aware sys-tem simulations are performed to decide the ADC bit-resolutions and the number of activated rows in the proposed CIM macro. In addition, for the ADC operation, the AMU-based reference col-umns are utilized for generating ADC reference voltages, with which low-cost 4-bit coarse-fine flash ADC has been designed. The 256X80 P-8T SRAM CIM macro implementation using 28nm CMOS process shows that the proposed CIM shows the accuracies of 91.46% and 66.67% with CIFAR-10 and CIFAR-100 dataset, respectively, with the energy efficiency of 50.07-TOPS/W.
* Presented at ISLPED 2022
A Time-to-first-spike Coding and Conversion Aware Training for Energy-Efficient Deep Spiking Neural Network Processor Design
Aug 09, 2022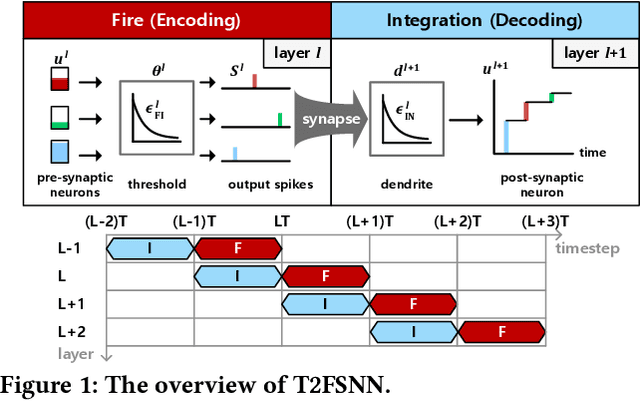
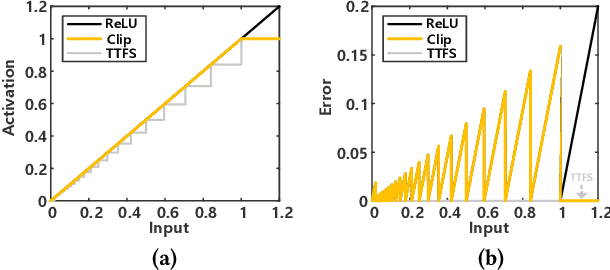
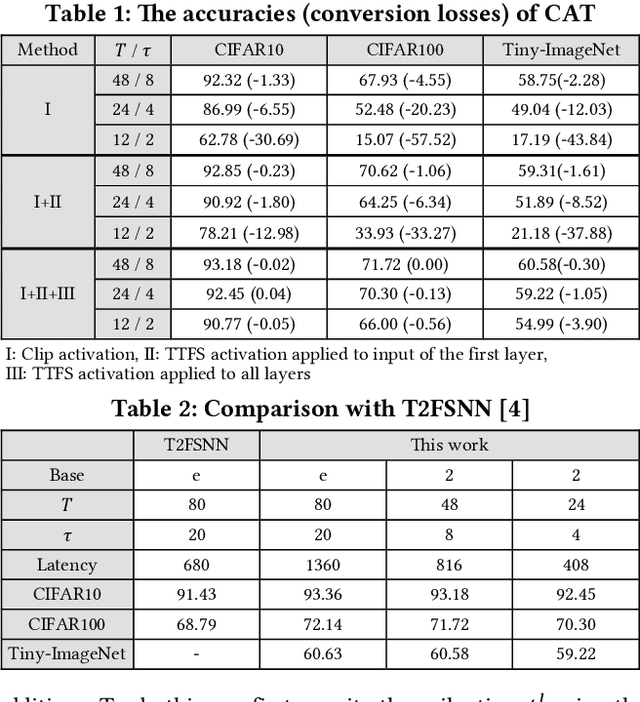
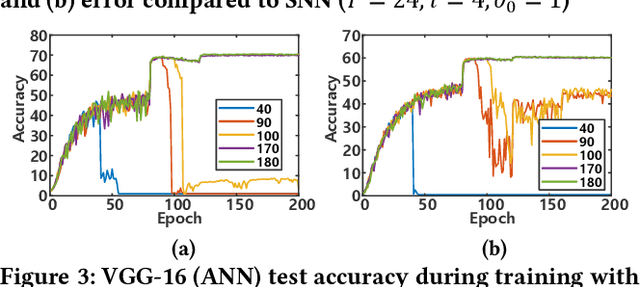
In this paper, we present an energy-efficient SNN architecture, which can seamlessly run deep spiking neural networks (SNNs) with improved accuracy. First, we propose a conversion aware training (CAT) to reduce ANN-to-SNN conversion loss without hardware implementation overhead. In the proposed CAT, the activation function developed for simulating SNN during ANN training, is efficiently exploited to reduce the data representation error after conversion. Based on the CAT technique, we also present a time-to-first-spike coding that allows lightweight logarithmic computation by utilizing spike time information. The SNN processor design that supports the proposed techniques has been implemented using 28nm CMOS process. The processor achieves the top-1 accuracies of 91.7%, 67.9% and 57.4% with inference energy of 486.7uJ, 503.6uJ, and 1426uJ to process CIFAR-10, CIFAR-100, and Tiny-ImageNet, respectively, when running VGG-16 with 5bit logarithmic weights.