 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable GFlowNets with Probabilistic Guarantees
May 03, 2026Generative Flow Networks (GFlowNets) learn to sample states proportional to an unnormalized reward. Despite their theoretical promise, practical training is often unstable, exhibiting severe loss spikes and mode collapse. To tackle this, we first assess the sensitivity of GFlowNet objectives, demonstrating that a small Total Variation (TV) distance between the learned and target distributions does not preclude unbounded training loss. Motivated by this mismatch, we establish converse guarantees by deriving loss-to-TV bounds that certify global fidelity from bounded trajectory balance losses. Lastly, we propose Stable GFlowNets, an algorithm that leverages our theoretical results to stabilize training, and empirically demonstrate improved training behavior and superior distributional fidelity.
CaBaGe: Data-Free Model Extraction using ClAss BAlanced Generator Ensemble
Sep 16, 2024Machine Learning as a Service (MLaaS) is often provided as a pay-per-query, black-box system to clients. Such a black-box approach not only hinders open replication, validation, and interpretation of model results, but also makes it harder for white-hat researchers to identify vulnerabilities in the MLaaS systems. Model extraction is a promising technique to address these challenges by reverse-engineering black-box models. Since training data is typically unavailable for MLaaS models, this paper focuses on the realistic version of it: data-free model extraction. We propose a data-free model extraction approach, CaBaGe, to achieve higher model extraction accuracy with a small number of queries. Our innovations include (1) a novel experience replay for focusing on difficult training samples; (2) an ensemble of generators for steadily producing diverse synthetic data; and (3) a selective filtering process for querying the victim model with harder, more balanced samples. In addition, we create a more realistic setting, for the first time, where the attacker has no knowledge of the number of classes in the victim training data, and create a solution to learn the number of classes on the fly. Our evaluation shows that CaBaGe outperforms existing techniques on seven datasets -- MNIST, FMNIST, SVHN, CIFAR-10, CIFAR-100, ImageNet-subset, and Tiny ImageNet -- with an accuracy improvement of the extracted models by up to 43.13%. Furthermore, the number of queries required to extract a clone model matching the final accuracy of prior work is reduced by up to 75.7%.
Self-Play Learning Without a Reward Metric
Dec 16, 2019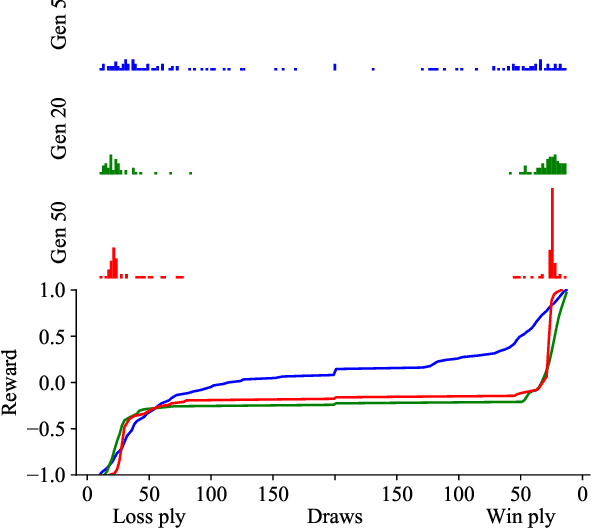
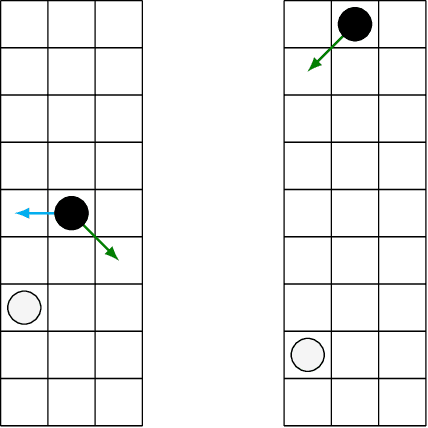

The AlphaZero algorithm for the learning of strategy games via self-play, which has produced superhuman ability in the games of Go, chess, and shogi, uses a quantitative reward function for game outcomes, requiring the users of the algorithm to explicitly balance different components of the reward against each other, such as the game winner and margin of victory. We present a modification to the AlphaZero algorithm that requires only a total ordering over game outcomes, obviating the need to perform any quantitative balancing of reward components. We demonstrate that this system learns optimal play in a comparable amount of time to AlphaZero on a sample game.
The Boundary Forest Algorithm for Online Supervised and Unsupervised Learning
May 12, 2015
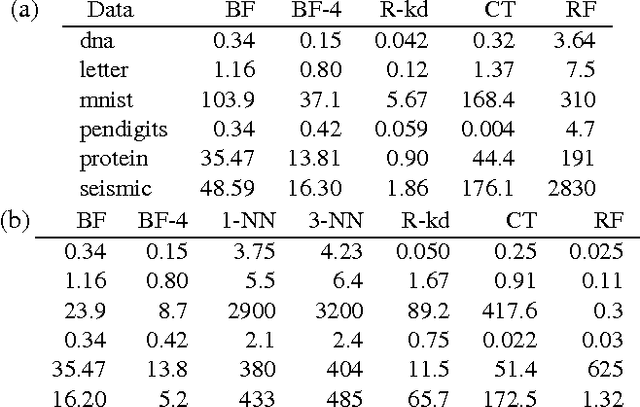
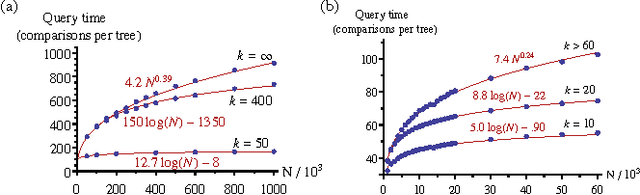
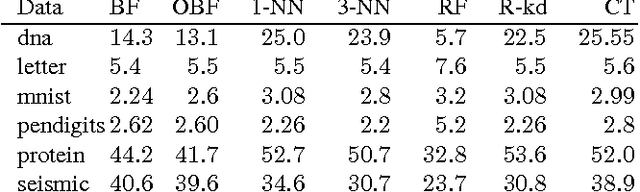
We describe a new instance-based learning algorithm called the Boundary Forest (BF) algorithm, that can be used for supervised and unsupervised learning. The algorithm builds a forest of trees whose nodes store previously seen examples. It can be shown data points one at a time and updates itself incrementally, hence it is naturally online. Few instance-based algorithms have this property while being simultaneously fast, which the BF is. This is crucial for applications where one needs to respond to input data in real time. The number of children of each node is not set beforehand but obtained from the training procedure, which makes the algorithm very flexible with regards to what data manifolds it can learn. We test its generalization performance and speed on a range of benchmark datasets and detail in which settings it outperforms the state of the art. Empirically we find that training time scales as O(DNlog(N)) and testing as O(Dlog(N)), where D is the dimensionality and N the amount of data,
* 7 pages, 4 figs, 1 page supp. info