 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaphrastic Representations at Scale
Apr 30, 2021


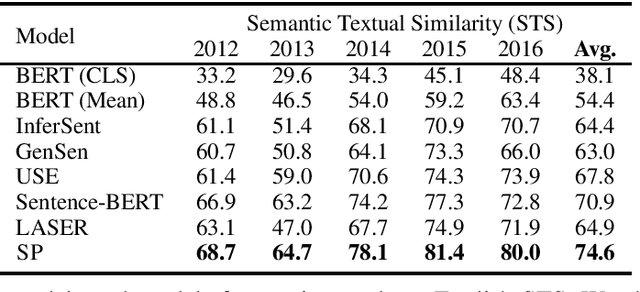
We present a system that allows users to train their own state-of-the-art paraphrastic sentence representations in a variety of languages. We also release trained models for English, Arabic, German, French, Spanish, Russian, Turkish, and Chinese. We train these models on large amounts of data, achieving significantly improved performance from the original papers proposing the methods on a suite of monolingual semantic similarity, cross-lingual semantic similarity, and bitext mining tasks. Moreover, the resulting models surpass all prior work on unsupervised semantic textual similarity, significantly outperforming even BERT-based models like Sentence-BERT (Reimers and Gurevych, 2019). Additionally, our models are orders of magnitude faster than prior work and can be used on CPU with little difference in inference speed (even improved speed over GPU when using more CPU cores), making these models an attractive choice for users without access to GPUs or for use on embedded devices. Finally, we add significantly increased functionality to the code bases for training paraphrastic sentence models, easing their use for both inference and for training them for any desired language with parallel data. We also include code to automatically download and preprocess training data.
CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation
Mar 31, 2021
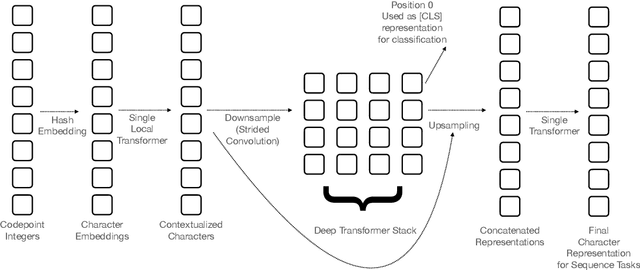


Pipelined NLP systems have largely been superseded by end-to-end neural modeling, yet nearly all commonly-used models still require an explicit tokenization step. While recent tokenization approaches based on data-derived subword lexicons are less brittle than manually engineered tokenizers, these techniques are not equally suited to all languages, and the use of any fixed vocabulary may limit a model's ability to adapt. In this paper, we present CANINE, a neural encoder that operates directly on character sequences, without explicit tokenization or vocabulary, and a pre-training strategy that operates either directly on characters or optionally uses subwords as a soft inductive bias. To use its finer-grained input effectively and efficiently, CANINE combines downsampling, which reduces the input sequence length, with a deep transformer stack, which encodes context. CANINE outperforms a comparable mBERT model by 2.8 F1 on TyDi QA, a challenging multilingual benchmark, despite having 28% fewer model parameters.
On Learning Text Style Transfer with Direct Rewards
Oct 24, 2020
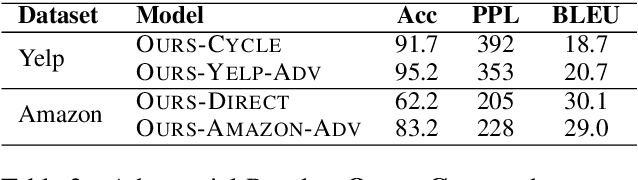

In most cases, the lack of parallel corpora makes it impossible to directly train supervised models for text style transfer task. In this paper, we explore training algorithms that instead optimize reward functions that explicitly consider different aspects of the style-transferred outputs. In particular, we leverage semantic similarity metrics originally used for fine-tuning neural machine translation models to explicitly assess the preservation of content between system outputs and input texts. We also investigate the potential weaknesses of the existing automatic metrics and propose efficient strategies of using these metrics for training. The experimental results show that our model provides significant gains in both automatic and human evaluation over strong baselines, indicating the effectiveness of our proposed methods and training strategies.
Reformulating Unsupervised Style Transfer as Paraphrase Generation
Oct 12, 2020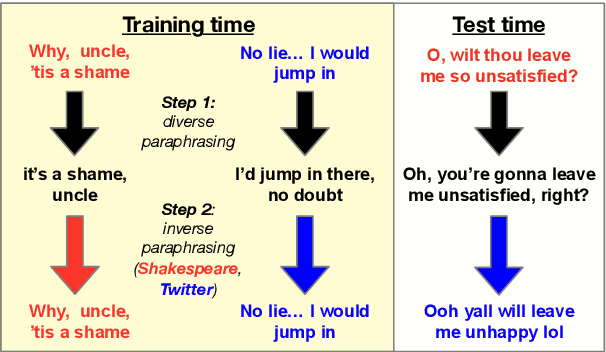
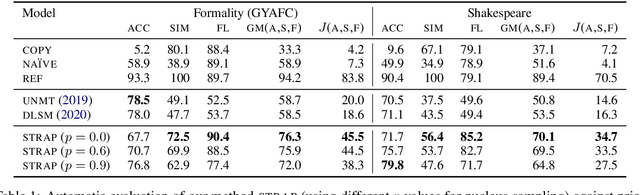
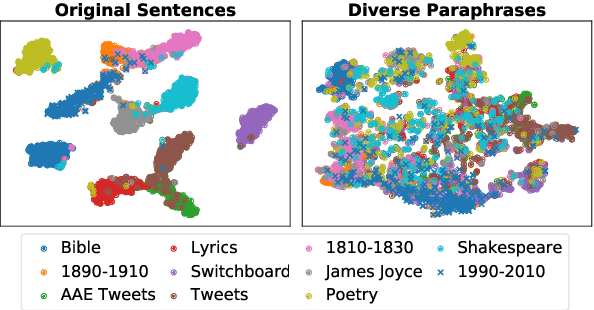
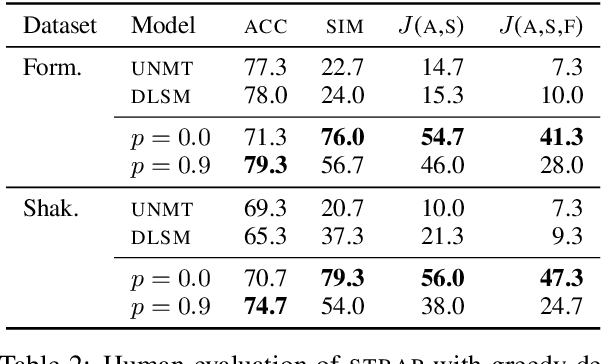
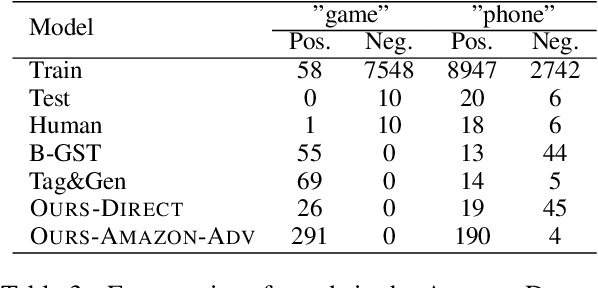
Modern NLP defines the task of style transfer as modifying the style of a given sentence without appreciably changing its semantics, which implies that the outputs of style transfer systems should be paraphrases of their inputs. However, many existing systems purportedly designed for style transfer inherently warp the input's meaning through attribute transfer, which changes semantic properties such as sentiment. In this paper, we reformulate unsupervised style transfer as a paraphrase generation problem, and present a simple methodology based on fine-tuning pretrained language models on automatically generated paraphrase data. Despite its simplicity, our method significantly outperforms state-of-the-art style transfer systems on both human and automatic evaluations. We also survey 23 style transfer papers and discover that existing automatic metrics can be easily gamed and propose fixed variants. Finally, we pivot to a more real-world style transfer setting by collecting a large dataset of 15M sentences in 11 diverse styles, which we use for an in-depth analysis of our system.
Improving Candidate Generation for Low-resource Cross-lingual Entity Linking
Mar 03, 2020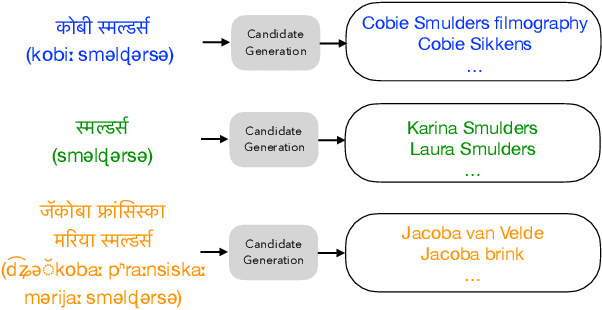
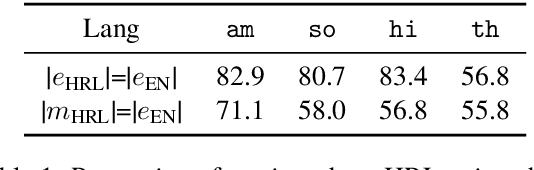
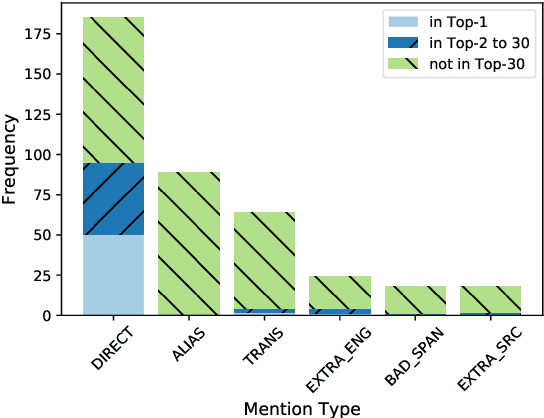
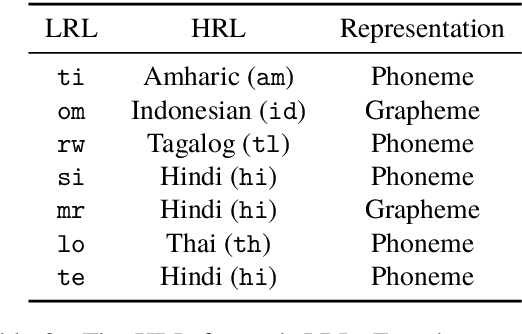
Cross-lingual entity linking (XEL) is the task of finding referents in a target-language knowledge base (KB) for mentions extracted from source-language texts. The first step of (X)EL is candidate generation, which retrieves a list of plausible candidate entities from the target-language KB for each mention. Approaches based on resources from Wikipedia have proven successful in the realm of relatively high-resource languages (HRL), but these do not extend well to low-resource languages (LRL) with few, if any, Wikipedia pages. Recently, transfer learning methods have been shown to reduce the demand for resources in the LRL by utilizing resources in closely-related languages, but the performance still lags far behind their high-resource counterparts. In this paper, we first assess the problems faced by current entity candidate generation methods for low-resource XEL, then propose three improvements that (1) reduce the disconnect between entity mentions and KB entries, and (2) improve the robustness of the model to low-resource scenarios. The methods are simple, but effective: we experiment with our approach on seven XEL datasets and find that they yield an average gain of 16.9% in Top-30 gold candidate recall, compared to state-of-the-art baselines. Our improved model also yields an average gain of 7.9% in in-KB accuracy of end-to-end XEL.
A Bilingual Generative Transformer for Semantic Sentence Embedding
Nov 10, 2019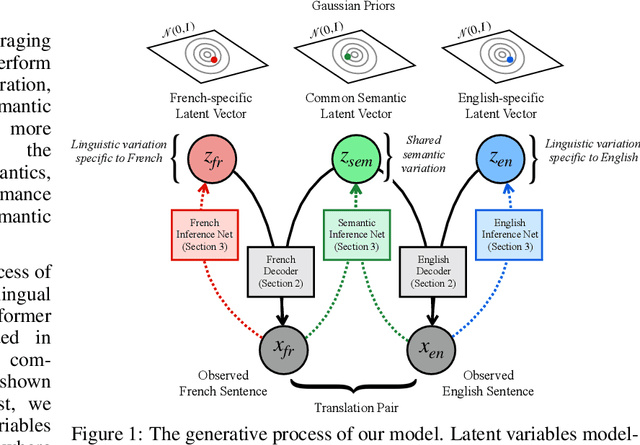

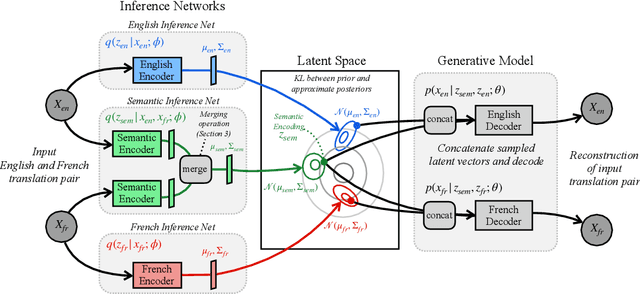
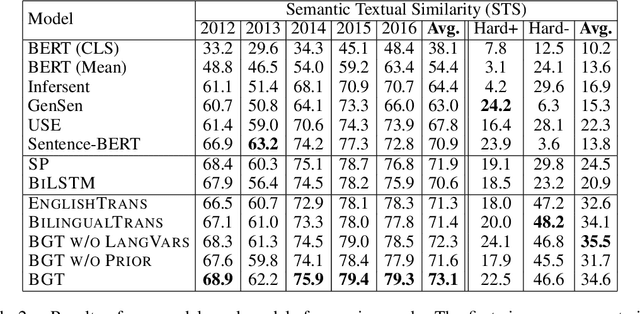
Semantic sentence embedding models encode natural language sentences into vectors, such that closeness in embedding space indicates closeness in the semantics between the sentences. Bilingual data offers a useful signal for learning such embeddings: properties shared by both sentences in a translation pair are likely semantic, while divergent properties are likely stylistic or language-specific. We propose a deep latent variable model that attempts to perform source separation on parallel sentences, isolating what they have in common in a latent semantic vector, and explaining what is left over with language-specific latent vectors. Our proposed approach differs from past work on semantic sentence encoding in two ways. First, by using a variational probabilistic framework, we introduce priors that encourage source separation, and can use our model's posterior to predict sentence embeddings for monolingual data at test time. Second, we use high-capacity transformers as both data generating distributions and inference networks -- contrasting with most past work on sentence embeddings. In experiments, our approach substantially outperforms the state-of-the-art on a standard suite of unsupervised semantic similarity evaluations. Further, we demonstrate that our approach yields the largest gains on more difficult subsets of these evaluations where simple word overlap is not a good indicator of similarity.
Simple and Effective Paraphrastic Similarity from Parallel Translations
Sep 30, 2019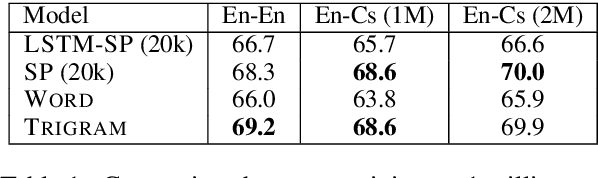
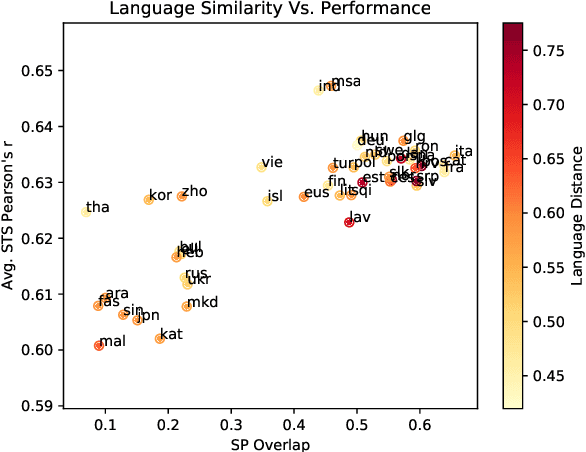
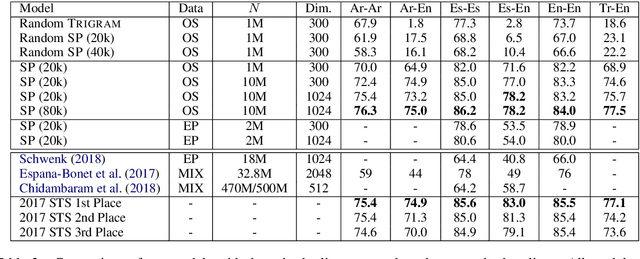
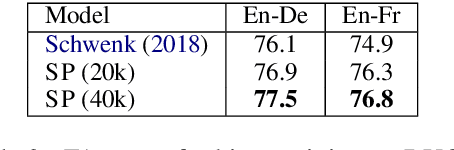
We present a model and methodology for learning paraphrastic sentence embeddings directly from bitext, removing the time-consuming intermediate step of creating paraphrase corpora. Further, we show that the resulting model can be applied to cross-lingual tasks where it both outperforms and is orders of magnitude faster than more complex state-of-the-art baselines.
Beyond BLEU: Training Neural Machine Translation with Semantic Similarity
Sep 14, 2019



While most neural machine translation (NMT) systems are still trained using maximum likelihood estimation, recent work has demonstrated that optimizing systems to directly improve evaluation metrics such as BLEU can substantially improve final translation accuracy. However, training with BLEU has some limitations: it doesn't assign partial credit, it has a limited range of output values, and it can penalize semantically correct hypotheses if they differ lexically from the reference. In this paper, we introduce an alternative reward function for optimizing NMT systems that is based on recent work in semantic similarity. We evaluate on four disparate languages translated to English, and find that training with our proposed metric results in better translations as evaluated by BLEU, semantic similarity, and human evaluation, and also that the optimization procedure converges faster. Analysis suggests that this is because the proposed metric is more conducive to optimization, assigning partial credit and providing more diversity in scores than BLEU.
No Training Required: Exploring Random Encoders for Sentence Classification
Jan 29, 2019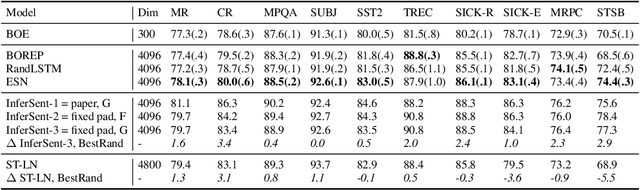
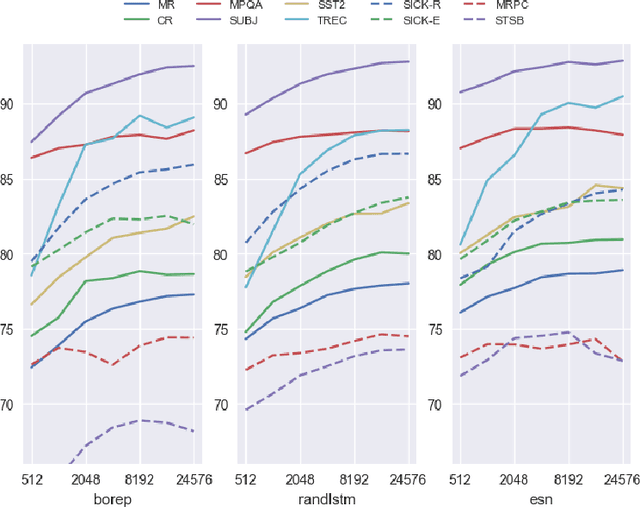
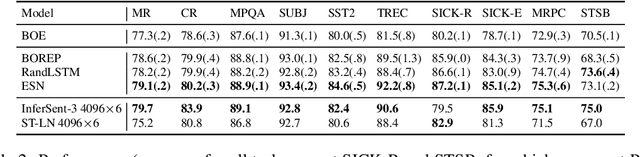

We explore various methods for computing sentence representations from pre-trained word embeddings without any training, i.e., using nothing but random parameterizations. Our aim is to put sentence embeddings on more solid footing by 1) looking at how much modern sentence embeddings gain over random methods---as it turns out, surprisingly little; and by 2) providing the field with more appropriate baselines going forward---which are, as it turns out, quite strong. We also make important observations about proper experimental protocol for sentence classification evaluation, together with recommendations for future research.
ParaNMT-50M: Pushing the Limits of Paraphrastic Sentence Embeddings with Millions of Machine Translations
Apr 20, 2018

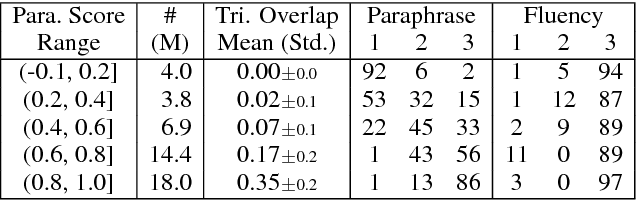
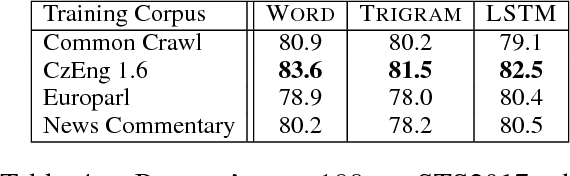
We describe PARANMT-50M, a dataset of more than 50 million English-English sentential paraphrase pairs. We generated the pairs automatically by using neural machine translation to translate the non-English side of a large parallel corpus, following Wieting et al. (2017). Our hope is that ParaNMT-50M can be a valuable resource for paraphrase generation and can provide a rich source of semantic knowledge to improve downstream natural language understanding tasks. To show its utility, we use ParaNMT-50M to train paraphrastic sentence embeddings that outperform all supervised systems on every SemEval semantic textual similarity competition, in addition to showing how it can be used for paraphrase generation.