 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does Deep RL Beat Calibrated Baselines? A Benchmark Study on Adaptive Resource Control
May 26, 2026A properly calibrated rule-based autoscaler can beat every one of six mainstream deep reinforcement learning (DRL) algorithms on cost across every workload we test - so when, if ever, does DRL actually help? We study this in RLScale-Bench, a reproducible benchmark and evaluation protocol for DRL on adaptive resource control, where an agent allocates compute to a dynamic workload under cost and service-level constraints. We evaluate PPO, DQN, A2C, SAC, TD3, and DDPG under matched architectures, training budgets, and reward functions against a calibrated rule-based baseline across six workload patterns and five seeds (240 runs), instantiate the benchmark on Kubernetes Horizontal Pod Autoscaling, and probe distribution-shift generalization. Three findings challenge common assumptions: (i) the calibrated controller achieves the lowest cost on all six workloads, though it trails the best RL agents on bursty and flash traffic; (ii) discrete-action algorithms outperform continuous-action ones by one to two orders of magnitude in constraint violations due to action-space mismatch; and (iii) no single algorithm dominates across workloads, with rankings shifting by up to four positions. The bottleneck in RL-based resource control is not algorithm selection but baseline calibration, reward engineering, and realistic evaluation protocols.
Strategic Maneuver and Disruption with Reinforcement Learning Approaches for Multi-Agent Coordination
Mar 17, 2022
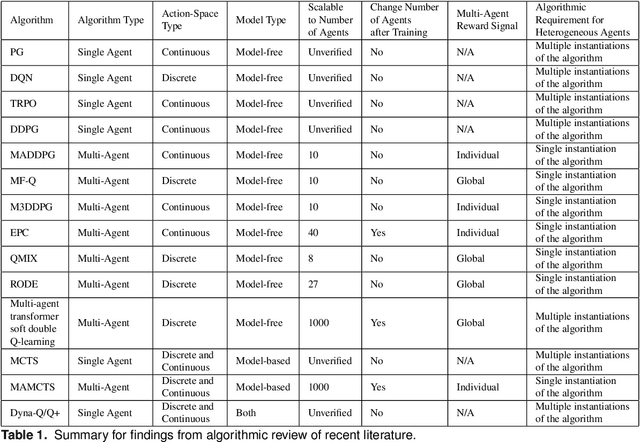
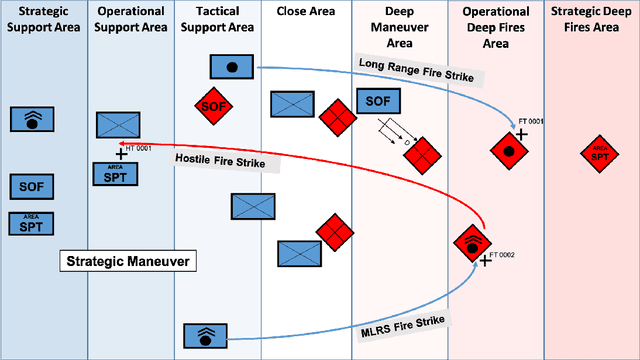
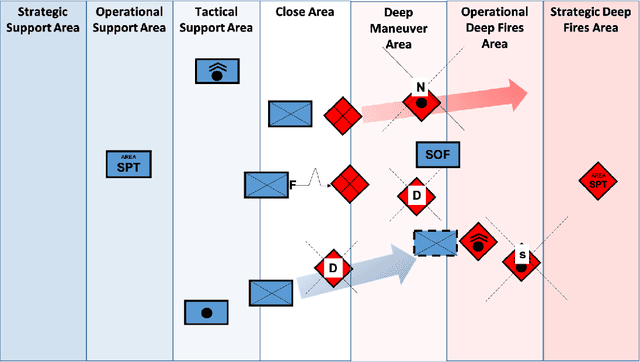
Reinforcement learning (RL) approaches can illuminate emergent behaviors that facilitate coordination across teams of agents as part of a multi-agent system (MAS), which can provide windows of opportunity in various military tasks. Technologically advancing adversaries pose substantial risks to a friendly nation's interests and resources. Superior resources alone are not enough to defeat adversaries in modern complex environments because adversaries create standoff in multiple domains against predictable military doctrine-based maneuvers. Therefore, as part of a defense strategy, friendly forces must use strategic maneuvers and disruption to gain superiority in complex multi-faceted domains such as multi-domain operations (MDO). One promising avenue for implementing strategic maneuver and disruption to gain superiority over adversaries is through coordination of MAS in future military operations. In this paper, we present overviews of prominent works in the RL domain with their strengths and weaknesses for overcoming the challenges associated with performing autonomous strategic maneuver and disruption in military contexts.