 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Minimax Complexity of Stochastic Convex Optimization
May 26, 2016
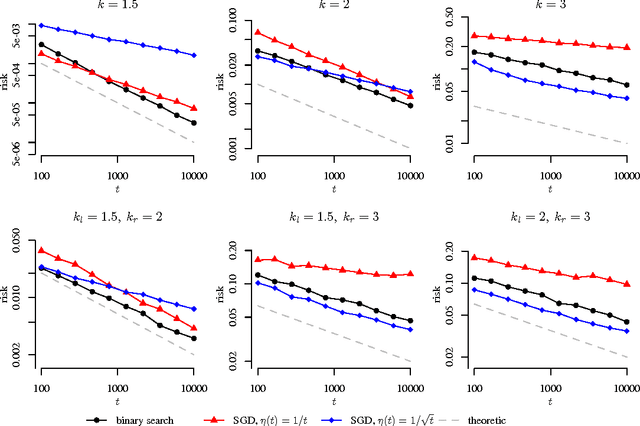
We extend the traditional worst-case, minimax analysis of stochastic convex optimization by introducing a localized form of minimax complexity for individual functions. Our main result gives function-specific lower and upper bounds on the number of stochastic subgradient evaluations needed to optimize either the function or its "hardest local alternative" to a given numerical precision. The bounds are expressed in terms of a localized and computational analogue of the modulus of continuity that is central to statistical minimax analysis. We show how the computational modulus of continuity can be explicitly calculated in concrete cases, and relates to the curvature of the function at the optimum. We also prove a superefficiency result that demonstrates it is a meaningful benchmark, acting as a computational analogue of the Fisher information in statistical estimation. The nature and practical implications of the results are demonstrated in simulations.
Constrained Approximate Maximum Entropy Learning of Markov Random Fields
Jun 13, 2012
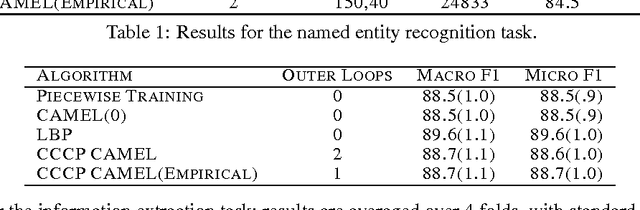

Parameter estimation in Markov random fields (MRFs) is a difficult task, in which inference over the network is run in the inner loop of a gradient descent procedure. Replacing exact inference with approximate methods such as loopy belief propagation (LBP) can suffer from poor convergence. In this paper, we provide a different approach for combining MRF learning and Bethe approximation. We consider the dual of maximum likelihood Markov network learning - maximizing entropy with moment matching constraints - and then approximate both the objective and the constraints in the resulting optimization problem. Unlike previous work along these lines (Teh & Welling, 2003), our formulation allows parameter sharing between features in a general log-linear model, parameter regularization and conditional training. We show that piecewise training (Sutton & McCallum, 2005) is a very restricted special case of this formulation. We study two optimization strategies: one based on a single convex approximation and one that uses repeated convex approximations. We show results on several real-world networks that demonstrate that these algorithms can significantly outperform learning with loopy and piecewise. Our results also provide a framework for analyzing the trade-offs of different relaxations of the entropy objective and of the constraints.
Projected Subgradient Methods for Learning Sparse Gaussians
Jun 13, 2012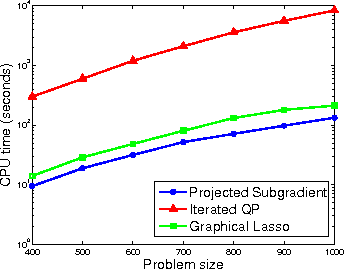
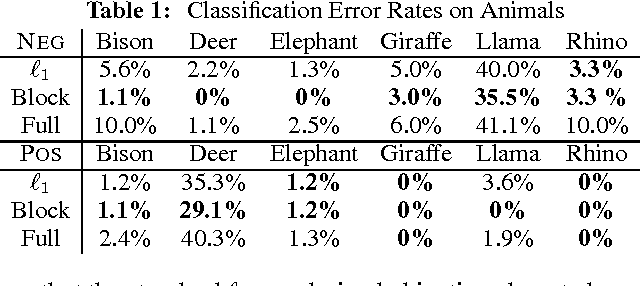
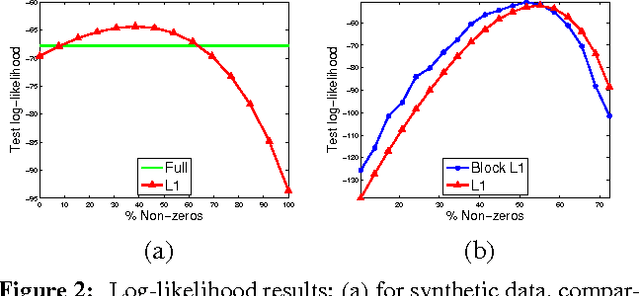
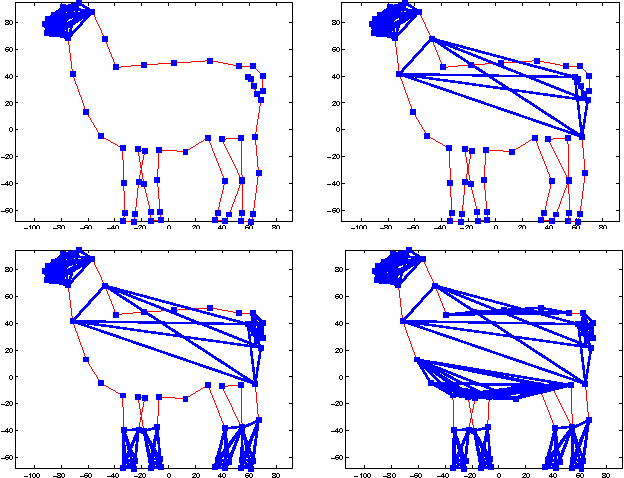
Gaussian Markov random fields (GMRFs) are useful in a broad range of applications. In this paper we tackle the problem of learning a sparse GMRF in a high-dimensional space. Our approach uses the l1-norm as a regularization on the inverse covariance matrix. We utilize a novel projected gradient method, which is faster than previous methods in practice and equal to the best performing of these in asymptotic complexity. We also extend the l1-regularized objective to the problem of sparsifying entire blocks within the inverse covariance matrix. Our methods generalize fairly easily to this case, while other methods do not. We demonstrate that our extensions give better generalization performance on two real domains--biological network analysis and a 2D-shape modeling image task.
Dual Averaging for Distributed Optimization: Convergence Analysis and Network Scaling
Apr 10, 2011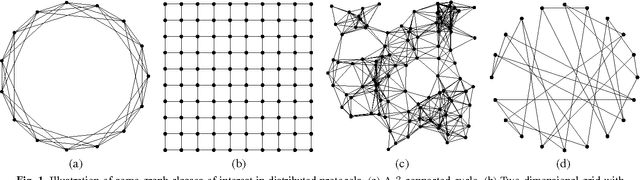
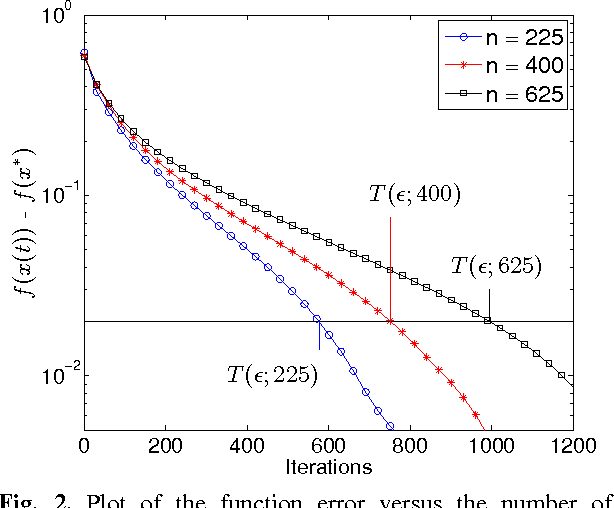
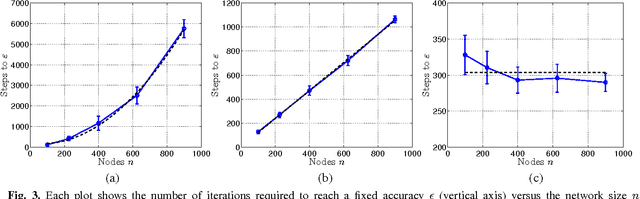
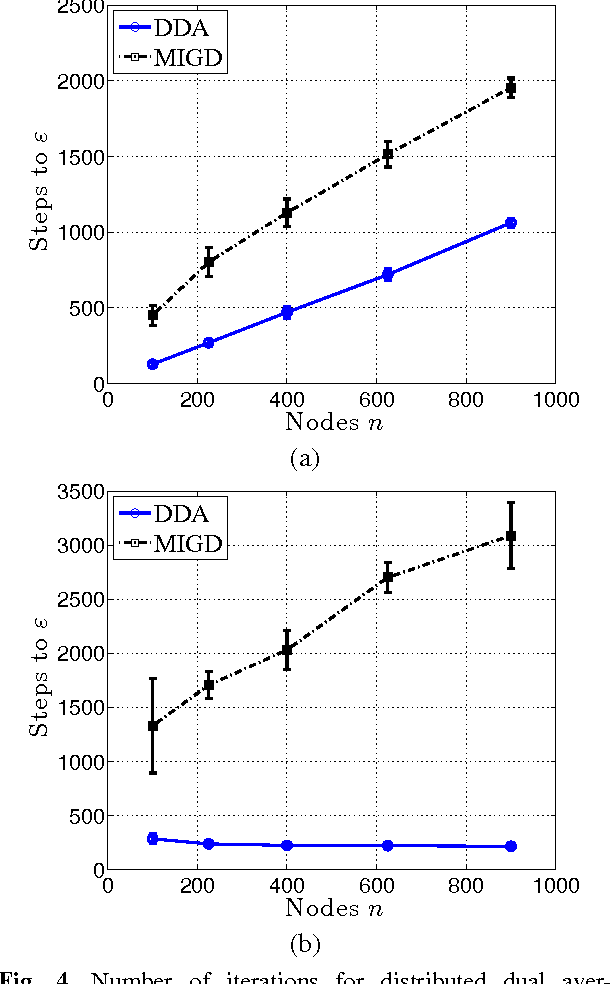
The goal of decentralized optimization over a network is to optimize a global objective formed by a sum of local (possibly nonsmooth) convex functions using only local computation and communication. It arises in various application domains, including distributed tracking and localization, multi-agent co-ordination, estimation in sensor networks, and large-scale optimization in machine learning. We develop and analyze distributed algorithms based on dual averaging of subgradients, and we provide sharp bounds on their convergence rates as a function of the network size and topology. Our method of analysis allows for a clear separation between the convergence of the optimization algorithm itself and the effects of communication constraints arising from the network structure. In particular, we show that the number of iterations required by our algorithm scales inversely in the spectral gap of the network. The sharpness of this prediction is confirmed both by theoretical lower bounds and simulations for various networks. Our approach includes both the cases of deterministic optimization and communication, as well as problems with stochastic optimization and/or communication.
* 40 pages, 4 figures