 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-AI Collaborative Multi-modal Multi-rater Learning for Endometriosis Diagnosis
Sep 03, 2024Endometriosis, affecting about 10\% of individuals assigned female at birth, is challenging to diagnose and manage. Diagnosis typically involves the identification of various signs of the disease using either laparoscopic surgery or the analysis of T1/T2 MRI images, with the latter being quicker and cheaper but less accurate. A key diagnostic sign of endometriosis is the obliteration of the Pouch of Douglas (POD). However, even experienced clinicians struggle with accurately classifying POD obliteration from MRI images, which complicates the training of reliable AI models. In this paper, we introduce the \underline{H}uman-\underline{AI} \underline{Co}llaborative \underline{M}ulti-modal \underline{M}ulti-rater Learning (HAICOMM) methodology to address the challenge above. HAICOMM is the first method that explores three important aspects of this problem: 1) multi-rater learning to extract a cleaner label from the multiple ``noisy'' labels available per training sample; 2) multi-modal learning to leverage the presence of T1/T2 MRI images for training and testing; and 3) human-AI collaboration to build a system that leverages the predictions from clinicians and the AI model to provide more accurate classification than standalone clinicians and AI models. Presenting results on the multi-rater T1/T2 MRI endometriosis dataset that we collected to validate our methodology, the proposed HAICOMM model outperforms an ensemble of clinicians, noisy-label learning models, and multi-rater learning methods.
Enhancing Multi-modal Learning: Meta-learned Cross-modal Knowledge Distillation for Handling Missing Modalities
May 12, 2024



In multi-modal learning, some modalities are more influential than others, and their absence can have a significant impact on classification/segmentation accuracy. Hence, an important research question is if it is possible for trained multi-modal models to have high accuracy even when influential modalities are absent from the input data. In this paper, we propose a novel approach called Meta-learned Cross-modal Knowledge Distillation (MCKD) to address this research question. MCKD adaptively estimates the importance weight of each modality through a meta-learning process. These dynamically learned modality importance weights are used in a pairwise cross-modal knowledge distillation process to transfer the knowledge from the modalities with higher importance weight to the modalities with lower importance weight. This cross-modal knowledge distillation produces a highly accurate model even with the absence of influential modalities. Differently from previous methods in the field, our approach is designed to work in multiple tasks (e.g., segmentation and classification) with minimal adaptation. Experimental results on the Brain tumor Segmentation Dataset 2018 (BraTS2018) and the Audiovision-MNIST classification dataset demonstrate the superiority of MCKD over current state-of-the-art models. Particularly in BraTS2018, we achieve substantial improvements of 3.51\% for enhancing tumor, 2.19\% for tumor core, and 1.14\% for the whole tumor in terms of average segmentation Dice score.
Learnable Cross-modal Knowledge Distillation for Multi-modal Learning with Missing Modality
Oct 02, 2023The problem of missing modalities is both critical and non-trivial to be handled in multi-modal models. It is common for multi-modal tasks that certain modalities contribute more compared to other modalities, and if those important modalities are missing, the model performance drops significantly. Such fact remains unexplored by current multi-modal approaches that recover the representation from missing modalities by feature reconstruction or blind feature aggregation from other modalities, instead of extracting useful information from the best performing modalities. In this paper, we propose a Learnable Cross-modal Knowledge Distillation (LCKD) model to adaptively identify important modalities and distil knowledge from them to help other modalities from the cross-modal perspective for solving the missing modality issue. Our approach introduces a teacher election procedure to select the most ``qualified'' teachers based on their single modality performance on certain tasks. Then, cross-modal knowledge distillation is performed between teacher and student modalities for each task to push the model parameters to a point that is beneficial for all tasks. Hence, even if the teacher modalities for certain tasks are missing during testing, the available student modalities can accomplish the task well enough based on the learned knowledge from their automatically elected teacher modalities. Experiments on the Brain Tumour Segmentation Dataset 2018 (BraTS2018) shows that LCKD outperforms other methods by a considerable margin, improving the state-of-the-art performance by 3.61% for enhancing tumour, 5.99% for tumour core, and 3.76% for whole tumour in terms of segmentation Dice score.
Multi-modal Learning with Missing Modality via Shared-Specific Feature Modelling
Jul 26, 2023



The missing modality issue is critical but non-trivial to be solved by multi-modal models. Current methods aiming to handle the missing modality problem in multi-modal tasks, either deal with missing modalities only during evaluation or train separate models to handle specific missing modality settings. In addition, these models are designed for specific tasks, so for example, classification models are not easily adapted to segmentation tasks and vice versa. In this paper, we propose the Shared-Specific Feature Modelling (ShaSpec) method that is considerably simpler and more effective than competing approaches that address the issues above. ShaSpec is designed to take advantage of all available input modalities during training and evaluation by learning shared and specific features to better represent the input data. This is achieved from a strategy that relies on auxiliary tasks based on distribution alignment and domain classification, in addition to a residual feature fusion procedure. Also, the design simplicity of ShaSpec enables its easy adaptation to multiple tasks, such as classification and segmentation. Experiments are conducted on both medical image segmentation and computer vision classification, with results indicating that ShaSpec outperforms competing methods by a large margin. For instance, on BraTS2018, ShaSpec improves the SOTA by more than 3% for enhancing tumour, 5% for tumour core and 3% for whole tumour.
Distilling Missing Modality Knowledge from Ultrasound for Endometriosis Diagnosis with Magnetic Resonance Images
Jul 05, 2023


Endometriosis is a common chronic gynecological disorder that has many characteristics, including the pouch of Douglas (POD) obliteration, which can be diagnosed using Transvaginal gynecological ultrasound (TVUS) scans and magnetic resonance imaging (MRI). TVUS and MRI are complementary non-invasive endometriosis diagnosis imaging techniques, but patients are usually not scanned using both modalities and, it is generally more challenging to detect POD obliteration from MRI than TVUS. To mitigate this classification imbalance, we propose in this paper a knowledge distillation training algorithm to improve the POD obliteration detection from MRI by leveraging the detection results from unpaired TVUS data. More specifically, our algorithm pre-trains a teacher model to detect POD obliteration from TVUS data, and it also pre-trains a student model with 3D masked auto-encoder using a large amount of unlabelled pelvic 3D MRI volumes. Next, we distill the knowledge from the teacher TVUS POD obliteration detector to train the student MRI model by minimizing a regression loss that approximates the output of the student to the teacher using unpaired TVUS and MRI data. Experimental results on our endometriosis dataset containing TVUS and MRI data demonstrate the effectiveness of our method to improve the POD detection accuracy from MRI.
Uncertainty-aware Multi-modal Learning via Cross-modal Random Network Prediction
Jul 22, 2022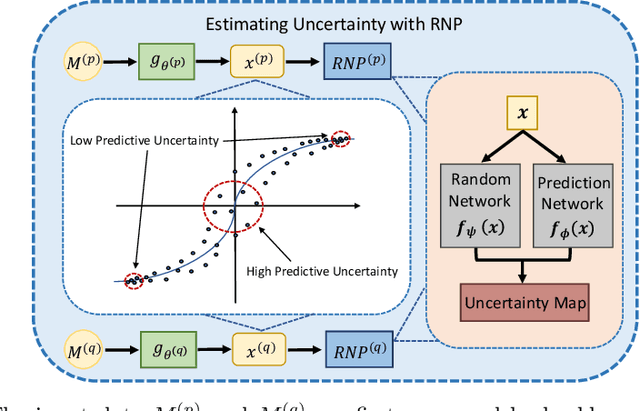
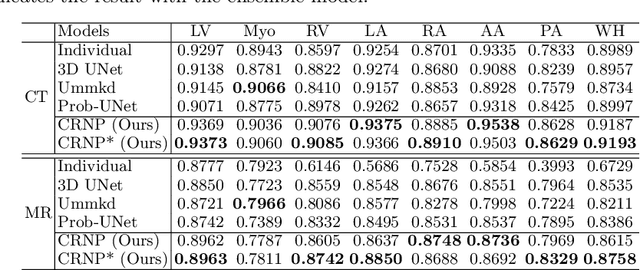
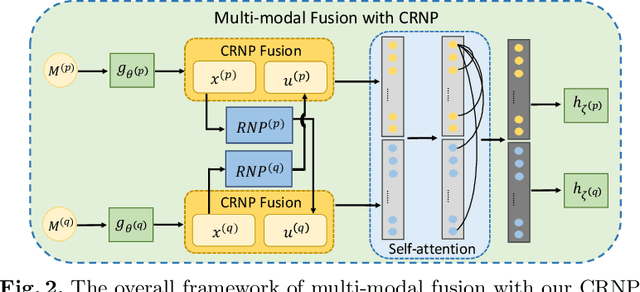
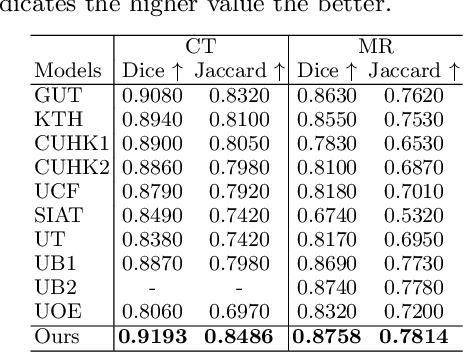
Multi-modal learning focuses on training models by equally combining multiple input data modalities during the prediction process. However, this equal combination can be detrimental to the prediction accuracy because different modalities are usually accompanied by varying levels of uncertainty. Using such uncertainty to combine modalities has been studied by a couple of approaches, but with limited success because these approaches are either designed to deal with specific classification or segmentation problems and cannot be easily translated into other tasks, or suffer from numerical instabilities. In this paper, we propose a new Uncertainty-aware Multi-modal Learner that estimates uncertainty by measuring feature density via Cross-modal Random Network Prediction (CRNP). CRNP is designed to require little adaptation to translate between different prediction tasks, while having a stable training process. From a technical point of view, CRNP is the first approach to explore random network prediction to estimate uncertainty and to combine multi-modal data. Experiments on two 3D multi-modal medical image segmentation tasks and three 2D multi-modal computer vision classification tasks show the effectiveness, adaptability and robustness of CRNP. Also, we provide an extensive discussion on different fusion functions and visualization to validate the proposed model.