 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCroissant Baker: Metadata Generation for Discoverable, Governable, and Reusable ML Datasets
May 14, 2026Croissant has emerged as the metadata standard for machine learning datasets, providing a structured, JSON-LD-based format that makes dataset discovery, automated ingestion, and reproducible analysis machine-checkable across ML platforms. Adoption has accelerated, and NeurIPS now requires Croissant metadata in every submission to its dataset tracks. Yet in practice Croissant generation usually starts with uploading data to a public platform, a path infeasible for governed and large local repositories that hold much of the high-value data ML increasingly relies on. We release Croissant Baker, a local-first, open-source command-line tool that generates validated Croissant metadata directly from a dataset directory through a modular handler registry. We evaluate Croissant Baker on over 140 datasets, scaling to MIMIC-IV at 886 million rows and 374 Parquet files. On held-out comparisons against producer-authored or standards-derived ground truth, Croissant Baker reaches 97-100% agreement across multiple domains.
When AI Meets Science: Research Diversity, Interdisciplinarity, Visibility, and Retractions across Disciplines in a Global Surge
May 07, 2026The extent to which Artificial Intelligence (AI) can trigger generalized paradigm shifts in science is unclear. Although some of these technologies have revolutionized data collection and analysis in specific scientific fields such as Chemistry, their overall impact depends on the scope of adoption and the ways scholars use them. In this study, we document substantial differences in the timing and extent of AI adoption across countries and scientific domains from 1960 to 2015. After 2015, we find generalized exponential growth in AI adoption, with the number of AI-supported works multiplying by at least four across all domains. The transformative nature of this rapid growth is less apparent and points to multiple challenges should adoption trends persist. According to our analyses, AI-supported research is confined to very few topics with strong ties to Computer Science and conventional statistical frameworks, suggesting limited transformational potential in epistemological terms. AI-supported works are also associated with an unwarranted citation premium and exhibit substantially higher retraction rates than non-AI-supported works across most fields. Geographically, AI adoption displays pronounced heterogeneity at the country level, along with an acceleration in the relevance of middle-income countries in Asia, from China and beyond. Thus, the transformative capacity of AI in science remains largely untapped, and its rapid adoption underlines challenges in research openness, transparency, reproducibility, and ethics from a global perspective. We discuss how best research practices could boost the benefits of AI adoption and highlight fields and geographies where these trends warrant closer scrutiny.
Croissant: A Metadata Format for ML-Ready Datasets
Mar 28, 2024Data is a critical resource for Machine Learning (ML), yet working with data remains a key friction point. This paper introduces Croissant, a metadata format for datasets that simplifies how data is used by ML tools and frameworks. Croissant makes datasets more discoverable, portable and interoperable, thereby addressing significant challenges in ML data management and responsible AI. Croissant is already supported by several popular dataset repositories, spanning hundreds of thousands of datasets, ready to be loaded into the most popular ML frameworks.
On the Readiness of Scientific Data for a Fair and Transparent Use in Machine Learning
Jan 18, 2024



To ensure the fairness and trustworthiness of machine learning (ML) systems, recent legislative initiatives and relevant research in the ML community have pointed out the need to document the data used to train ML models. Besides, data-sharing practices in many scientific domains have evolved in recent years for reproducibility purposes. In this sense, the adoption of these practices by academic institutions has encouraged researchers to publish their data and technical documentation in peer-reviewed publications such as data papers. In this study, we analyze how this scientific data documentation meets the needs of the ML community and regulatory bodies for its use in ML technologies. We examine a sample of 4041 data papers of different domains, assessing their completeness and coverage of the requested dimensions, and trends in recent years, putting special emphasis on the most and least documented dimensions. As a result, we propose a set of recommendation guidelines for data creators and scientific data publishers to increase their data's preparedness for its transparent and fairer use in ML technologies.
A domain-specific language for describing machine learning datasets
Jul 08, 2022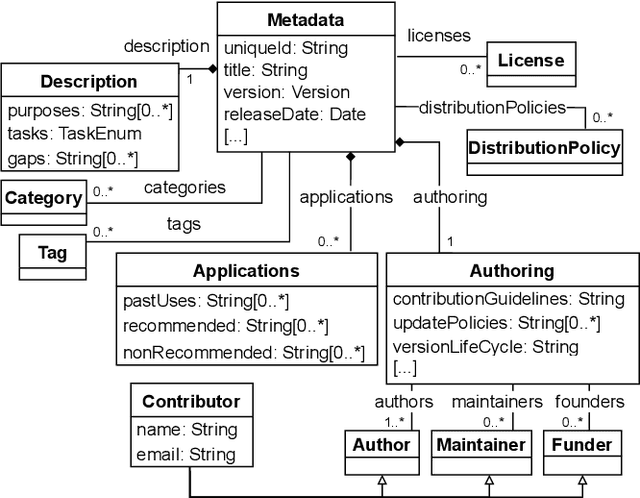
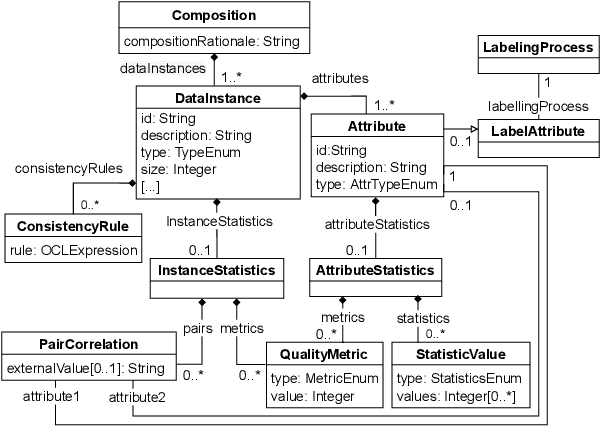
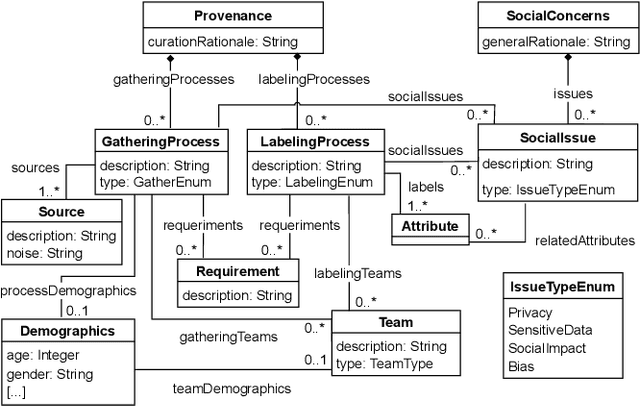
Datasets play a central role in the training and evaluation of machine learning (ML) models. But they are also the root cause of many undesired model behaviors, such as biased predictions. To overcome this situation, the ML community is proposing a data-centric cultural shift where data issues are given the attention they deserve, and more standard practices around the gathering and processing of datasets start to be discussed and established. So far, these proposals are mostly high-level guidelines described in natural language and, as such, they are difficult to formalize and apply to particular datasets. In this sense, and inspired by these proposals, we define a new domain-specific language (DSL) to precisely describe machine learning datasets in terms of their structure, data provenance, and social concerns. We believe this DSL will facilitate any ML initiative to leverage and benefit from this data-centric shift in ML (e.g., selecting the most appropriate dataset for a new project or better replicating other ML results). The DSL is implemented as a Visual Studio Code plugin, and it has been published under an open source license.