 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Aided Consistency for Weakly Supervised Phrase Grounding
Mar 11, 2018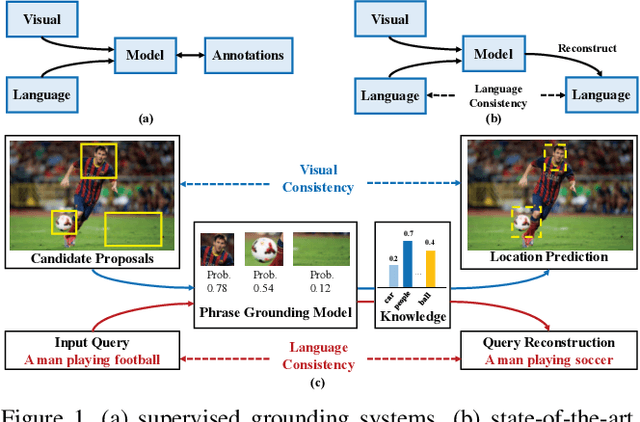
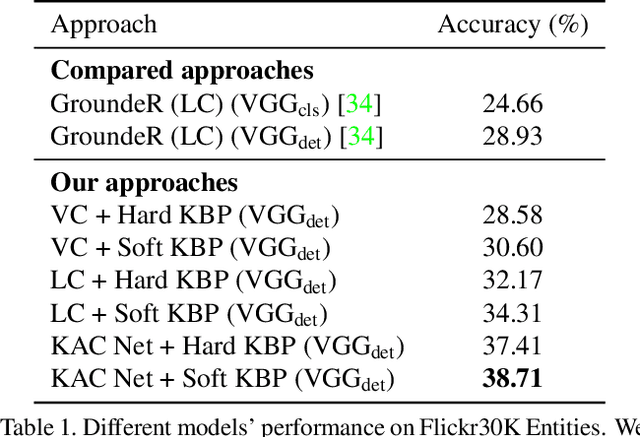
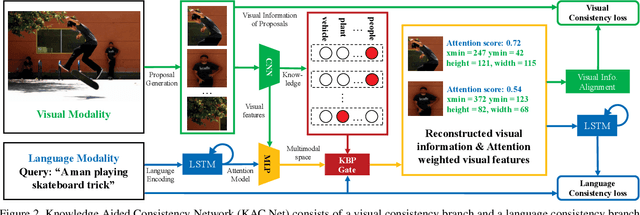

Given a natural language query, a phrase grounding system aims to localize mentioned objects in an image. In weakly supervised scenario, mapping between image regions (i.e., proposals) and language is not available in the training set. Previous methods address this deficiency by training a grounding system via learning to reconstruct language information contained in input queries from predicted proposals. However, the optimization is solely guided by the reconstruction loss from the language modality, and ignores rich visual information contained in proposals and useful cues from external knowledge. In this paper, we explore the consistency contained in both visual and language modalities, and leverage complementary external knowledge to facilitate weakly supervised grounding. We propose a novel Knowledge Aided Consistency Network (KAC Net) which is optimized by reconstructing input query and proposal's information. To leverage complementary knowledge contained in the visual features, we introduce a Knowledge Based Pooling (KBP) gate to focus on query-related proposals. Experiments show that KAC Net provides a significant improvement on two popular datasets.
Knowledge Concentration: Learning 100K Object Classifiers in a Single CNN
Nov 23, 2017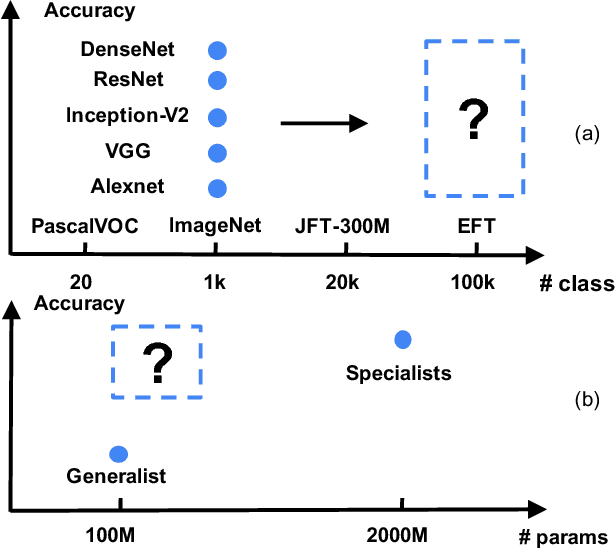

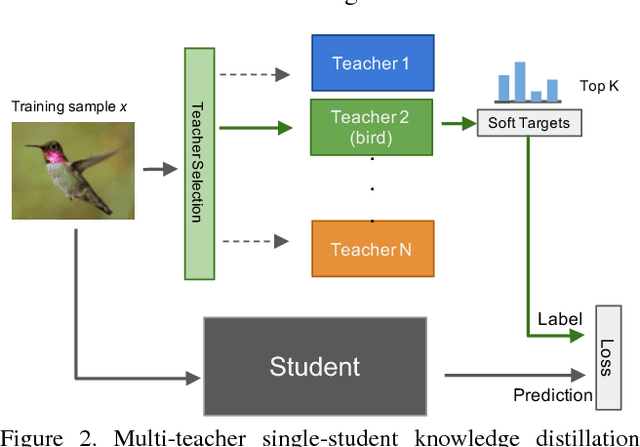

Fine-grained image labels are desirable for many computer vision applications, such as visual search or mobile AI assistant. These applications rely on image classification models that can produce hundreds of thousands (e.g. 100K) of diversified fine-grained image labels on input images. However, training a network at this vocabulary scale is challenging, and suffers from intolerable large model size and slow training speed, which leads to unsatisfying classification performance. A straightforward solution would be training separate expert networks (specialists), with each specialist focusing on learning one specific vertical (e.g. cars, birds...). However, deploying dozens of expert networks in a practical system would significantly increase system complexity and inference latency, and consumes large amounts of computational resources. To address these challenges, we propose a Knowledge Concentration method, which effectively transfers the knowledge from dozens of specialists (multiple teacher networks) into one single model (one student network) to classify 100K object categories. There are three salient aspects in our method: (1) a multi-teacher single-student knowledge distillation framework; (2) a self-paced learning mechanism to allow the student to learn from different teachers at various paces; (3) structurally connected layers to expand the student network capacity with limited extra parameters. We validate our method on OpenImage and a newly collected dataset, Entity-Foto-Tree (EFT), with 100K categories, and show that the proposed model performs significantly better than the baseline generalist model.
TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals
Aug 04, 2017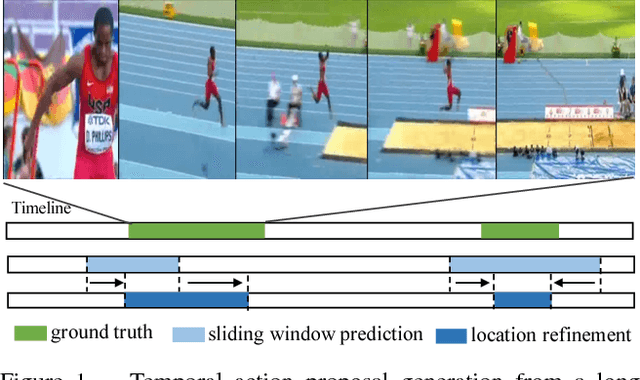
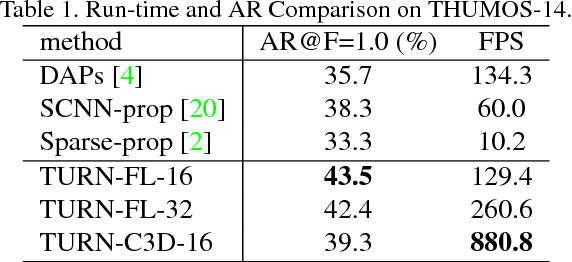
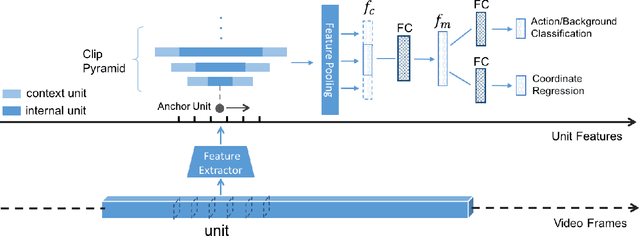
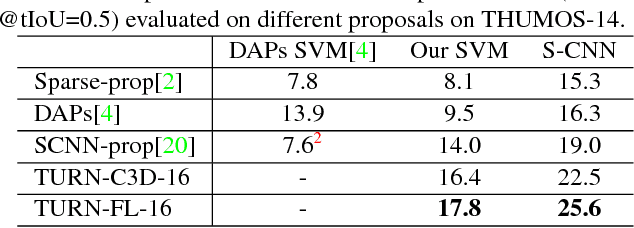
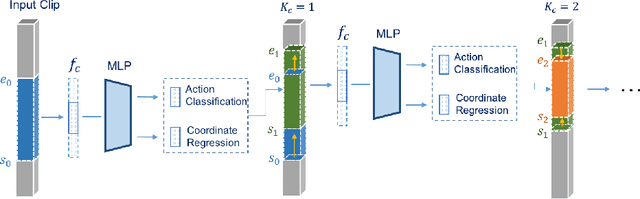
Temporal Action Proposal (TAP) generation is an important problem, as fast and accurate extraction of semantically important (e.g. human actions) segments from untrimmed videos is an important step for large-scale video analysis. We propose a novel Temporal Unit Regression Network (TURN) model. There are two salient aspects of TURN: (1) TURN jointly predicts action proposals and refines the temporal boundaries by temporal coordinate regression; (2) Fast computation is enabled by unit feature reuse: a long untrimmed video is decomposed into video units, which are reused as basic building blocks of temporal proposals. TURN outperforms the state-of-the-art methods under average recall (AR) by a large margin on THUMOS-14 and ActivityNet datasets, and runs at over 880 frames per second (FPS) on a TITAN X GPU. We further apply TURN as a proposal generation stage for existing temporal action localization pipelines, it outperforms state-of-the-art performance on THUMOS-14 and ActivityNet.
TALL: Temporal Activity Localization via Language Query
Aug 03, 2017

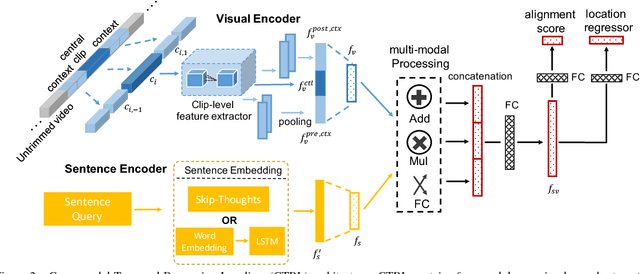
This paper focuses on temporal localization of actions in untrimmed videos. Existing methods typically train classifiers for a pre-defined list of actions and apply them in a sliding window fashion. However, activities in the wild consist of a wide combination of actors, actions and objects; it is difficult to design a proper activity list that meets users' needs. We propose to localize activities by natural language queries. Temporal Activity Localization via Language (TALL) is challenging as it requires: (1) suitable design of text and video representations to allow cross-modal matching of actions and language queries; (2) ability to locate actions accurately given features from sliding windows of limited granularity. We propose a novel Cross-modal Temporal Regression Localizer (CTRL) to jointly model text query and video clips, output alignment scores and action boundary regression results for candidate clips. For evaluation, we adopt TaCoS dataset, and build a new dataset for this task on top of Charades by adding sentence temporal annotations, called Charades-STA. We also build complex sentence queries in Charades-STA for test. Experimental results show that CTRL outperforms previous methods significantly on both datasets.
Spatio-Temporal Action Detection with Cascade Proposal and Location Anticipation
Jul 31, 2017
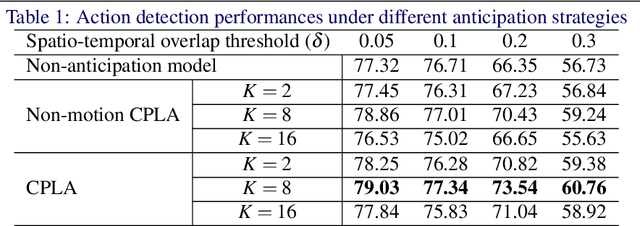
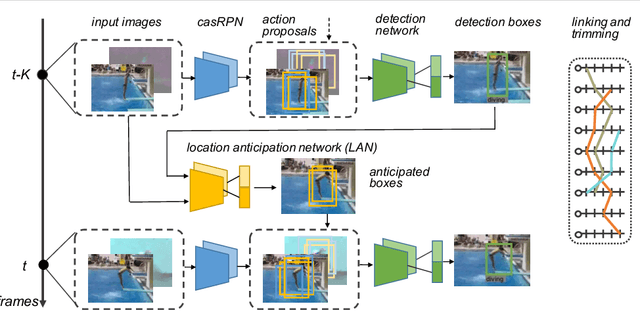
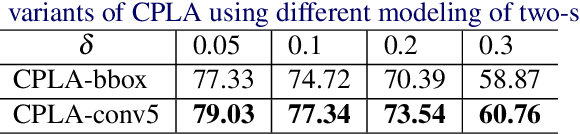
In this work, we address the problem of spatio-temporal action detection in temporally untrimmed videos. It is an important and challenging task as finding accurate human actions in both temporal and spatial space is important for analyzing large-scale video data. To tackle this problem, we propose a cascade proposal and location anticipation (CPLA) model for frame-level action detection. There are several salient points of our model: (1) a cascade region proposal network (casRPN) is adopted for action proposal generation and shows better localization accuracy compared with single region proposal network (RPN); (2) action spatio-temporal consistencies are exploited via a location anticipation network (LAN) and thus frame-level action detection is not conducted independently. Frame-level detections are then linked by solving an linking score maximization problem, and temporally trimmed into spatio-temporal action tubes. We demonstrate the effectiveness of our model on the challenging UCF101 and LIRIS-HARL datasets, both achieving state-of-the-art performance.
RED: Reinforced Encoder-Decoder Networks for Action Anticipation
Jul 16, 2017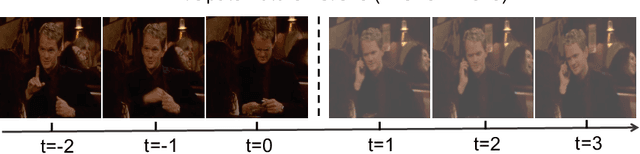

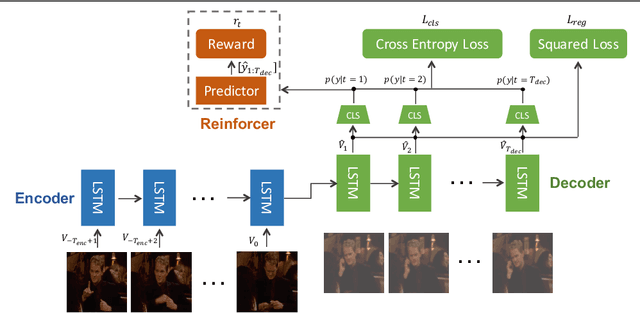
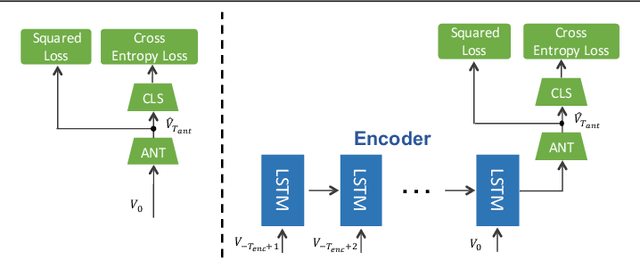
Action anticipation aims to detect an action before it happens. Many real world applications in robotics and surveillance are related to this predictive capability. Current methods address this problem by first anticipating visual representations of future frames and then categorizing the anticipated representations to actions. However, anticipation is based on a single past frame's representation, which ignores the history trend. Besides, it can only anticipate a fixed future time. We propose a Reinforced Encoder-Decoder (RED) network for action anticipation. RED takes multiple history representations as input and learns to anticipate a sequence of future representations. One salient aspect of RED is that a reinforcement module is adopted to provide sequence-level supervision; the reward function is designed to encourage the system to make correct predictions as early as possible. We test RED on TVSeries, THUMOS-14 and TV-Human-Interaction datasets for action anticipation and achieve state-of-the-art performance on all datasets.
Cascaded Boundary Regression for Temporal Action Detection
May 02, 2017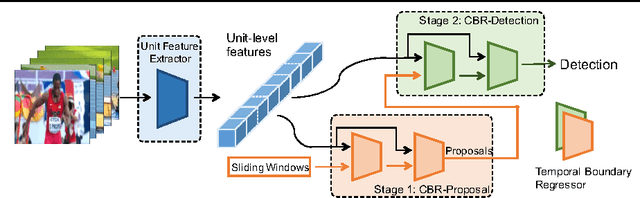
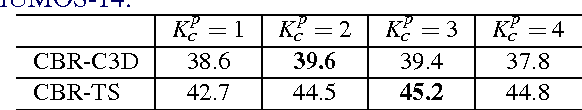
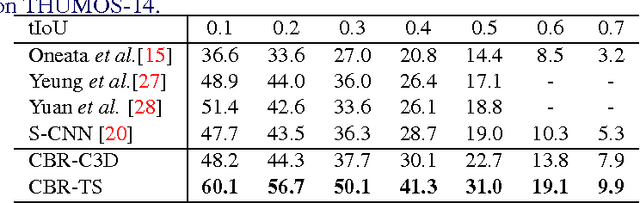
Temporal action detection in long videos is an important problem. State-of-the-art methods address this problem by applying action classifiers on sliding windows. Although sliding windows may contain an identifiable portion of the actions, they may not necessarily cover the entire action instance, which would lead to inferior performance. We adapt a two-stage temporal action detection pipeline with Cascaded Boundary Regression (CBR) model. Class-agnostic proposals and specific actions are detected respectively in the first and the second stage. CBR uses temporal coordinate regression to refine the temporal boundaries of the sliding windows. The salient aspect of the refinement process is that, inside each stage, the temporal boundaries are adjusted in a cascaded way by feeding the refined windows back to the system for further boundary refinement. We test CBR on THUMOS-14 and TVSeries, and achieve state-of-the-art performance on both datasets. The performance gain is especially remarkable under high IoU thresholds, e.g. map@tIoU=0.5 on THUMOS-14 is improved from 19.0% to 31.0%.
Learning Action Concept Trees and Semantic Alignment Networks from Image-Description Data
Sep 08, 2016

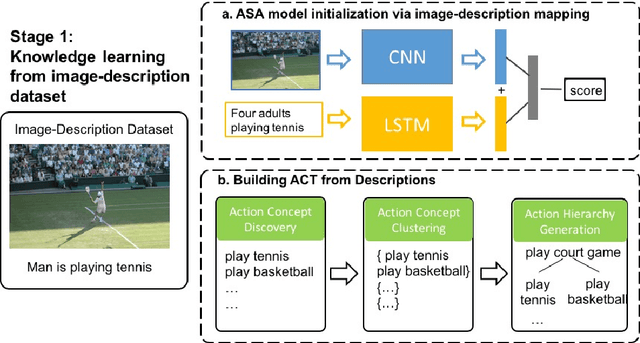
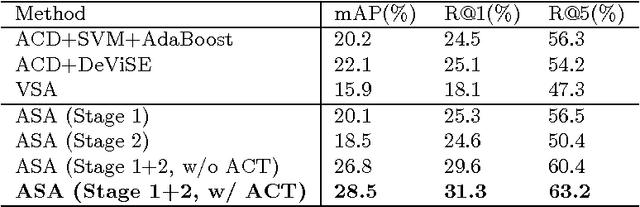
Action classification in still images has been a popular research topic in computer vision. Labelling large scale datasets for action classification requires tremendous manual work, which is hard to scale up. Besides, the action categories in such datasets are pre-defined and vocabularies are fixed. However humans may describe the same action with different phrases, which leads to the difficulty of vocabulary expansion for traditional fully-supervised methods. We observe that large amounts of images with sentence descriptions are readily available on the Internet. The sentence descriptions can be regarded as weak labels for the images, which contain rich information and could be used to learn flexible expressions of action categories. We propose a method to learn an Action Concept Tree (ACT) and an Action Semantic Alignment (ASA) model for classification from image-description data via a two-stage learning process. A new dataset for the task of learning actions from descriptions is built. Experimental results show that our method outperforms several baseline methods significantly.
ACD: Action Concept Discovery from Image-Sentence Corpora
Apr 16, 2016
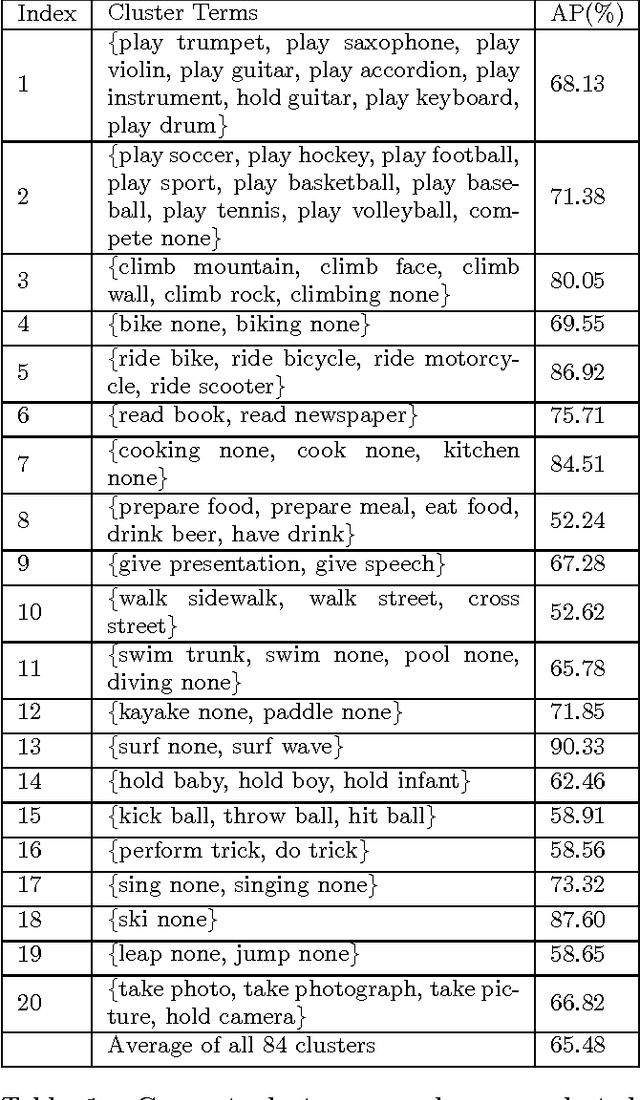
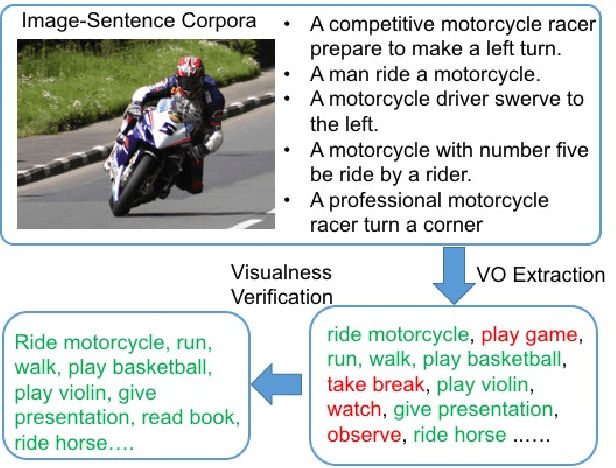

Action classification in still images is an important task in computer vision. It is challenging as the appearances of ac- tions may vary depending on their context (e.g. associated objects). Manually labeling of context information would be time consuming and difficult to scale up. To address this challenge, we propose a method to automatically discover and cluster action concepts, and learn their classifiers from weakly supervised image-sentence corpora. It obtains candidate action concepts by extracting verb-object pairs from sentences and verifies their visualness with the associated images. Candidate action concepts are then clustered by using a multi-modal representation with image embeddings from deep convolutional networks and text embeddings from word2vec. More than one hundred human action concept classifiers are learned from the Flickr 30k dataset with no additional human effort and promising classification results are obtained. We further apply the AdaBoost algorithm to automatically select and combine relevant action concepts given an action query. Promising results have been shown on the PASCAL VOC 2012 action classification benchmark, which has zero overlap with Flickr30k.