 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Predictive Communication for Timely Status Updates in Low-Altitude Networks
Apr 22, 2026Timely information delivery in low-altitude networks is critical for many time-sensitive applications, such as unmanned aerial vehicle (UAV) navigation, inspection, and surveillance. The key challenge lies in balancing three competing factors: stringent data freshness requirements, UAV onboard energy consumption, and interference with terrestrial services. Addressing this challenge requires not only efficient power and channel allocation strategies but also effective communication timing over the entire operation horizon. In this work, we propose a model predictive communication (MPComm) framework, enabled by advanced channel sensing techniques, in which the channel conditions that the UAV will experience are largely predictable. Within this framework, we formulate a constrained bi-objective optimization problem to achieve a desired trade-off between energy consumption and terrestrial channel occupation, subject to a strict timeliness constraint. We solve this problem using Pareto analysis and show that the original non-convex, mixed-integer problem can be decomposed into a two-layer structure: the outer layer determines the optimal communication timing, while the inner layer determines the optimal power and channel allocation for each communication interval. An efficient algorithm for the inner problem is developed using non-convex analysis, with asymptotic optimality guarantees, while the outer problem is solved optimally via a simple graph search, with edges characterized by inner solutions. The proposed approach applies to a broad class of problem variants, including objective transformations and single-objective specializations. Numerical results demonstrate the efficiency of the proposed solution, achieving up to a six-fold reduction in terrestrial channel occupation and a 6dB energy saving compared to benchmark schemes.
Computing the Exact Pareto Front in Average-Cost Multi-Objective Markov Decision Processes
Apr 02, 2026Many communication and control problems are cast as multi-objective Markov decision processes (MOMDPs). The complete solution to an MOMDP is the Pareto front. Much of the literature approximates this front via scalarization into single-objective MDPs. Recent work has begun to characterize the full front in discounted or simple bi-objective settings by exploiting its geometry. In this work, we characterize the exact front in average-cost MOMDPs. We show that the front is a continuous, piecewise-linear surface lying on the boundary of a convex polytope. Each vertex corresponds to a deterministic policy, and adjacent vertices differ in exactly one state. Each edge is realized as a convex combination of the policies at its endpoints, with the mixing coefficient given in closed form. We apply these results to a remote state estimation problem, where each vertex on the front corresponds to a threshold policy. The exact Pareto front and solutions to certain non-convex MDPs can be obtained without explicitly solving any MDP.
Pareto-Optimal Sampling and Resource Allocation for Timely Communication in Shared-Spectrum Low-Altitude Networks
Oct 30, 2025Guaranteeing stringent data freshness for low-altitude unmanned aerial vehicles (UAVs) in shared spectrum forces a critical trade-off between two operational costs: the UAV's own energy consumption and the occupation of terrestrial channel resources. The core challenge is to satisfy the aerial data freshness while finding a Pareto-optimal balance between these costs. Leveraging predictive channel models and predictive UAV trajectories, we formulate a bi-objective Pareto optimization problem over a long-term planning horizon to jointly optimize the sampling timing for aerial traffic and the power and spectrum allocation for fair coexistence. However, the problem's non-convex, mixed-integer nature renders classical methods incapable of fully characterizing the complete Pareto frontier. Notably, we show monotonicity properties of the frontier, building on which we transform the bi-objective problem into several single-objective problems. We then propose a new graph-based algorithm and prove that it can find the complete set of Pareto optima with low complexity, linear in the horizon and near-quadratic in the resource block (RB) budget. Numerical comparisons show that our approach meets the stringent timeliness requirement and achieves a six-fold reduction in RB utilization or a 6 dB energy saving compared to benchmarks.
Semantic-Aware Remote Estimation of Multiple Markov Sources Under Constraints
Mar 25, 2024



This paper studies semantic-aware communication for remote estimation of multiple Markov sources over a lossy and rate-constrained channel. Unlike most existing studies that treat all source states equally, we exploit the semantics of information and consider that the remote actuator has different tolerances for the estimation errors of different states. We aim to find an optimal scheduling policy that minimizes the long-term state-dependent costs of estimation errors under a transmission frequency constraint. We theoretically show the structure of the optimal policy by leveraging the average-cost Constrained Markov Decision Process (CMDP) theory and the Lagrangian dynamic programming. By exploiting the optimal structural results, we develop a novel policy search algorithm, termed intersection search plus relative value iteration (Insec-RVI), that can find the optimal policy using only a few iterations. To avoid the ``curse of dimensionality'' of MDPs, we propose an online low-complexity drift-plus-penalty (DPP) scheduling algorithm based on the Lyapunov optimization theorem. We also design an efficient average-cost Q-learning algorithm to estimate the optimal policy without knowing a priori the channel and source statistics. Numerical results show that continuous transmission is inefficient, and remarkably, our semantic-aware policies can attain the optimum by strategically utilizing fewer transmissions by exploiting the timing of the important information.
A Tightly Coupled Bi-Level Coordination Framework for CAVs at Road Intersections
Feb 07, 2023



Since the traffic administration at road intersections determines the capacity bottleneck of modern transportation systems, intelligent cooperative coordination for connected autonomous vehicles (CAVs) has shown to be an effective solution. In this paper, we try to formulate a Bi-Level CAV intersection coordination framework, where coordinators from High and Low levels are tightly coupled. In the High-Level coordinator where vehicles from multiple roads are involved, we take various metrics including throughput, safety, fairness and comfort into consideration. Motivated by the time consuming space-time resource allocation framework in [1], we try to give a low complexity solution by transforming the complicated original problem into a sequential linear programming one. Based on the "feasible tunnels" (FT) generated from the High-Level coordinator, we then propose a rapid gradient-based trajectory optimization strategy in the Low-Level planner, to effectively avoid collisions beyond High-level considerations, such as the pedestrian or bicycles. Simulation results and laboratory experiments show that our proposed method outperforms existing strategies. Moreover, the most impressive advantage is that the proposed strategy can plan vehicle trajectory in milliseconds, which is promising in realworld deployments. A detailed description include the coordination framework and experiment demo could be found at the supplement materials, or online at https://youtu.be/MuhjhKfNIOg.
Real-time Cooperative Vehicle Coordination at Unsignalized Road Intersections
May 03, 2022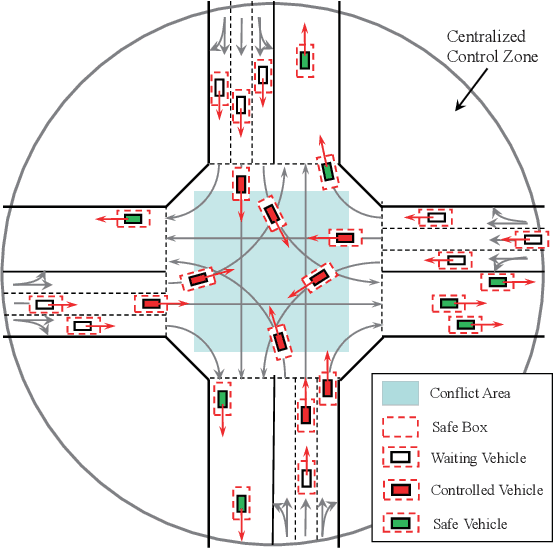
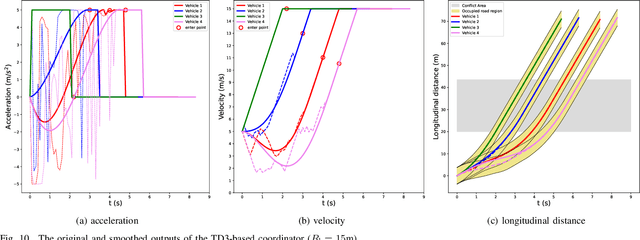
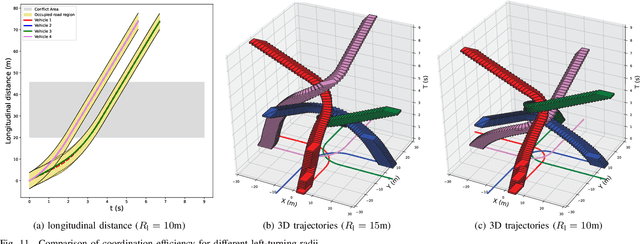
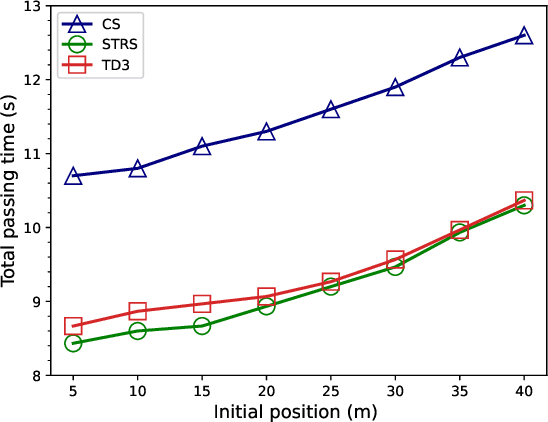
Cooperative coordination at unsignalized road intersections, which aims to improve the driving safety and traffic throughput for connected and automated vehicles, has attracted increasing interests in recent years. However, most existing investigations either suffer from computational complexity or cannot harness the full potential of the road infrastructure. To this end, we first present a dedicated intersection coordination framework, where the involved vehicles hand over their control authorities and follow instructions from a centralized coordinator. Then a unified cooperative trajectory optimization problem will be formulated to maximize the traffic throughput while ensuring the driving safety and long-term stability of the coordination system. To address the key computational challenges in the real-world deployment, we reformulate this non-convex sequential decision problem into a model-free Markov Decision Process (MDP) and tackle it by devising a Twin Delayed Deep Deterministic Policy Gradient (TD3)-based strategy in the deep reinforcement learning (DRL) framework. Simulation and practical experiments show that the proposed strategy could achieve near-optimal performance in sub-static coordination scenarios and significantly improve the traffic throughput in the realistic continuous traffic flow. The most remarkable advantage is that our strategy could reduce the time complexity of computation to milliseconds, and is shown scalable when the road lanes increase.