 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Weakly-Supervised Deep Lesion Segmentation using Large-Scale Clinical Annotations: Slice-Propagated 3D Mask Generation from 2D RECIST
Jul 02, 2018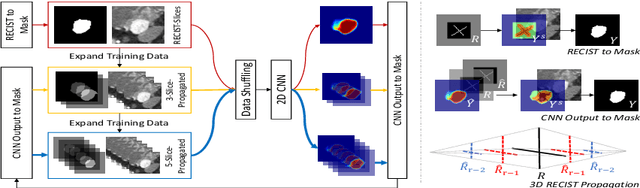
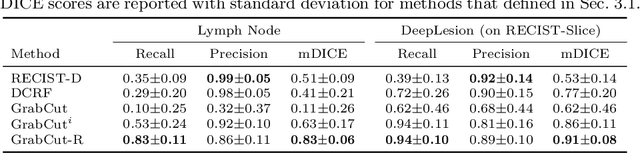
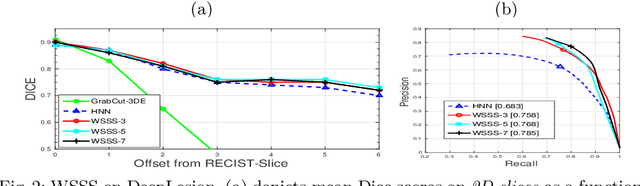
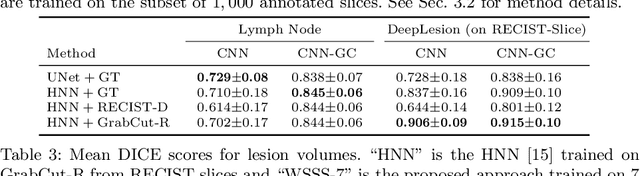
Volumetric lesion segmentation from computed tomography (CT) images is a powerful means to precisely assess multiple time-point lesion/tumor changes. However, because manual 3D segmentation is prohibitively time consuming, current practices rely on an imprecise surrogate called response evaluation criteria in solid tumors (RECIST). Despite their coarseness, RECIST markers are commonly found in current hospital picture and archiving systems (PACS), meaning they can provide a potentially powerful, yet extraordinarily challenging, source of weak supervision for full 3D segmentation. Toward this end, we introduce a convolutional neural network (CNN) based weakly supervised slice-propagated segmentation (WSSS) method to 1) generate the initial lesion segmentation on the axial RECIST-slice; 2) learn the data distribution on RECIST-slices; 3) extrapolate to segment the whole lesion slice by slice to finally obtain a volumetric segmentation. To validate the proposed method, we first test its performance on a fully annotated lymph node dataset, where WSSS performs comparably to its fully supervised counterparts. We then test on a comprehensive lesion dataset with 32,735 RECIST marks, where we report a mean Dice score of 92% on RECIST-marked slices and 76% on the entire 3D volumes.
Pancreas Segmentation in CT and MRI Images via Domain Specific Network Designing and Recurrent Neural Contextual Learning
Mar 30, 2018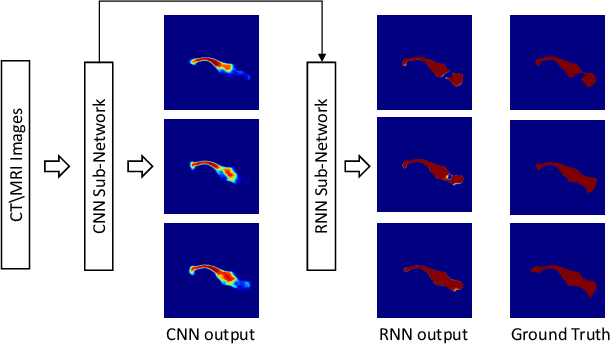
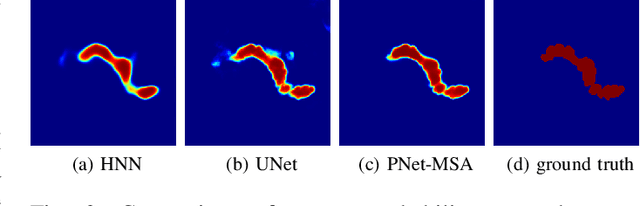
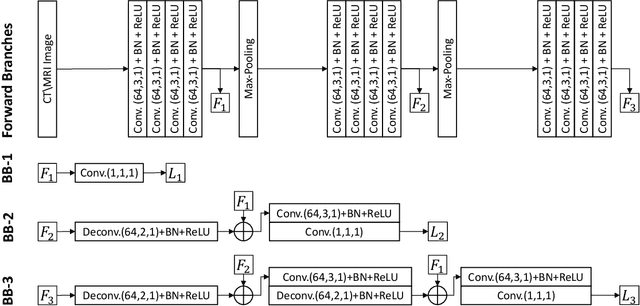
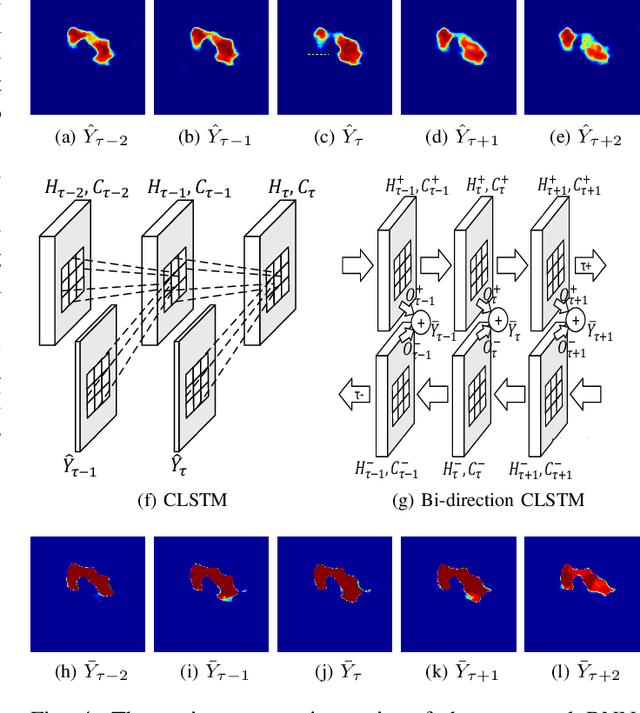
Automatic pancreas segmentation in radiology images, eg., computed tomography (CT) and magnetic resonance imaging (MRI), is frequently required by computer-aided screening, diagnosis, and quantitative assessment. Yet pancreas is a challenging abdominal organ to segment due to the high inter-patient anatomical variability in both shape and volume metrics. Recently, convolutional neural networks (CNNs) have demonstrated promising performance on accurate segmentation of pancreas. However, the CNN-based method often suffers from segmentation discontinuity for reasons such as noisy image quality and blurry pancreatic boundary. From this point, we propose to introduce recurrent neural networks (RNNs) to address the problem of spatial non-smoothness of inter-slice pancreas segmentation across adjacent image slices. To inference initial segmentation, we first train a 2D CNN sub-network, where we modify its network architecture with deep-supervision and multi-scale feature map aggregation so that it can be trained from scratch with small-sized training data and presents superior performance than transferred models. Thereafter, the successive CNN outputs are processed by another RNN sub-network, which refines the consistency of segmented shapes. More specifically, the RNN sub-network consists convolutional long short-term memory (CLSTM) units in both top-down and bottom-up directions, which regularizes the segmentation of an image by integrating predictions of its neighboring slices. We train the stacked CNN-RNN model end-to-end and perform quantitative evaluations on both CT and MRI images.
Accurate Weakly Supervised Deep Lesion Segmentation on CT Scans: Self-Paced 3D Mask Generation from RECIST
Jan 25, 2018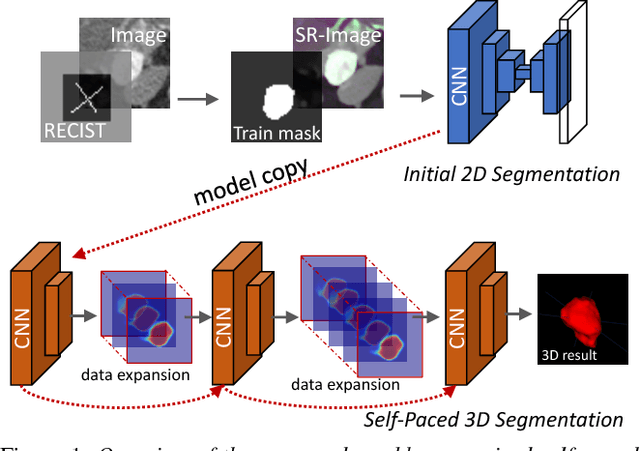
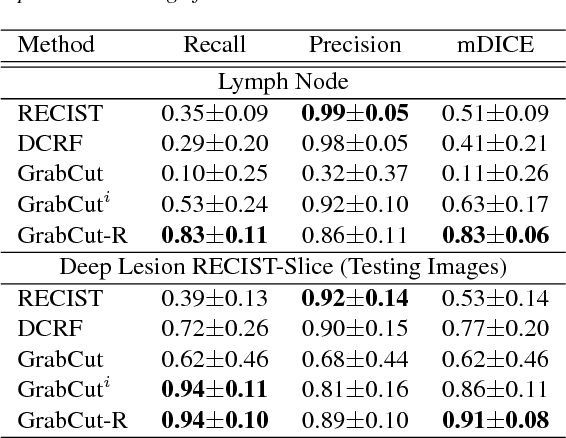
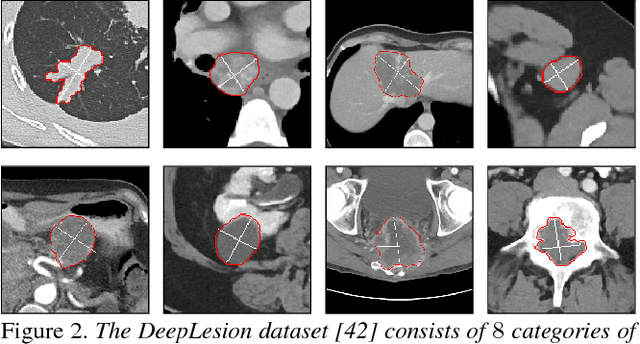
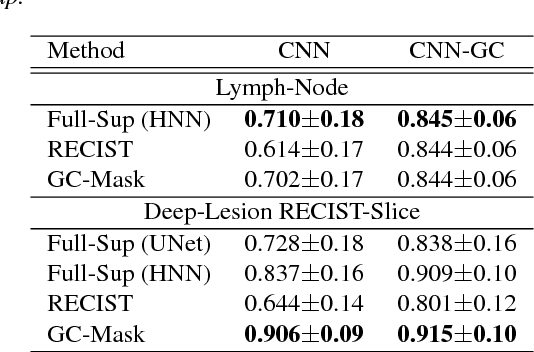
Volumetric lesion segmentation via medical imaging is a powerful means to precisely assess multiple time-point lesion/tumor changes. Because manual 3D segmentation is prohibitively time consuming and requires radiological experience, current practices rely on an imprecise surrogate called response evaluation criteria in solid tumors (RECIST). Despite their coarseness, RECIST marks are commonly found in current hospital picture and archiving systems (PACS), meaning they can provide a potentially powerful, yet extraordinarily challenging, source of weak supervision for full 3D segmentation. Toward this end, we introduce a convolutional neural network based weakly supervised self-paced segmentation (WSSS) method to 1) generate the initial lesion segmentation on the axial RECIST-slice; 2) learn the data distribution on RECIST-slices; 3) adapt to segment the whole volume slice by slice to finally obtain a volumetric segmentation. In addition, we explore how super-resolution images (2~5 times beyond the physical CT imaging), generated from a proposed stacked generative adversarial network, can aid the WSSS performance. We employ the DeepLesion dataset, a comprehensive CT-image lesion dataset of 32,735 PACS-bookmarked findings, which include lesions, tumors, and lymph nodes of varying sizes, categories, body regions and surrounding contexts. These are drawn from 10,594 studies of 4,459 patients. We also validate on a lymph-node dataset, where 3D ground truth masks are available for all images. For the DeepLesion dataset, we report mean Dice coefficients of 93% on RECIST-slices and 76% in 3D lesion volumes. We further validate using a subjective user study, where an experienced radiologist accepted our WSSS-generated lesion segmentation results with a high probability of 92.4%.
Improving Deep Pancreas Segmentation in CT and MRI Images via Recurrent Neural Contextual Learning and Direct Loss Function
Jul 18, 2017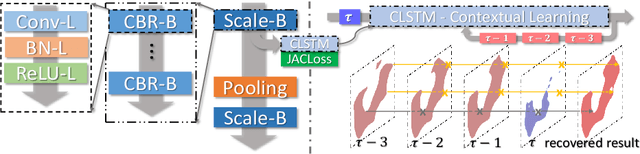


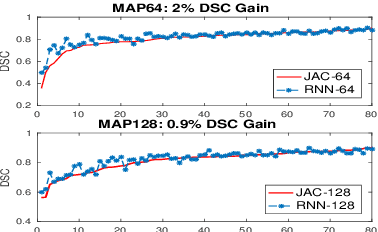
Deep neural networks have demonstrated very promising performance on accurate segmentation of challenging organs (e.g., pancreas) in abdominal CT and MRI scans. The current deep learning approaches conduct pancreas segmentation by processing sequences of 2D image slices independently through deep, dense per-pixel masking for each image, without explicitly enforcing spatial consistency constraint on segmentation of successive slices. We propose a new convolutional/recurrent neural network architecture to address the contextual learning and segmentation consistency problem. A deep convolutional sub-network is first designed and pre-trained from scratch. The output layer of this network module is then connected to recurrent layers and can be fine-tuned for contextual learning, in an end-to-end manner. Our recurrent sub-network is a type of Long short-term memory (LSTM) network that performs segmentation on an image by integrating its neighboring slice segmentation predictions, in the form of a dependent sequence processing. Additionally, a novel segmentation-direct loss function (named Jaccard Loss) is proposed and deep networks are trained to optimize Jaccard Index (JI) directly. Extensive experiments are conducted to validate our proposed deep models, on quantitative pancreas segmentation using both CT and MRI scans. Our method outperforms the state-of-the-art work on CT [11] and MRI pancreas segmentation [1], respectively.