 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Discrete Supervised Hash Learning with Asymmetric Matrix Factorization
Sep 28, 2016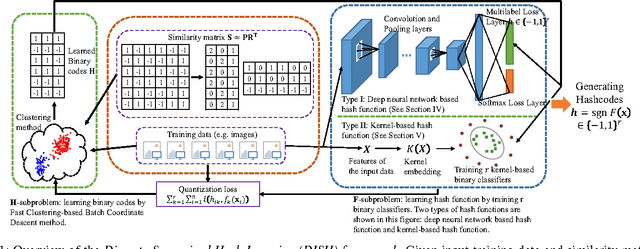
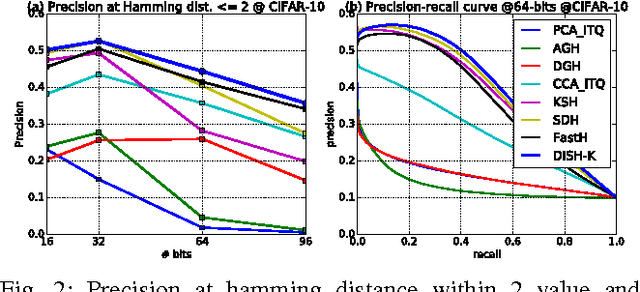
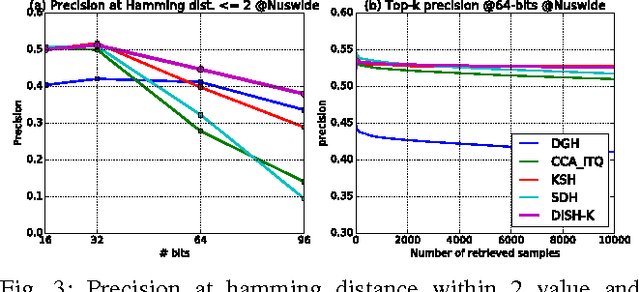
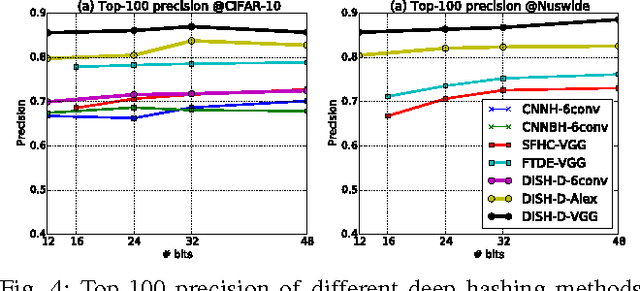
Hashing method maps similar data to binary hashcodes with smaller hamming distance, and it has received a broad attention due to its low storage cost and fast retrieval speed. However, the existing limitations make the present algorithms difficult to deal with large-scale datasets: (1) discrete constraints are involved in the learning of the hash function; (2) pairwise or triplet similarity is adopted to generate efficient hashcodes, resulting both time and space complexity are greater than O(n^2). To address these issues, we propose a novel discrete supervised hash learning framework which can be scalable to large-scale datasets. First, the discrete learning procedure is decomposed into a binary classifier learning scheme and binary codes learning scheme, which makes the learning procedure more efficient. Second, we adopt the Asymmetric Low-rank Matrix Factorization and propose the Fast Clustering-based Batch Coordinate Descent method, such that the time and space complexity is reduced to O(n). The proposed framework also provides a flexible paradigm to incorporate with arbitrary hash function, including deep neural networks and kernel methods. Experiments on large-scale datasets demonstrate that the proposed method is superior or comparable with state-of-the-art hashing algorithms.
CNN Based Hashing for Image Retrieval
Sep 04, 2015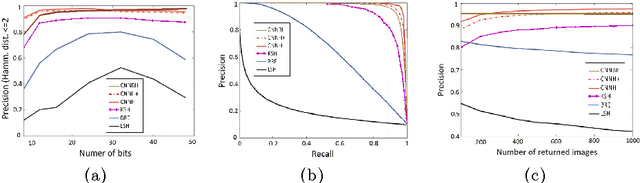



Along with data on the web increasing dramatically, hashing is becoming more and more popular as a method of approximate nearest neighbor search. Previous supervised hashing methods utilized similarity/dissimilarity matrix to get semantic information. But the matrix is not easy to construct for a new dataset. Rather than to reconstruct the matrix, we proposed a straightforward CNN-based hashing method, i.e. binarilizing the activations of a fully connected layer with threshold 0 and taking the binary result as hash codes. This method achieved the best performance on CIFAR-10 and was comparable with the state-of-the-art on MNIST. And our experiments on CIFAR-10 suggested that the signs of activations may carry more information than the relative values of activations between samples, and that the co-adaption between feature extractor and hash functions is important for hashing.