 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Domain Knowledge Learning with Dual-branch Adversarial Network for Vehicle Re-identification
Apr 30, 2019
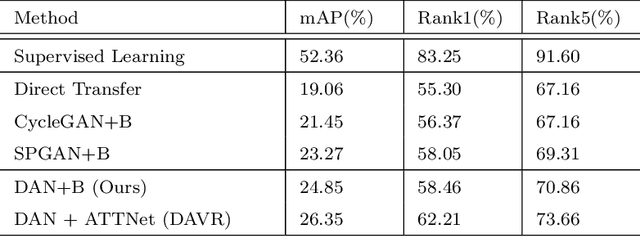
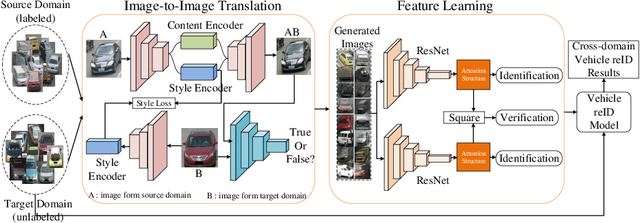
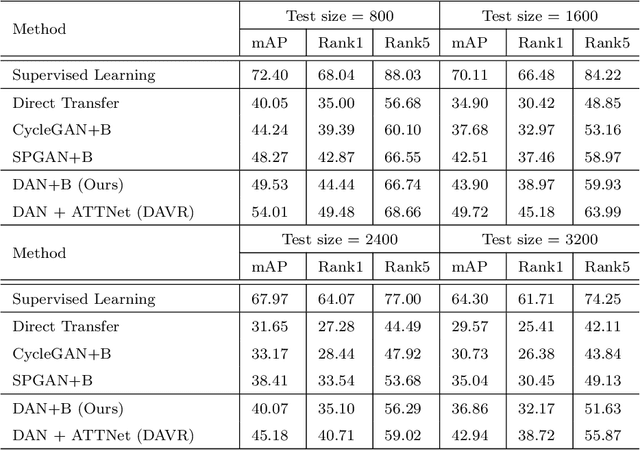
The widespread popularization of vehicles has facilitated all people's life during the last decades. However, the emergence of a large number of vehicles poses the critical but challenging problem of vehicle re-identification (reID). Till now, for most vehicle reID algorithms, both the training and testing processes are conducted on the same annotated datasets under supervision. However, even a well-trained model will still cause fateful performance drop due to the severe domain bias between the trained dataset and the real-world scenes. To address this problem, this paper proposes a domain adaptation framework for vehicle reID (DAVR), which narrows the cross-domain bias by fully exploiting the labeled data from the source domain to adapt the target domain. DAVR develops an image-to-image translation network named Dual-branch Adversarial Network (DAN), which could promote the images from the source domain (well-labeled) to learn the style of target domain (unlabeled) without any annotation and preserve identity information from source domain. Then the generated images are employed to train the vehicle reID model by a proposed attention-based feature learning model with more reasonable styles. Through the proposed framework, the well-trained reID model has better domain adaptation ability for various scenes in real-world situations. Comprehensive experimental results have demonstrated that our proposed DAVR can achieve excellent performances on both VehicleID dataset and VeRi-776 dataset.
Co-regularized Multi-view Sparse Reconstruction Embedding for Dimension Reduction
Apr 01, 2019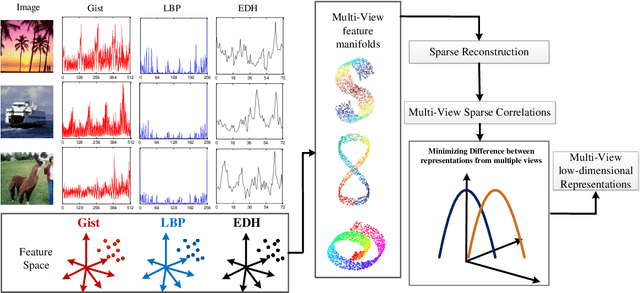

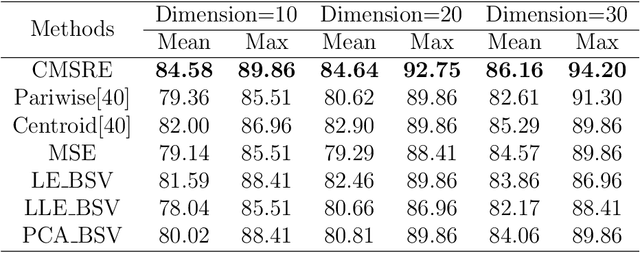
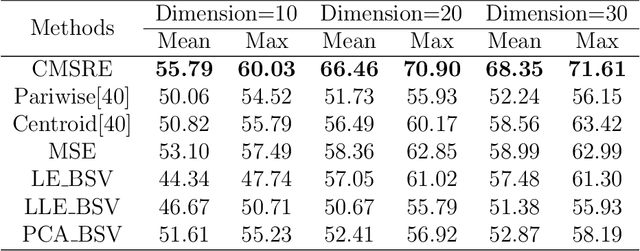
With the development of information technology, we have witnessed an age of data explosion which produces a large variety of data filled with redundant information. Because dimension reduction is an essential tool which embeds high-dimensional data into a lower-dimensional subspace to avoid redundant information, it has attracted interests from researchers all over the world. However, facing with features from multiple views, it's difficult for most dimension reduction methods to fully comprehended multi-view features and integrate compatible and complementary information from these features to construct low-dimensional subspace directly. Furthermore, most multi-view dimension reduction methods cannot handle features from nonlinear spaces with high dimensions. Therefore, how to construct a multi-view dimension reduction methods which can deal with multi-view features from high-dimensional nonlinear space is of vital importance but challenging. In order to address this problem, we proposed a novel method named Co-regularized Multi-view Sparse Reconstruction Embedding (CMSRE) in this paper. By exploiting correlations of sparse reconstruction from multiple views, CMSRE is able to learn local sparse structures of nonlinear manifolds from multiple views and constructs significative low-dimensional representations for them. Due to the proposed co-regularized scheme, correlations of sparse reconstructions from multiple views are preserved by CMSRE as much as possible. Furthermore, sparse representation produces more meaningful correlations between features from each single view, which helps CMSRE to gain better performances. Various evaluations based on the applications of document classification, face recognition and image retrieval can demonstrate the effectiveness of the proposed approach on multi-view dimension reduction.
Cross Domain Knowledge Transfer for Unsupervised Vehicle Re-identification
Mar 19, 2019

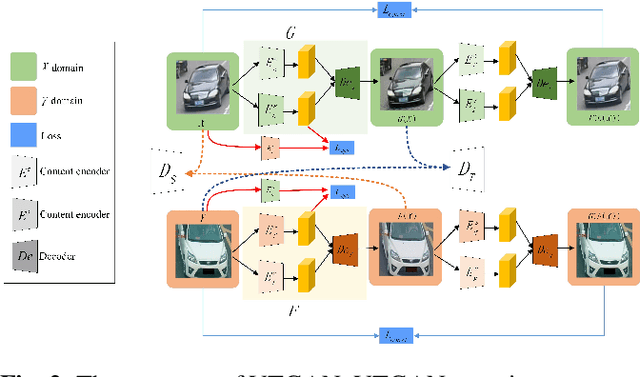
Vehicle re-identification (reID) is to identify a target vehicle in different cameras with non-overlapping views. When deploy the well-trained model to a new dataset directly, there is a severe performance drop because of differences among datasets named domain bias. To address this problem, this paper proposes an domain adaptation framework which contains an image-to-image translation network named vehicle transfer generative adversarial network (VTGAN) and an attention-based feature learning network (ATTNet). VTGAN could make images from the source domain (well-labeled) have the style of target domain (unlabeled) and preserve identity information of source domain. To further improve the domain adaptation ability for various backgrounds, ATTNet is proposed to train generated images with the attention structure for vehicle reID. Comprehensive experimental results clearly demonstrate that our method achieves excellent performance on VehicleID dataset.
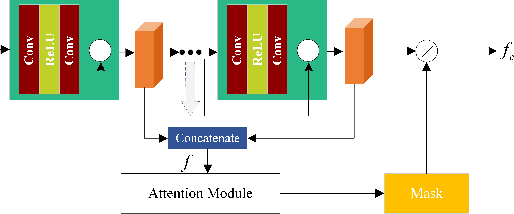
Mask-guided Style Transfer Network for Purifying Real Images
Mar 19, 2019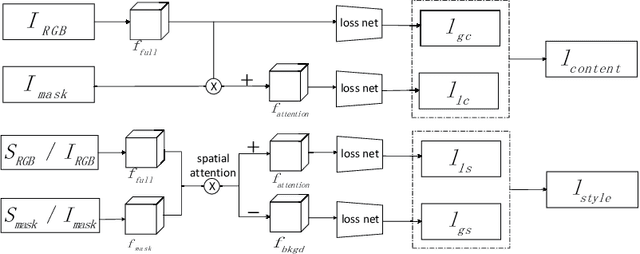


Recently, the progress of learning-by-synthesis has proposed a training model for synthetic images, which can effectively reduce the cost of human and material resources. However, due to the different distribution of synthetic images compared with real images, the desired performance cannot be achieved. To solve this problem, the previous method learned a model to improve the realism of the synthetic images. Different from the previous methods, this paper try to purify real image by extracting discriminative and robust features to convert outdoor real images to indoor synthetic images. In this paper, we first introduce the segmentation masks to construct RGB-mask pairs as inputs, then we design a mask-guided style transfer network to learn style features separately from the attention and bkgd(background) regions and learn content features from full and attention region. Moreover, we propose a novel region-level task-guided loss to restrain the features learnt from style and content. Experiments were performed using mixed studies (qualitative and quantitative) methods to demonstrate the possibility of purifying real images in complex directions. We evaluate the proposed method on various public datasets, including LPW, COCO and MPIIGaze. Experimental results show that the proposed method is effective and achieves the state-of-the-art results.
Self-Weighted Multiview Metric Learning by Maximizing the Cross Correlations
Mar 19, 2019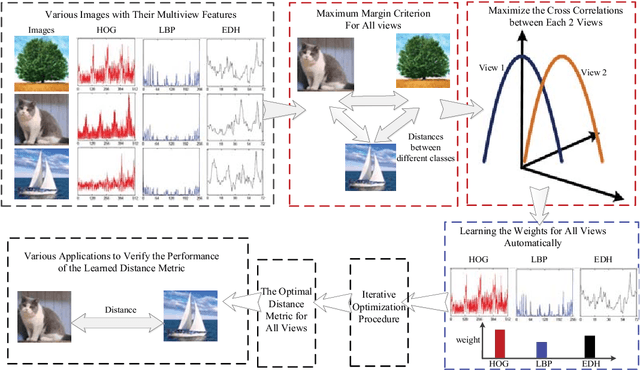
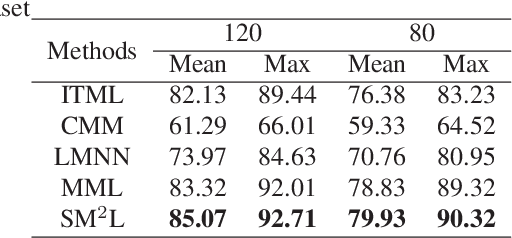
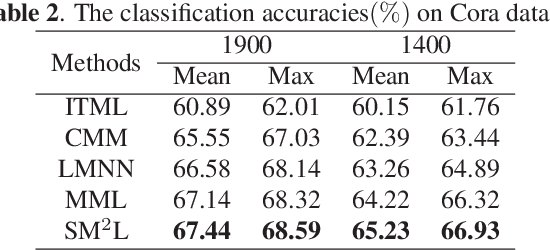
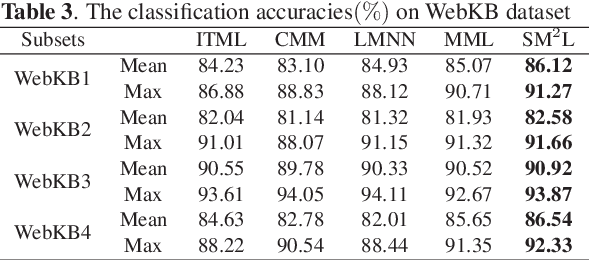
With the development of multimedia time, one sample can always be described from multiple views which contain compatible and complementary information. Most algorithms cannot take information from multiple views into considerations and fail to achieve desirable performance in most situations. For many applications, such as image retrieval, face recognition, etc., an appropriate distance metric can better reflect the similarities between various samples. Therefore, how to construct a good distance metric learning methods which can deal with multiview data has been an important topic during the last decade. In this paper, we proposed a novel algorithm named Self-weighted Multiview Metric Learning (SM2L) which can finish this task by maximizing the cross correlations between different views. Furthermore, because multiple views have different contributions to the learning procedure of SM2L, we adopt a self-weighted learning framework to assign multiple views with different weights. Various experiments on benchmark datasets can verify the performance of our proposed method.
Guiding Intelligent Surveillance System by learning-by-synthesis gaze estimation
Oct 08, 2018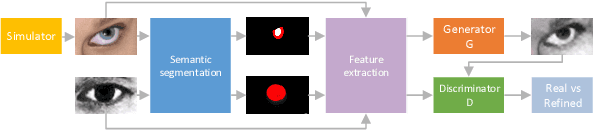
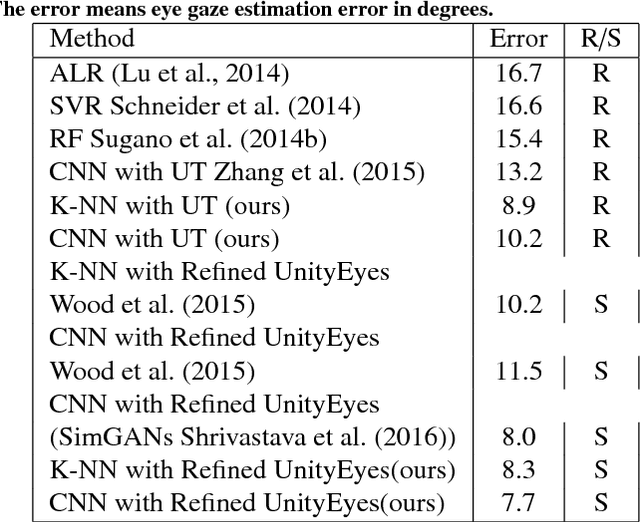
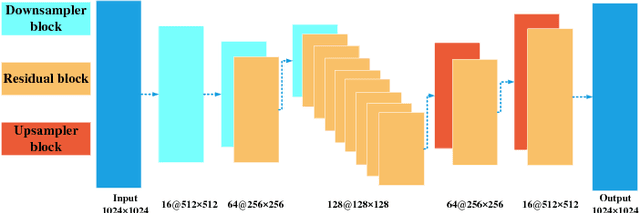
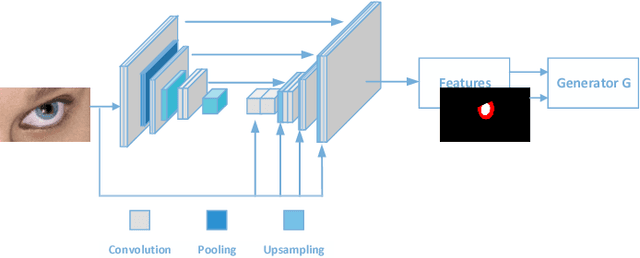
We describe a novel learning-by-synthesis method for estimating gaze direction of an automated intelligent surveillance system. Recently, progress in learning-by-synthesis has proposed training models on synthetic images, which can effectively reduce the cost of manpower and material resources. However, learning from synthetic images still fails to achieve the desired performance compared to naturalistic images due to the different distribution of synthetic images. In an attempt to address this issue, previous method is to improve the realism of synthetic images by learning a model. However, the disadvantage of the method is that the distortion has not been improved and the authenticity level is unstable. To solve this problem, we put forward a new structure to improve synthetic images, via the reference to the idea of style transformation, through which we can efficiently reduce the distortion of pictures and minimize the need of real data annotation. We estimate that this enables generation of highly realistic images, which we demonstrate both qualitatively and with a user study. We quantitatively evaluate the generated images by training models for gaze estimation. We show a significant improvement over using synthetic images, and achieve state-of-the-art results on various datasets including MPIIGaze dataset.