 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAP: Controllable Alignment Prompting for Unlearning in LLMs
Apr 23, 2026Large language models (LLMs) trained on unfiltered corpora inherently risk retaining sensitive information, necessitating selective knowledge unlearning for regulatory compliance and ethical safety. However, existing parameter-modifying methods face fundamental limitations: high computational costs, uncontrollable forgetting boundaries, and strict dependency on model weight access. These constraints render them impractical for closed-source models, yet current non-invasive alternatives remain unsystematic and reliant on empirical experience. To address these challenges, we propose the Controllable Alignment Prompting for Unlearning (CAP) framework, an end-to-end prompt-driven unlearning paradigm. CAP decouples unlearning into a learnable prompt optimization process via reinforcement learning, where a prompt generator collaborates with the LLM to suppress target knowledge while preserving general capabilities selectively. This approach enables reversible knowledge restoration through prompt revocation. Extensive experiments demonstrate that CAP achieves precise, controllable unlearning without updating model parameters, establishing a dynamic alignment mechanism that overcomes the transferability limitations of prior methods.
LOOPRAG: Enhancing Loop Transformation Optimization with Retrieval-Augmented Large Language Models
Dec 12, 2025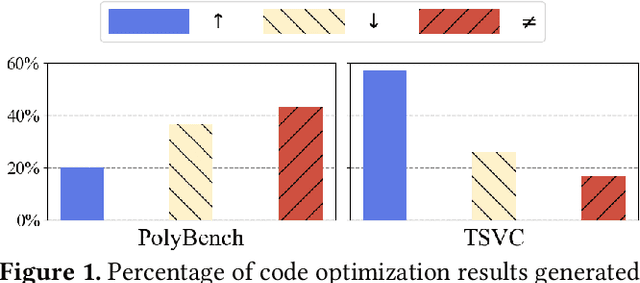
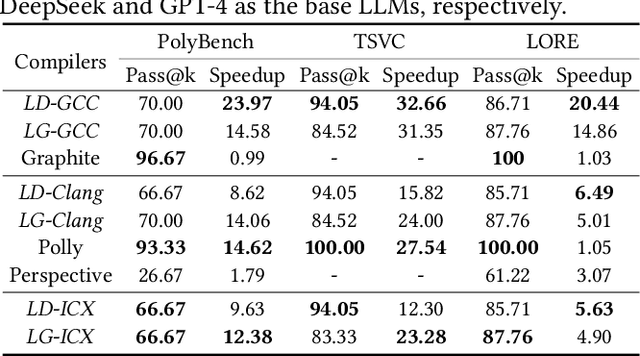

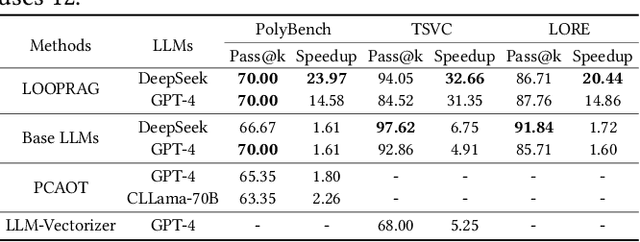
Loop transformations are semantics-preserving optimization techniques, widely used to maximize objectives such as parallelism. Despite decades of research, applying the optimal composition of loop transformations remains challenging due to inherent complexities, including cost modeling for optimization objectives. Recent studies have explored the potential of Large Language Models (LLMs) for code optimization. However, our key observation is that LLMs often struggle with effective loop transformation optimization, frequently leading to errors or suboptimal optimization, thereby missing opportunities for performance improvements. To bridge this gap, we propose LOOPRAG, a novel retrieval-augmented generation framework designed to guide LLMs in performing effective loop optimization on Static Control Part. We introduce a parameter-driven method to harness loop properties, which trigger various loop transformations, and generate diverse yet legal example codes serving as a demonstration source. To effectively obtain the most informative demonstrations, we propose a loop-aware algorithm based on loop features, which balances similarity and diversity for code retrieval. To enhance correct and efficient code generation, we introduce a feedback-based iterative mechanism that incorporates compilation, testing and performance results as feedback to guide LLMs. Each optimized code undergoes mutation, coverage and differential testing for equivalence checking. We evaluate LOOPRAG on PolyBench, TSVC and LORE benchmark suites, and compare it against compilers (GCC-Graphite, Clang-Polly, Perspective and ICX) and representative LLMs (DeepSeek and GPT-4). The results demonstrate average speedups over base compilers of up to 11.20$\times$, 14.34$\times$, and 9.29$\times$ for PolyBench, TSVC, and LORE, respectively, and speedups over base LLMs of up to 11.97$\times$, 5.61$\times$, and 11.59$\times$.
Noise-Robustness Through Noise: Asymmetric LoRA Adaption with Poisoning Expert
May 29, 2025



Current parameter-efficient fine-tuning methods for adapting pre-trained language models to downstream tasks are susceptible to interference from noisy data. Conventional noise-handling approaches either rely on laborious data pre-processing or employ model architecture modifications prone to error accumulation. In contrast to existing noise-process paradigms, we propose a noise-robust adaptation method via asymmetric LoRA poisoning experts (LoPE), a novel framework that enhances model robustness to noise only with generated noisy data. Drawing inspiration from the mixture-of-experts architecture, LoPE strategically integrates a dedicated poisoning expert in an asymmetric LoRA configuration. Through a two-stage paradigm, LoPE performs noise injection on the poisoning expert during fine-tuning to enhance its noise discrimination and processing ability. During inference, we selectively mask the dedicated poisoning expert to leverage purified knowledge acquired by normal experts for noise-robust output. Extensive experiments demonstrate that LoPE achieves strong performance and robustness purely through the low-cost noise injection, which completely eliminates the requirement of data cleaning.