 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Reservoir Bregman Projection: An Information-Geometric Unification of Model Collapse
Dec 16, 2025



Self-referential learning -- training a model on data it generated itself -- promises boundless scalability but chronically suffers from model collapse: language models degenerate into repetitive text, GANs drop modes, and reinforcement-learning policies over-exploit. Although practitioners employ ad~hoc fixes such as real-data mixing, entropy bonuses, knowledge distillation, or retrieval-augmented generation, a single principle that explains both the failure mode and the success of these fixes has remained elusive. We present Entropy-Reservoir Bregman Projection (ERBP), an information-geometric framework that unifies these phenomena. We model the closed loop as a stochastic Bregman projection sequence in distribution space. Without external coupling, finite-sample noise forces the system to project onto an ever-shrinking empirical support, causing exponential entropy decay and eventual collapse. Introducing an Entropy Reservoir -- a high-entropy distribution mixed into each projection -- injects a controllable entropy flux that provably stabilises the dynamics. Our theory yields (i) a necessary condition for collapse, (ii) a sufficient condition that guarantees a non-trivial entropy floor, and (iii) closed-form rates that depend only on sample size and the strong-convexity/Lipschitz constants of the Bregman generator. Experiments on large-language-model self-training, Soft Actor-Critic in reinforcement learning, and GAN optimisation validate our predictions and show that disparate stabilisation heuristics correspond to specific reservoir choices and coupling coefficients. ERBP thus transforms a collection of folk remedies into a single, quantitative design rule: monitor and budget your entropy flux.
SCAN: A Scalable Neural Networks Framework Towards Compact and Efficient Models
May 27, 2019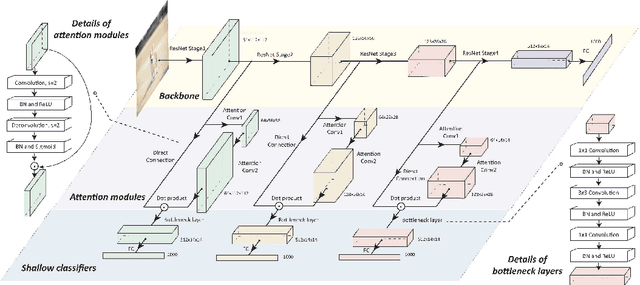
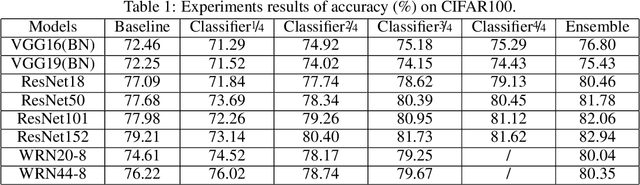
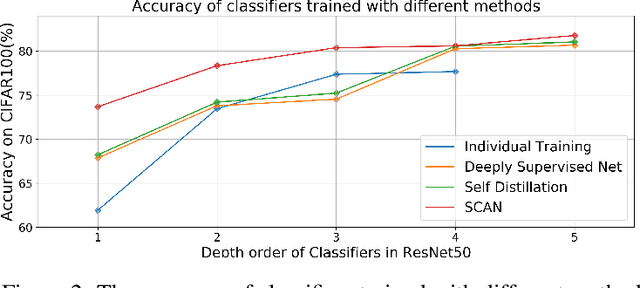
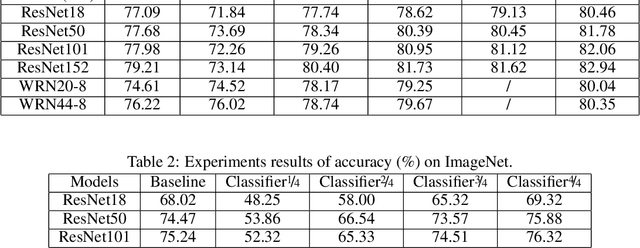
Remarkable achievements have been attained by deep neural networks in various applications. However, the increasing depth and width of such models also lead to explosive growth in both storage and computation, which has restricted the deployment of deep neural networks on resource-limited edge devices. To address this problem, we propose the so-called SCAN framework for networks training and inference, which is orthogonal and complementary to existing acceleration and compression methods. The proposed SCAN firstly divides neural networks into multiple sections according to their depth and constructs shallow classifiers upon the intermediate features of different sections. Moreover, attention modules and knowledge distillation are utilized to enhance the accuracy of shallow classifiers. Based on this architecture, we further propose a threshold controlled scalable inference mechanism to approach human-like sample-specific inference. Experimental results show that SCAN can be easily equipped on various neural networks without any adjustment on hyper-parameters or neural networks architectures, yielding significant performance gain on CIFAR100 and ImageNet. Codes will be released on github soon.
Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation
May 17, 2019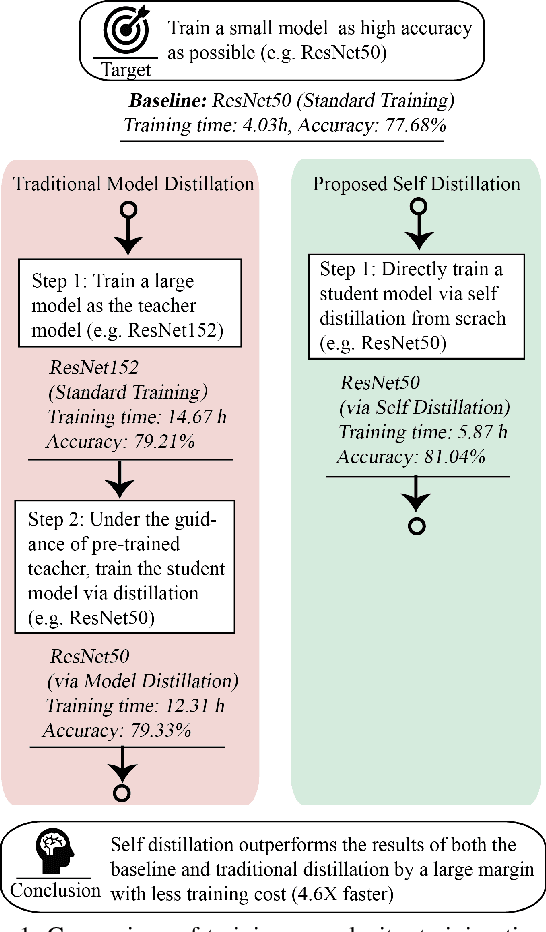
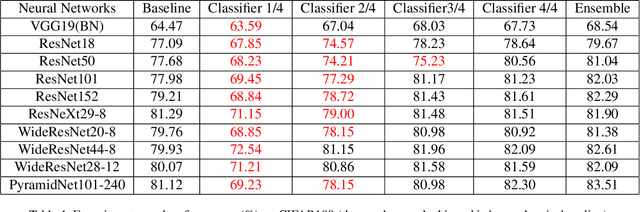
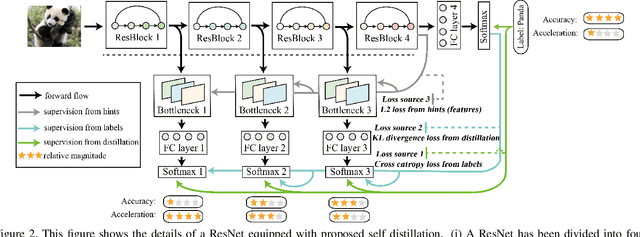

Convolutional neural networks have been widely deployed in various application scenarios. In order to extend the applications' boundaries to some accuracy-crucial domains, researchers have been investigating approaches to boost accuracy through either deeper or wider network structures, which brings with them the exponential increment of the computational and storage cost, delaying the responding time. In this paper, we propose a general training framework named self distillation, which notably enhances the performance (accuracy) of convolutional neural networks through shrinking the size of the network rather than aggrandizing it. Different from traditional knowledge distillation - a knowledge transformation methodology among networks, which forces student neural networks to approximate the softmax layer outputs of pre-trained teacher neural networks, the proposed self distillation framework distills knowledge within network itself. The networks are firstly divided into several sections. Then the knowledge in the deeper portion of the networks is squeezed into the shallow ones. Experiments further prove the generalization of the proposed self distillation framework: enhancement of accuracy at average level is 2.65%, varying from 0.61% in ResNeXt as minimum to 4.07% in VGG19 as maximum. In addition, it can also provide flexibility of depth-wise scalable inference on resource-limited edge devices.Our codes will be released on github soon.
Front-to-End Bidirectional Heuristic Search with Near-Optimal Node Expansions
May 23, 2017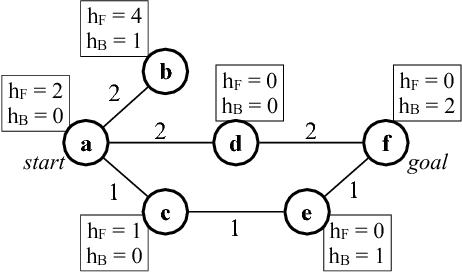
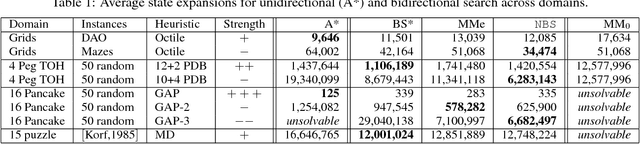
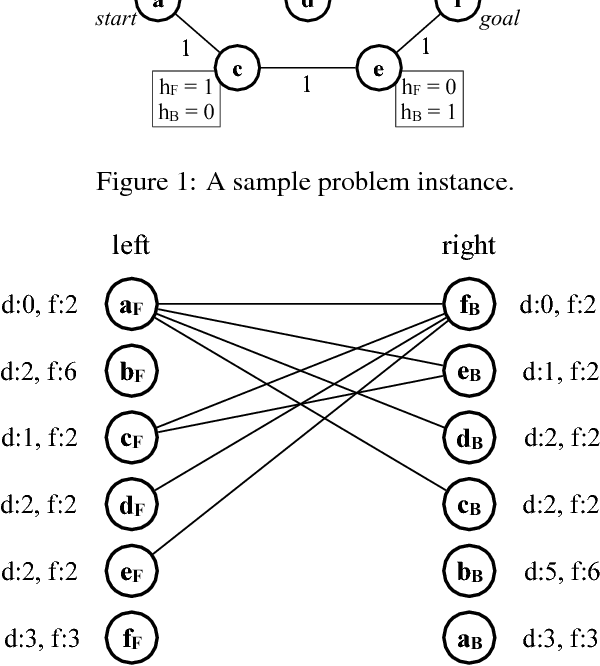
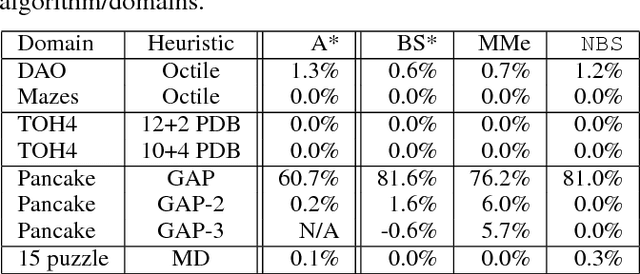
It is well-known that any admissible unidirectional heuristic search algorithm must expand all states whose $f$-value is smaller than the optimal solution cost when using a consistent heuristic. Such states are called "surely expanded" (s.e.). A recent study characterized s.e. pairs of states for bidirectional search with consistent heuristics: if a pair of states is s.e. then at least one of the two states must be expanded. This paper derives a lower bound, VC, on the minimum number of expansions required to cover all s.e. pairs, and present a new admissible front-to-end bidirectional heuristic search algorithm, Near-Optimal Bidirectional Search (NBS), that is guaranteed to do no more than 2VC expansions. We further prove that no admissible front-to-end algorithm has a worst case better than 2VC. Experimental results show that NBS competes with or outperforms existing bidirectional search algorithms, and often outperforms A* as well.