 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery and Reinforcement of Tool-Integrated Reasoning Chains via Rollout Trees
Jan 13, 2026Tool-Integrated Reasoning has emerged as a key paradigm to augment Large Language Models (LLMs) with computational capabilities, yet integrating tool-use into long Chain-of-Thought (long CoT) remains underexplored, largely due to the scarcity of training data and the challenge of integrating tool-use without compromising the model's intrinsic long-chain reasoning. In this paper, we introduce DART (Discovery And Reinforcement of Tool-Integrated Reasoning Chains via Rollout Trees), a reinforcement learning framework that enables spontaneous tool-use during long CoT reasoning without human annotation. DART operates by constructing dynamic rollout trees during training to discover valid tool-use opportunities, branching out at promising positions to explore diverse tool-integrated trajectories. Subsequently, a tree-based process advantage estimation identifies and credits specific sub-trajectories where tool invocation positively contributes to the solution, effectively reinforcing these beneficial behaviors. Extensive experiments on challenging benchmarks like AIME and GPQA-Diamond demonstrate that DART significantly outperforms existing methods, successfully harmonizing tool execution with long CoT reasoning.
Clustering-Aware Negative Sampling for Unsupervised Sentence Representation
May 17, 2023Contrastive learning has been widely studied in sentence representation learning. However, earlier works mainly focus on the construction of positive examples, while in-batch samples are often simply treated as negative examples. This approach overlooks the importance of selecting appropriate negative examples, potentially leading to a scarcity of hard negatives and the inclusion of false negatives. To address these issues, we propose ClusterNS (Clustering-aware Negative Sampling), a novel method that incorporates cluster information into contrastive learning for unsupervised sentence representation learning. We apply a modified K-means clustering algorithm to supply hard negatives and recognize in-batch false negatives during training, aiming to solve the two issues in one unified framework. Experiments on semantic textual similarity (STS) tasks demonstrate that our proposed ClusterNS compares favorably with baselines in unsupervised sentence representation learning. Our code has been made publicly available.
Orders Are Unwanted: Dynamic Deep Graph Convolutional Network for Personality Detection
Dec 06, 2022Predicting personality traits based on online posts has emerged as an important task in many fields such as social network analysis. One of the challenges of this task is assembling information from various posts into an overall profile for each user. While many previous solutions simply concatenate the posts into a long document and then encode the document by sequential or hierarchical models, they introduce unwarranted orders for the posts, which may mislead the models. In this paper, we propose a dynamic deep graph convolutional network (D-DGCN) to overcome the above limitation. Specifically, we design a learn-to-connect approach that adopts a dynamic multi-hop structure instead of a deterministic structure, and combine it with a DGCN module to automatically learn the connections between posts. The modules of post encoder, learn-to-connect, and DGCN are jointly trained in an end-to-end manner. Experimental results on the Kaggle and Pandora datasets show the superior performance of D-DGCN to state-of-the-art baselines. Our code is available at https://github.com/djz233/D-DGCN.
AD-DROP: Attribution-Driven Dropout for Robust Language Model Fine-Tuning
Oct 12, 2022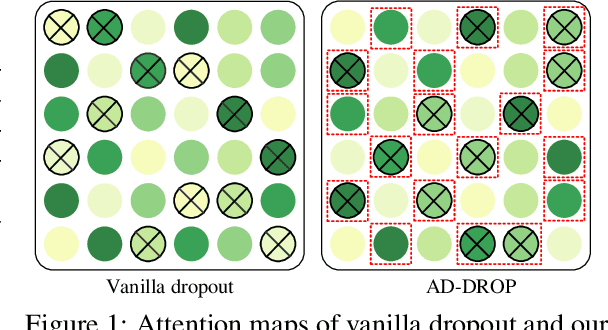
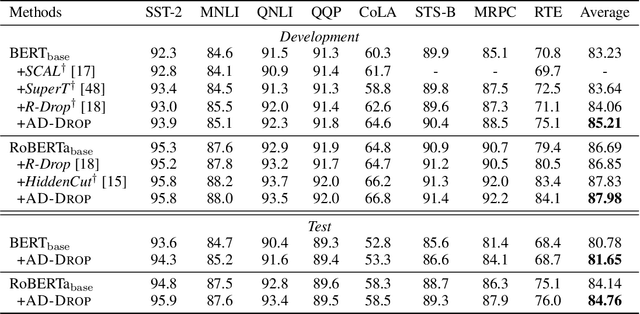
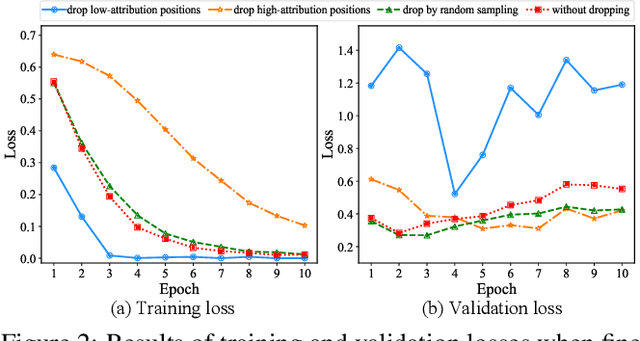
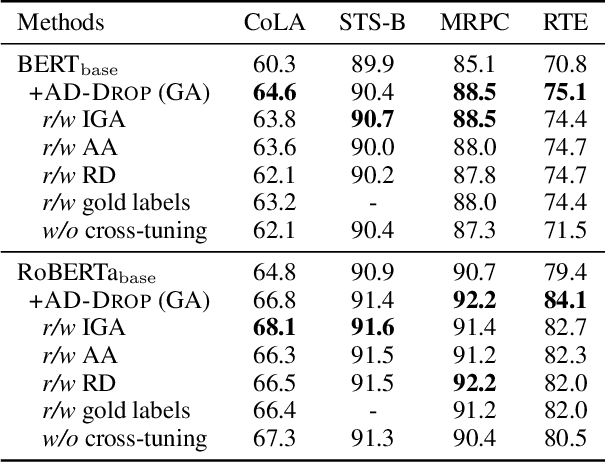
Fine-tuning large pre-trained language models on downstream tasks is apt to suffer from overfitting when limited training data is available. While dropout proves to be an effective antidote by randomly dropping a proportion of units, existing research has not examined its effect on the self-attention mechanism. In this paper, we investigate this problem through self-attention attribution and find that dropping attention positions with low attribution scores can accelerate training and increase the risk of overfitting. Motivated by this observation, we propose Attribution-Driven Dropout (AD-DROP), which randomly discards some high-attribution positions to encourage the model to make predictions by relying more on low-attribution positions to reduce overfitting. We also develop a cross-tuning strategy to alternate fine-tuning and AD-DROP to avoid dropping high-attribution positions excessively. Extensive experiments on various benchmarks show that AD-DROP yields consistent improvements over baselines. Analysis further confirms that AD-DROP serves as a strategic regularizer to prevent overfitting during fine-tuning.