 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Model-based Planning with Policy Networks
Jun 20, 2019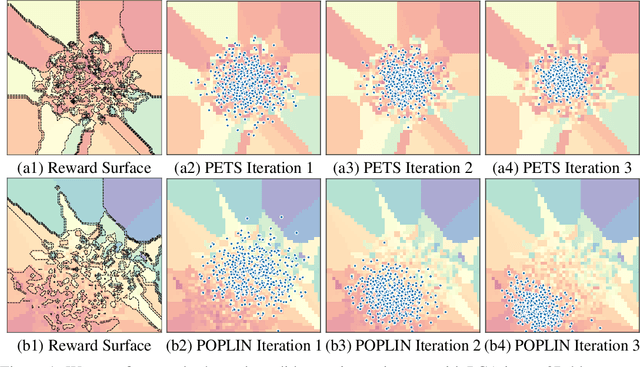
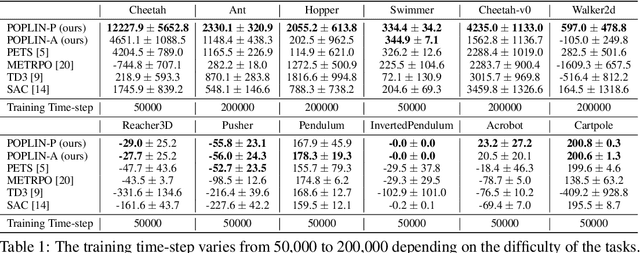
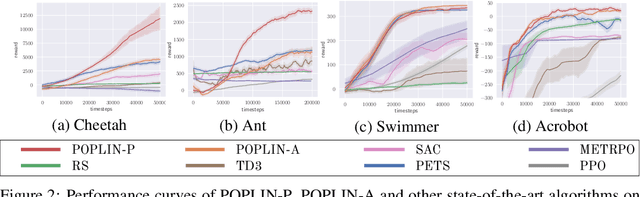
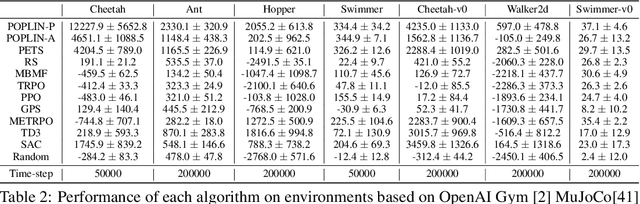
Model-based reinforcement learning (MBRL) with model-predictive control or online planning has shown great potential for locomotion control tasks in terms of both sample efficiency and asymptotic performance. Despite their initial successes, the existing planning methods search from candidate sequences randomly generated in the action space, which is inefficient in complex high-dimensional environments. In this paper, we propose a novel MBRL algorithm, model-based policy planning (POPLIN), that combines policy networks with online planning. More specifically, we formulate action planning at each time-step as an optimization problem using neural networks. We experiment with both optimization w.r.t. the action sequences initialized from the policy network, and also online optimization directly w.r.t. the parameters of the policy network. We show that POPLIN obtains state-of-the-art performance in the MuJoCo benchmarking environments, being about 3x more sample efficient than the state-of-the-art algorithms, such as PETS, TD3 and SAC. To explain the effectiveness of our algorithm, we show that the optimization surface in parameter space is smoother than in action space. Further more, we found the distilled policy network can be effectively applied without the expansive model predictive control during test time for some environments such as Cheetah. Code is released in https://github.com/WilsonWangTHU/POPLIN.
Neural Graph Evolution: Towards Efficient Automatic Robot Design
Jun 12, 2019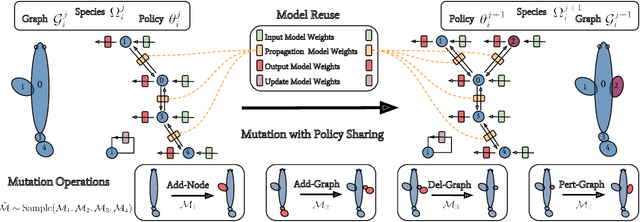

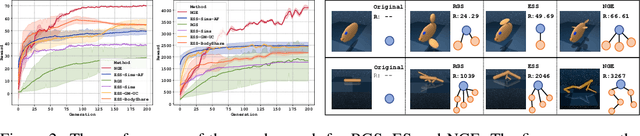
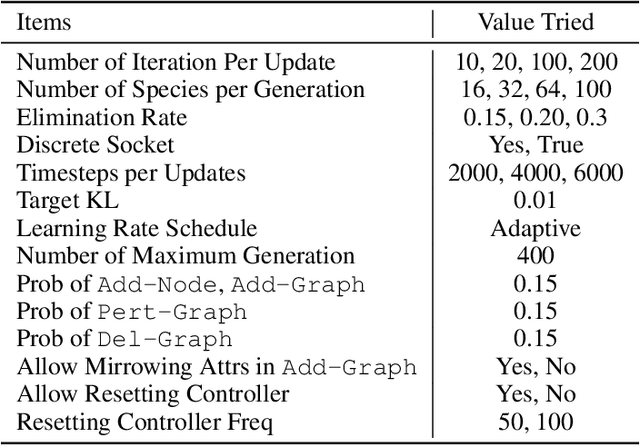
Despite the recent successes in robotic locomotion control, the design of robot relies heavily on human engineering. Automatic robot design has been a long studied subject, but the recent progress has been slowed due to the large combinatorial search space and the difficulty in evaluating the found candidates. To address the two challenges, we formulate automatic robot design as a graph search problem and perform evolution search in graph space. We propose Neural Graph Evolution (NGE), which performs selection on current candidates and evolves new ones iteratively. Different from previous approaches, NGE uses graph neural networks to parameterize the control policies, which reduces evaluation cost on new candidates with the help of skill transfer from previously evaluated designs. In addition, NGE applies Graph Mutation with Uncertainty (GM-UC) by incorporating model uncertainty, which reduces the search space by balancing exploration and exploitation. We show that NGE significantly outperforms previous methods by an order of magnitude. As shown in experiments, NGE is the first algorithm that can automatically discover kinematically preferred robotic graph structures, such as a fish with two symmetrical flat side-fins and a tail, or a cheetah with athletic front and back legs. Instead of using thousands of cores for weeks, NGE efficiently solves searching problem within a day on a single 64 CPU-core Amazon EC2 machine.
Graph Normalizing Flows
May 30, 2019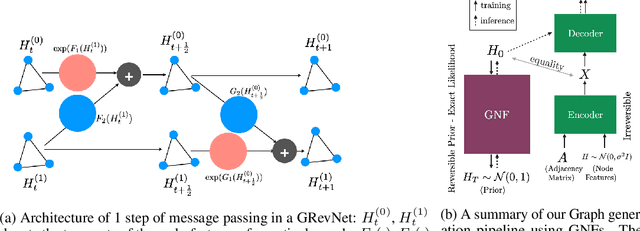

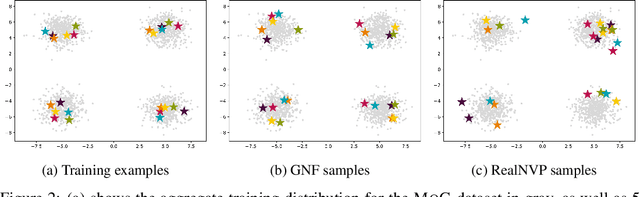
We introduce graph normalizing flows: a new, reversible graph neural network model for prediction and generation. On supervised tasks, graph normalizing flows perform similarly to message passing neural networks, but at a significantly reduced memory footprint, allowing them to scale to larger graphs. In the unsupervised case, we combine graph normalizing flows with a novel graph auto-encoder to create a generative model of graph structures. Our model is permutation-invariant, generating entire graphs with a single feed-forward pass, and achieves competitive results with the state-of-the art auto-regressive models, while being better suited to parallel computing architectures.
Interplay Between Optimization and Generalization of Stochastic Gradient Descent with Covariance Noise
Apr 03, 2019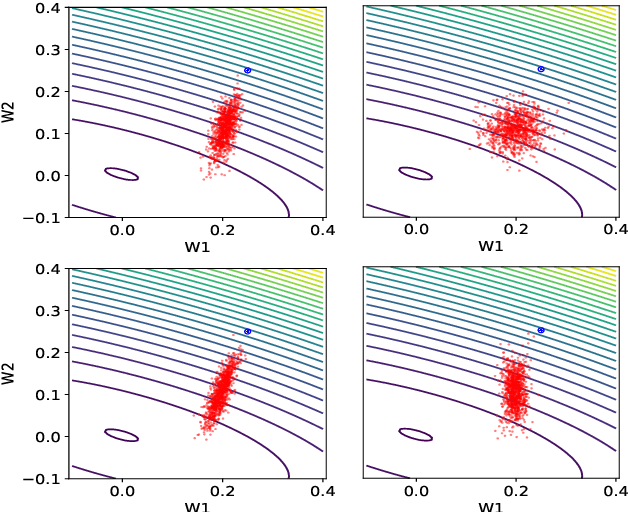
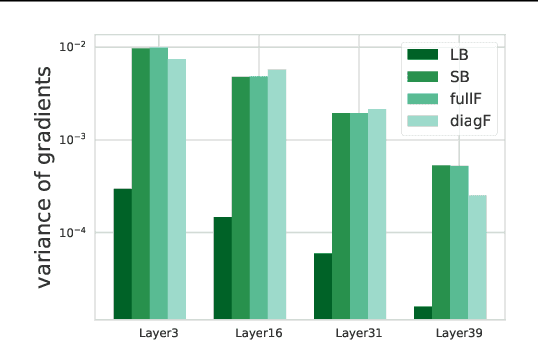

The choice of batch-size in a stochastic optimization algorithm plays a substantial role for both optimization and generalization. Increasing the batch-size used typically improves optimization but degrades generalization. To address the problem of improving generalization while maintaining optimal convergence in large-batch training, we propose to add covariance noise to the gradients. We demonstrate that the optimization performance of our method is more accurately captured by the structure of the noise covariance matrix rather than by the variance of gradients. Moreover, over the convex-quadratic, we prove in theory that it can be characterized by the Frobenius norm of the noise matrix. Our empirical studies with standard deep learning model-architectures and datasets shows that our method not only improves generalization performance in large-batch training, but furthermore, does so in a way where the optimization performance remains desirable and the training duration is not elongated.
DOM-Q-NET: Grounded RL on Structured Language
Feb 19, 2019
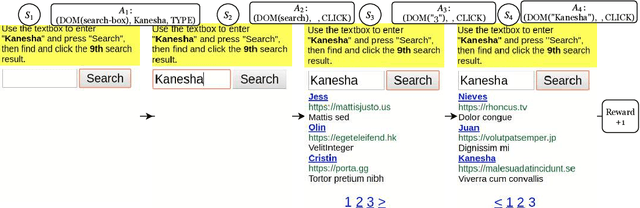
Building agents to interact with the web would allow for significant improvements in knowledge understanding and representation learning. However, web navigation tasks are difficult for current deep reinforcement learning (RL) models due to the large discrete action space and the varying number of actions between the states. In this work, we introduce DOM-Q-NET, a novel architecture for RL-based web navigation to address both of these problems. It parametrizes Q functions with separate networks for different action categories: clicking a DOM element and typing a string input. Our model utilizes a graph neural network to represent the tree-structured HTML of a standard web page. We demonstrate the capabilities of our model on the MiniWoB environment where we can match or outperform existing work without the use of expert demonstrations. Furthermore, we show 2x improvements in sample efficiency when training in the multi-task setting, allowing our model to transfer learned behaviours across tasks.
ACTRCE: Augmenting Experience via Teacher's Advice For Multi-Goal Reinforcement Learning
Feb 12, 2019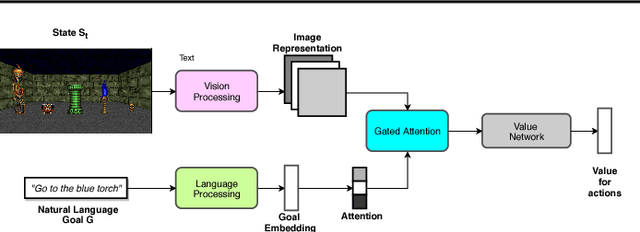
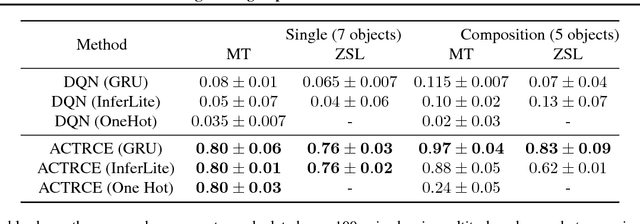
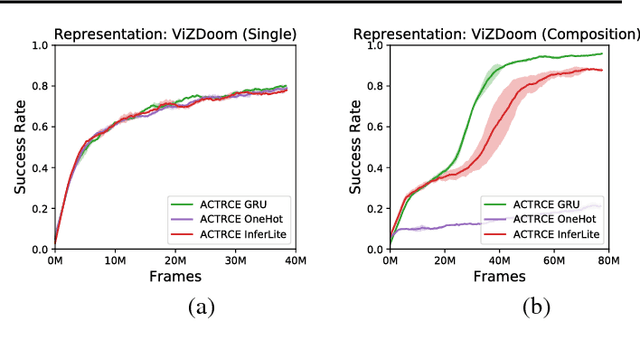

Sparse reward is one of the most challenging problems in reinforcement learning (RL). Hindsight Experience Replay (HER) attempts to address this issue by converting a failed experience to a successful one by relabeling the goals. Despite its effectiveness, HER has limited applicability because it lacks a compact and universal goal representation. We present Augmenting experienCe via TeacheR's adviCE (ACTRCE), an efficient reinforcement learning technique that extends the HER framework using natural language as the goal representation. We first analyze the differences among goal representation, and show that ACTRCE can efficiently solve difficult reinforcement learning problems in challenging 3D navigation tasks, whereas HER with non-language goal representation failed to learn. We also show that with language goal representations, the agent can generalize to unseen instructions, and even generalize to instructions with unseen lexicons. We further demonstrate it is crucial to use hindsight advice to solve challenging tasks, and even small amount of advice is sufficient for the agent to achieve good performance.
Reversible Recurrent Neural Networks
Oct 25, 2018

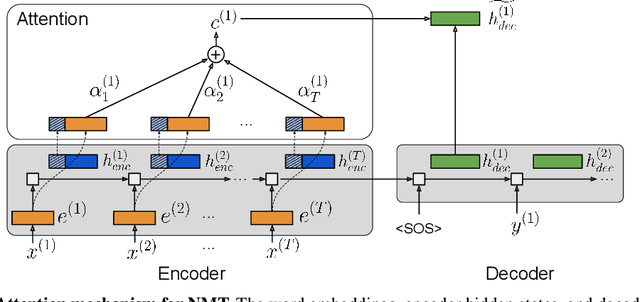
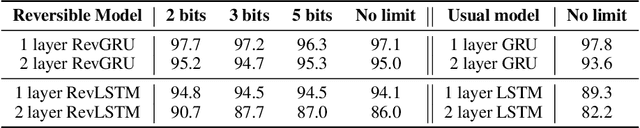
Recurrent neural networks (RNNs) provide state-of-the-art performance in processing sequential data but are memory intensive to train, limiting the flexibility of RNN models which can be trained. Reversible RNNs---RNNs for which the hidden-to-hidden transition can be reversed---offer a path to reduce the memory requirements of training, as hidden states need not be stored and instead can be recomputed during backpropagation. We first show that perfectly reversible RNNs, which require no storage of the hidden activations, are fundamentally limited because they cannot forget information from their hidden state. We then provide a scheme for storing a small number of bits in order to allow perfect reversal with forgetting. Our method achieves comparable performance to traditional models while reducing the activation memory cost by a factor of 10--15. We extend our technique to attention-based sequence-to-sequence models, where it maintains performance while reducing activation memory cost by a factor of 5--10 in the encoder, and a factor of 10--15 in the decoder.
On the Convergence and Robustness of Training GANs with Regularized Optimal Transport
May 22, 2018
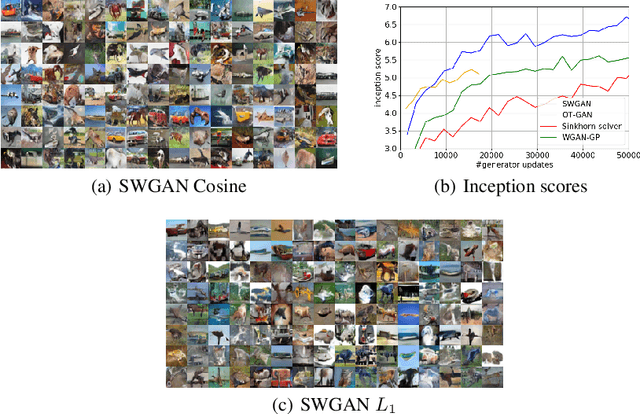
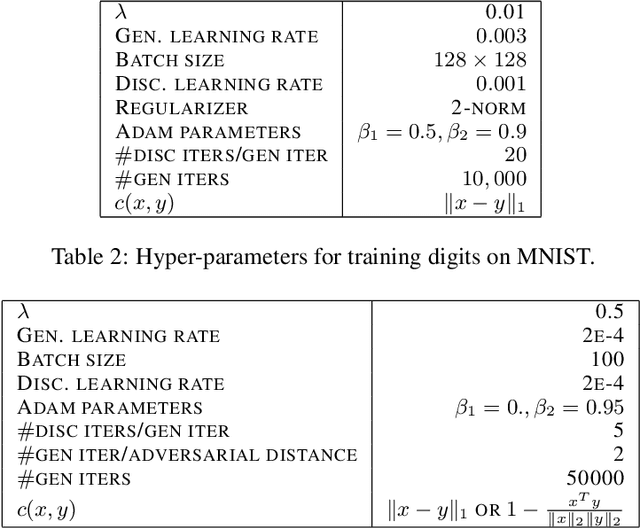

Generative Adversarial Networks (GANs) are one of the most practical methods for learning data distributions. A popular GAN formulation is based on the use of Wasserstein distance as a metric between probability distributions. Unfortunately, minimizing the Wasserstein distance between the data distribution and the generative model distribution is a computationally challenging problem as its objective is non-convex, non-smooth, and even hard to compute. In this work, we show that obtaining gradient information of the smoothed Wasserstein GAN formulation, which is based on regularized Optimal Transport (OT), is computationally effortless and hence one can apply first order optimization methods to minimize this objective. Consequently, we establish theoretical convergence guarantee to stationarity for a proposed class of GAN optimization algorithms. Unlike the original non-smooth formulation, our algorithm only requires solving the discriminator to approximate optimality. We apply our method to learning MNIST digits as well as CIFAR-10images. Our experiments show that our method is computationally efficient and generates images comparable to the state of the art algorithms given the same architecture and computational power.
Flipout: Efficient Pseudo-Independent Weight Perturbations on Mini-Batches
Apr 02, 2018
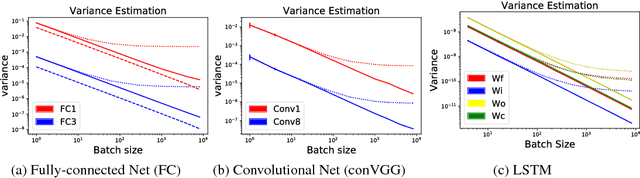
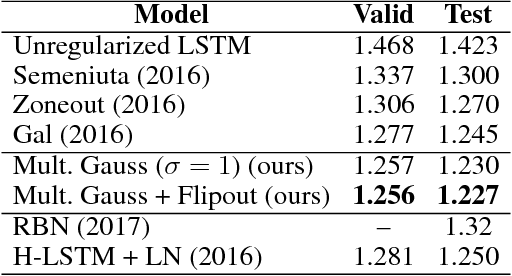
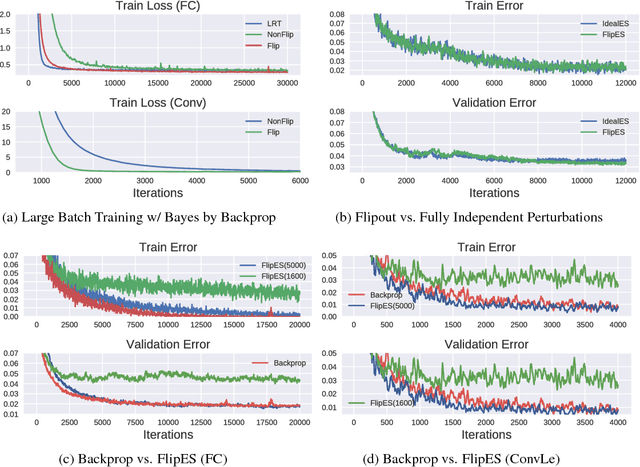
Stochastic neural net weights are used in a variety of contexts, including regularization, Bayesian neural nets, exploration in reinforcement learning, and evolution strategies. Unfortunately, due to the large number of weights, all the examples in a mini-batch typically share the same weight perturbation, thereby limiting the variance reduction effect of large mini-batches. We introduce flipout, an efficient method for decorrelating the gradients within a mini-batch by implicitly sampling pseudo-independent weight perturbations for each example. Empirically, flipout achieves the ideal linear variance reduction for fully connected networks, convolutional networks, and RNNs. We find significant speedups in training neural networks with multiplicative Gaussian perturbations. We show that flipout is effective at regularizing LSTMs, and outperforms previous methods. Flipout also enables us to vectorize evolution strategies: in our experiments, a single GPU with flipout can handle the same throughput as at least 40 CPU cores using existing methods, equivalent to a factor-of-4 cost reduction on Amazon Web Services.
Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation
Aug 18, 2017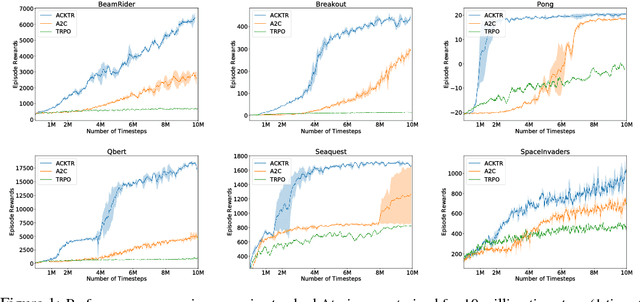
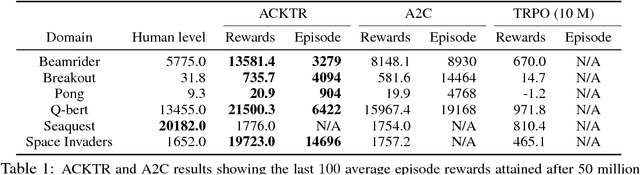
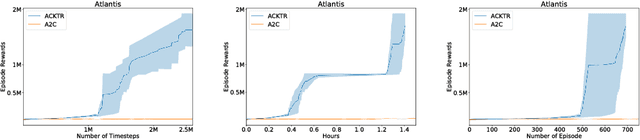
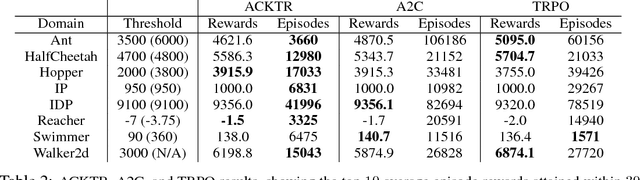
In this work, we propose to apply trust region optimization to deep reinforcement learning using a recently proposed Kronecker-factored approximation to the curvature. We extend the framework of natural policy gradient and propose to optimize both the actor and the critic using Kronecker-factored approximate curvature (K-FAC) with trust region; hence we call our method Actor Critic using Kronecker-Factored Trust Region (ACKTR). To the best of our knowledge, this is the first scalable trust region natural gradient method for actor-critic methods. It is also a method that learns non-trivial tasks in continuous control as well as discrete control policies directly from raw pixel inputs. We tested our approach across discrete domains in Atari games as well as continuous domains in the MuJoCo environment. With the proposed methods, we are able to achieve higher rewards and a 2- to 3-fold improvement in sample efficiency on average, compared to previous state-of-the-art on-policy actor-critic methods. Code is available at https://github.com/openai/baselines