 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Diffusion ODEs with Optimal Boundary Conditions for Better Image Super-Resolution
May 24, 2023Diffusion models, as a kind of powerful generative model, have given impressive results on image super-resolution (SR) tasks. However, due to the randomness introduced in the reverse process of diffusion models, the performances of diffusion-based SR models are fluctuating at every time of sampling, especially for samplers with few resampled steps. This inherent randomness of diffusion models results in ineffectiveness and instability, making it challenging for users to guarantee the quality of SR results. However, our work takes this randomness as an opportunity: fully analyzing and leveraging it leads to the construction of an effective plug-and-play sampling method that owns the potential to benefit a series of diffusion-based SR methods. More in detail, we propose to steadily sample high-quality SR images from pretrained diffusion-based SR models by solving diffusion ordinary differential equations (diffusion ODEs) with optimal boundary conditions (BCs) and analyze the characteristics between the choices of BCs and their corresponding SR results. Our analysis shows the route to obtain an approximately optimal BC via an efficient exploration in the whole space. The quality of SR results sampled by the proposed method with fewer steps outperforms the quality of results sampled by current methods with randomness from the same pretrained diffusion-based SR model, which means that our sampling method ``boosts'' current diffusion-based SR models without any additional training.
VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation
May 18, 2023



We present VideoFactory, an innovative framework for generating high-quality open-domain videos. VideoFactory excels in producing high-definition (1376x768), widescreen (16:9) videos without watermarks, creating an engaging user experience. Generating videos guided by text instructions poses significant challenges, such as modeling the complex relationship between space and time, and the lack of large-scale text-video paired data. Previous approaches extend pretrained text-to-image generation models by adding temporal 1D convolution/attention modules for video generation. However, these approaches overlook the importance of jointly modeling space and time, inevitably leading to temporal distortions and misalignment between texts and videos. In this paper, we propose a novel approach that strengthens the interaction between spatial and temporal perceptions. In particular, we utilize a swapped cross-attention mechanism in 3D windows that alternates the "query" role between spatial and temporal blocks, enabling mutual reinforcement for each other. To fully unlock model capabilities for high-quality video generation, we curate a large-scale video dataset called HD-VG-130M. This dataset comprises 130 million text-video pairs from the open-domain, ensuring high-definition, widescreen and watermark-free characters. Objective metrics and user studies demonstrate the superiority of our approach in terms of per-frame quality, temporal correlation, and text-video alignment, with clear margins.
Actionlet-Dependent Contrastive Learning for Unsupervised Skeleton-Based Action Recognition
Mar 21, 2023



The self-supervised pretraining paradigm has achieved great success in skeleton-based action recognition. However, these methods treat the motion and static parts equally, and lack an adaptive design for different parts, which has a negative impact on the accuracy of action recognition. To realize the adaptive action modeling of both parts, we propose an Actionlet-Dependent Contrastive Learning method (ActCLR). The actionlet, defined as the discriminative subset of the human skeleton, effectively decomposes motion regions for better action modeling. In detail, by contrasting with the static anchor without motion, we extract the motion region of the skeleton data, which serves as the actionlet, in an unsupervised manner. Then, centering on actionlet, a motion-adaptive data transformation method is built. Different data transformations are applied to actionlet and non-actionlet regions to introduce more diversity while maintaining their own characteristics. Meanwhile, we propose a semantic-aware feature pooling method to build feature representations among motion and static regions in a distinguished manner. Extensive experiments on NTU RGB+D and PKUMMD show that the proposed method achieves remarkable action recognition performance. More visualization and quantitative experiments demonstrate the effectiveness of our method. Our project website is available at https://langlandslin.github.io/projects/ActCLR/
Unified Multi-Modal Latent Diffusion for Joint Subject and Text Conditional Image Generation
Mar 16, 2023



Language-guided image generation has achieved great success nowadays by using diffusion models. However, texts can be less detailed to describe highly-specific subjects such as a particular dog or a certain car, which makes pure text-to-image generation not accurate enough to satisfy user requirements. In this work, we present a novel Unified Multi-Modal Latent Diffusion (UMM-Diffusion) which takes joint texts and images containing specified subjects as input sequences and generates customized images with the subjects. To be more specific, both input texts and images are encoded into one unified multi-modal latent space, in which the input images are learned to be projected to pseudo word embedding and can be further combined with text to guide image generation. Besides, to eliminate the irrelevant parts of the input images such as background or illumination, we propose a novel sampling technique of diffusion models used by the image generator which fuses the results guided by multi-modal input and pure text input. By leveraging the large-scale pre-trained text-to-image generator and the designed image encoder, our method is able to generate high-quality images with complex semantics from both aspects of input texts and images.
Hierarchical Consistent Contrastive Learning for Skeleton-Based Action Recognition with Growing Augmentations
Nov 24, 2022



Contrastive learning has been proven beneficial for self-supervised skeleton-based action recognition. Most contrastive learning methods utilize carefully designed augmentations to generate different movement patterns of skeletons for the same semantics. However, it is still a pending issue to apply strong augmentations, which distort the images/skeletons' structures and cause semantic loss, due to their resulting unstable training. In this paper, we investigate the potential of adopting strong augmentations and propose a general hierarchical consistent contrastive learning framework (HiCLR) for skeleton-based action recognition. Specifically, we first design a gradual growing augmentation policy to generate multiple ordered positive pairs, which guide to achieve the consistency of the learned representation from different views. Then, an asymmetric loss is proposed to enforce the hierarchical consistency via a directional clustering operation in the feature space, pulling the representations from strongly augmented views closer to those from weakly augmented views for better generalizability. Meanwhile, we propose and evaluate three kinds of strong augmentations for 3D skeletons to demonstrate the effectiveness of our method. Extensive experiments show that HiCLR outperforms the state-of-the-art methods notably on three large-scale datasets, i.e., NTU60, NTU120, and PKUMMD.
Self-Aligned Concave Curve: Illumination Enhancement for Unsupervised Adaptation
Oct 07, 2022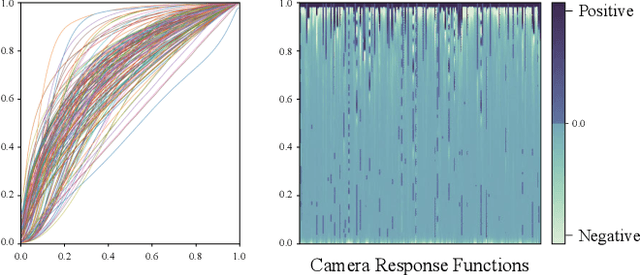
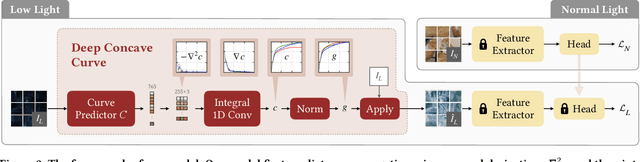

Low light conditions not only degrade human visual experience, but also reduce the performance of downstream machine analytics. Although many works have been designed for low-light enhancement or domain adaptive machine analytics, the former considers less on high-level vision, while the latter neglects the potential of image-level signal adjustment. How to restore underexposed images/videos from the perspective of machine vision has long been overlooked. In this paper, we are the first to propose a learnable illumination enhancement model for high-level vision. Inspired by real camera response functions, we assume that the illumination enhancement function should be a concave curve, and propose to satisfy this concavity through discrete integral. With the intention of adapting illumination from the perspective of machine vision without task-specific annotated data, we design an asymmetric cross-domain self-supervised training strategy. Our model architecture and training designs mutually benefit each other, forming a powerful unsupervised normal-to-low light adaptation framework. Comprehensive experiments demonstrate that our method surpasses existing low-light enhancement and adaptation methods and shows superior generalization on various low-light vision tasks, including classification, detection, action recognition, and optical flow estimation. Project website: https://daooshee.github.io/SACC-Website/
AI Illustrator: Translating Raw Descriptions into Images by Prompt-based Cross-Modal Generation
Sep 08, 2022
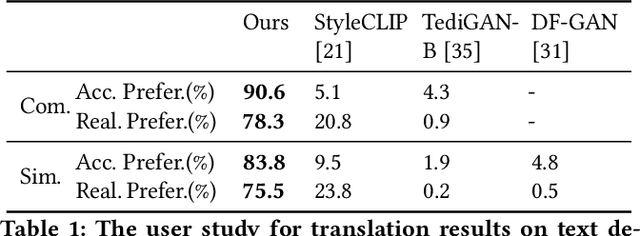
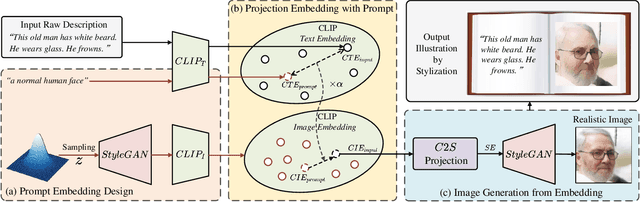
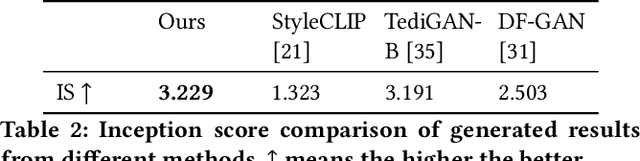
AI illustrator aims to automatically design visually appealing images for books to provoke rich thoughts and emotions. To achieve this goal, we propose a framework for translating raw descriptions with complex semantics into semantically corresponding images. The main challenge lies in the complexity of the semantics of raw descriptions, which may be hard to be visualized (e.g., "gloomy" or "Asian"). It usually poses challenges for existing methods to handle such descriptions. To address this issue, we propose a Prompt-based Cross-Modal Generation Framework (PCM-Frame) to leverage two powerful pre-trained models, including CLIP and StyleGAN. Our framework consists of two components: a projection module from Text Embeddings to Image Embeddings based on prompts, and an adapted image generation module built on StyleGAN which takes Image Embeddings as inputs and is trained by combined semantic consistency losses. To bridge the gap between realistic images and illustration designs, we further adopt a stylization model as post-processing in our framework for better visual effects. Benefiting from the pre-trained models, our method can handle complex descriptions and does not require external paired data for training. Furthermore, we have built a benchmark that consists of 200 raw descriptions. We conduct a user study to demonstrate our superiority over the competing methods with complicated texts. We release our code at https://github.com/researchmm/AI_Illustrator.
Meta-Interpolation: Time-Arbitrary Frame Interpolation via Dual Meta-Learning
Jul 27, 2022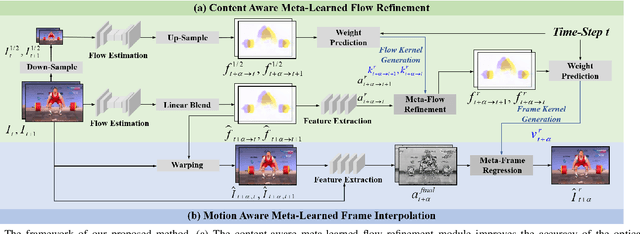


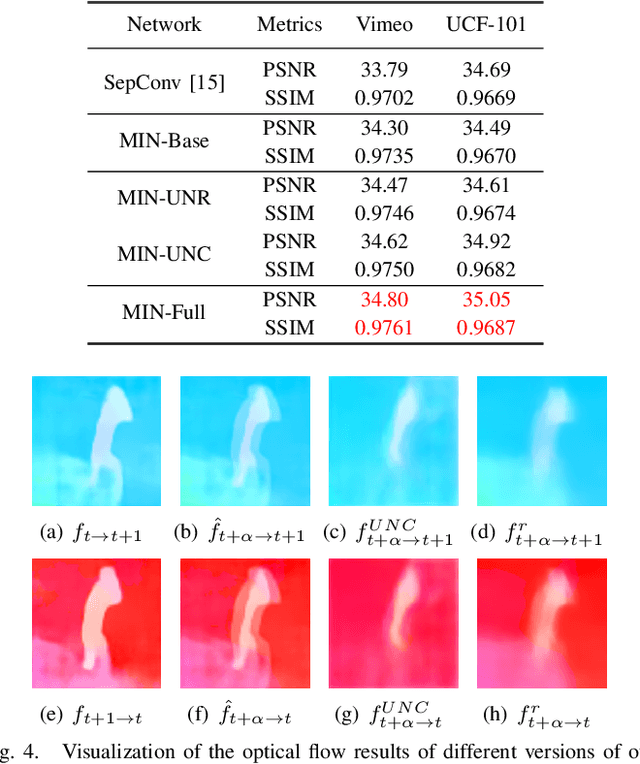
Existing video frame interpolation methods can only interpolate the frame at a given intermediate time-step, e.g. 1/2. In this paper, we aim to explore a more generalized kind of video frame interpolation, that at an arbitrary time-step. To this end, we consider processing different time-steps with adaptively generated convolutional kernels in a unified way with the help of meta-learning. Specifically, we develop a dual meta-learned frame interpolation framework to synthesize intermediate frames with the guidance of context information and optical flow as well as taking the time-step as side information. First, a content-aware meta-learned flow refinement module is built to improve the accuracy of the optical flow estimation based on the down-sampled version of the input frames. Second, with the refined optical flow and the time-step as the input, a motion-aware meta-learned frame interpolation module generates the convolutional kernels for every pixel used in the convolution operations on the feature map of the coarse warped version of the input frames to generate the predicted frame. Extensive qualitative and quantitative evaluations, as well as ablation studies, demonstrate that, via introducing meta-learning in our framework in such a well-designed way, our method not only achieves superior performance to state-of-the-art frame interpolation approaches but also owns an extended capacity to support the interpolation at an arbitrary time-step.
S$^{5}$Mars: Self-Supervised and Semi-Supervised Learning for Mars Segmentation
Jul 04, 2022
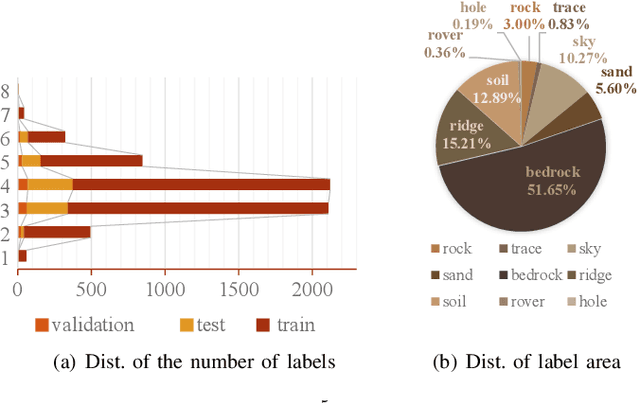
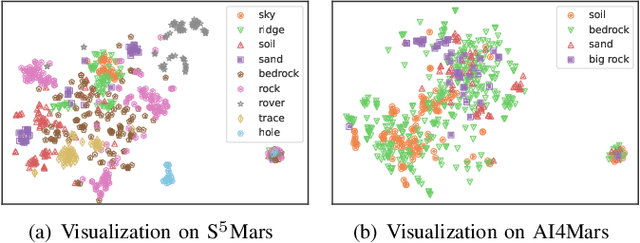
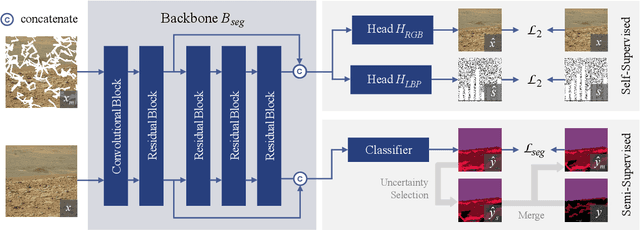
Deep learning has become a powerful tool for Mars exploration. Mars terrain segmentation is an important Martian vision task, which is the base of rover autonomous planning and safe driving. However, existing deep-learning-based terrain segmentation methods face two problems: one is the lack of sufficient detailed and high-confidence annotations, and the other is the over-reliance of models on annotated training data. In this paper, we address these two problems from the perspective of joint data and method design. We first present a new Mars terrain segmentation dataset which contains 6K high-resolution images and is sparsely annotated based on confidence, ensuring the high quality of labels. Then to learn from this sparse data, we propose a representation-learning-based framework for Mars terrain segmentation, including a self-supervised learning stage (for pre-training) and a semi-supervised learning stage (for fine-tuning). Specifically, for self-supervised learning, we design a multi-task mechanism based on the masked image modeling (MIM) concept to emphasize the texture information of images. For semi-supervised learning, since our dataset is sparsely annotated, we encourage the model to excavate the information of unlabeled area in each image by generating and utilizing pseudo-labels online. We name our dataset and method Self-Supervised and Semi-Supervised Segmentation for Mars (S$^{5}$Mars). Experimental results show that our method can outperform state-of-the-art approaches and improve terrain segmentation performance by a large margin.
Semi-Supervised Learning for Mars Imagery Classification and Segmentation
Jun 05, 2022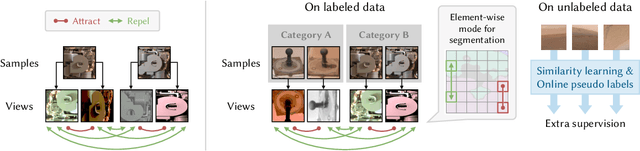
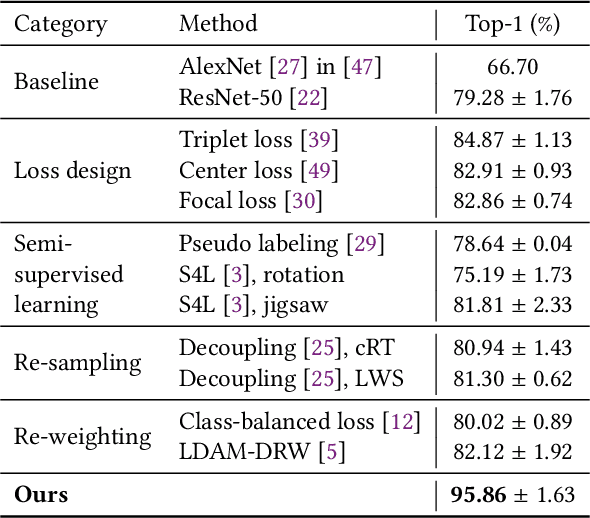
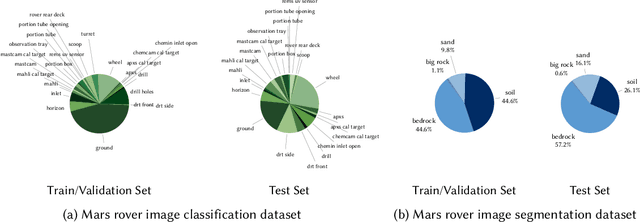
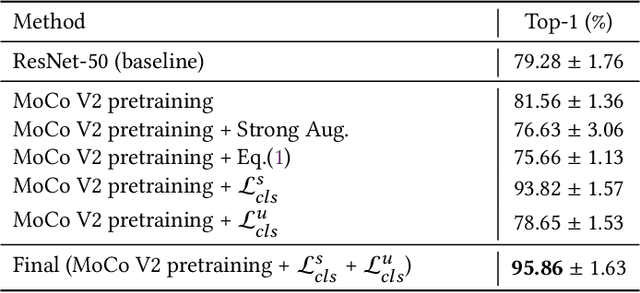
With the progress of Mars exploration, numerous Mars image data are collected and need to be analyzed. However, due to the imbalance and distortion of Martian data, the performance of existing computer vision models is unsatisfactory. In this paper, we introduce a semi-supervised framework for machine vision on Mars and try to resolve two specific tasks: classification and segmentation. Contrastive learning is a powerful representation learning technique. However, there is too much information overlap between Martian data samples, leading to a contradiction between contrastive learning and Martian data. Our key idea is to reconcile this contradiction with the help of annotations and further take advantage of unlabeled data to improve performance. For classification, we propose to ignore inner-class pairs on labeled data as well as neglect negative pairs on unlabeled data, forming supervised inter-class contrastive learning and unsupervised similarity learning. For segmentation, we extend supervised inter-class contrastive learning into an element-wise mode and use online pseudo labels for supervision on unlabeled areas. Experimental results show that our learning strategies can improve the classification and segmentation models by a large margin and outperform state-of-the-art approaches.