 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-stream Hybrid CNN-Transformer Network for Skeleton-based Human Interaction Recognition
Dec 31, 2023Human Interaction Recognition is the process of identifying interactive actions between multiple participants in a specific situation. The aim is to recognise the action interactions between multiple entities and their meaning. Many single Convolutional Neural Network has issues, such as the inability to capture global instance interaction features or difficulty in training, leading to ambiguity in action semantics. In addition, the computational complexity of the Transformer cannot be ignored, and its ability to capture local information and motion features in the image is poor. In this work, we propose a Two-stream Hybrid CNN-Transformer Network (THCT-Net), which exploits the local specificity of CNN and models global dependencies through the Transformer. CNN and Transformer simultaneously model the entity, time and space relationships between interactive entities respectively. Specifically, Transformer-based stream integrates 3D convolutions with multi-head self-attention to learn inter-token correlations; We propose a new multi-branch CNN framework for CNN-based streams that automatically learns joint spatio-temporal features from skeleton sequences. The convolutional layer independently learns the local features of each joint neighborhood and aggregates the features of all joints. And the raw skeleton coordinates as well as their temporal difference are integrated with a dual-branch paradigm to fuse the motion features of the skeleton. Besides, a residual structure is added to speed up training convergence. Finally, the recognition results of the two branches are fused using parallel splicing. Experimental results on diverse and challenging datasets, demonstrate that the proposed method can better comprehend and infer the meaning and context of various actions, outperforming state-of-the-art methods.
Lifting by Image -- Leveraging Image Cues for Accurate 3D Human Pose Estimation
Dec 25, 2023The "lifting from 2D pose" method has been the dominant approach to 3D Human Pose Estimation (3DHPE) due to the powerful visual analysis ability of 2D pose estimators. Widely known, there exists a depth ambiguity problem when estimating solely from 2D pose, where one 2D pose can be mapped to multiple 3D poses. Intuitively, the rich semantic and texture information in images can contribute to a more accurate "lifting" procedure. Yet, existing research encounters two primary challenges. Firstly, the distribution of image data in 3D motion capture datasets is too narrow because of the laboratorial environment, which leads to poor generalization ability of methods trained with image information. Secondly, effective strategies for leveraging image information are lacking. In this paper, we give new insight into the cause of poor generalization problems and the effectiveness of image features. Based on that, we propose an advanced framework. Specifically, the framework consists of two stages. First, we enable the keypoints to query and select the beneficial features from all image patches. To reduce the keypoints attention to inconsequential background features, we design a novel Pose-guided Transformer Layer, which adaptively limits the updates to unimportant image patches. Then, through a designed Adaptive Feature Selection Module, we prune less significant image patches from the feature map. In the second stage, we allow the keypoints to further emphasize the retained critical image features. This progressive learning approach prevents further training on insignificant image features. Experimental results show that our model achieves state-of-the-art performance on both the Human3.6M dataset and the MPI-INF-3DHP dataset.
BiHRNet: A Binary high-resolution network for Human Pose Estimation
Nov 17, 2023Human Pose Estimation (HPE) plays a crucial role in computer vision applications. However, it is difficult to deploy state-of-the-art models on resouce-limited devices due to the high computational costs of the networks. In this work, a binary human pose estimator named BiHRNet(Binary HRNet) is proposed, whose weights and activations are expressed as $\pm$1. BiHRNet retains the keypoint extraction ability of HRNet, while using fewer computing resources by adapting binary neural network (BNN). In order to reduce the accuracy drop caused by network binarization, two categories of techniques are proposed in this work. For optimizing the training process for binary pose estimator, we propose a new loss function combining KL divergence loss with AWing loss, which makes the binary network obtain more comprehensive output distribution from its real-valued counterpart to reduce information loss caused by binarization. For designing more binarization-friendly structures, we propose a new information reconstruction bottleneck called IR Bottleneck to retain more information in the initial stage of the network. In addition, we also propose a multi-scale basic block called MS-Block for information retention. Our work has less computation cost with few precision drop. Experimental results demonstrate that BiHRNet achieves a PCKh of 87.9 on the MPII dataset, which outperforms all binary pose estimation networks. On the challenging of COCO dataset, the proposed method enables the binary neural network to achieve 70.8 mAP, which is better than most tested lightweight full-precision networks.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
Topology-aware MLP for Skeleton-based Action Recognition
Sep 04, 2023


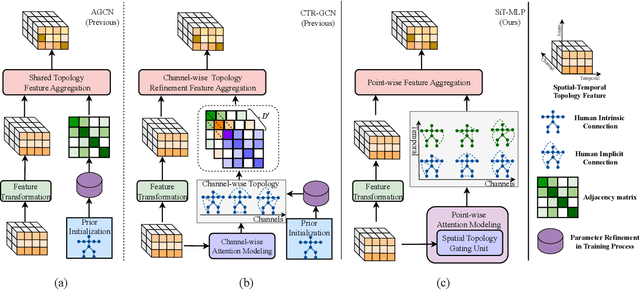
Graph convolution networks (GCNs) have achieved remarkable performance in skeleton-based action recognition. However, existing previous GCN-based methods have relied excessively on elaborate human body priors and constructed complex feature aggregation mechanisms, which limits the generalizability of networks. To solve these problems, we propose a novel Spatial Topology Gating Unit (STGU), which is an MLP-based variant without extra priors, to capture the co-occurrence topology features that encode the spatial dependency across all joints. In STGU, to model the sample-specific and completely independent point-wise topology attention, a new gate-based feature interaction mechanism is introduced to activate the features point-to-point by the attention map generated from the input. Based on the STGU, in this work, we propose the first topology-aware MLP-based model, Ta-MLP, for skeleton-based action recognition. In comparison with existing previous methods on three large-scale datasets, Ta-MLP achieves competitive performance. In addition, Ta-MLP reduces the parameters by up to 62.5% with favorable results. Compared with previous state-of-the-art (SOAT) approaches, Ta-MLP pushes the frontier of real-time action recognition. The code will be available at https://github.com/BUPTSJZhang/Ta-MLP.
Evaluating the Adversarial Robustness of Convolution-based Human Motion Prediction
Jul 03, 2023Human motion prediction has achieved a brilliant performance with the help of CNNs, which facilitates human-machine cooperation. However, currently, there is no work evaluating the potential risk in human motion prediction when facing adversarial attacks, which may cause danger in real applications. The adversarial attack will face two problems against human motion prediction: 1. For naturalness, pose data is highly related to the physical dynamics of human skeletons where Lp norm constraints cannot constrain the adversarial example well; 2. Unlike the pixel value in images, pose data is diverse at scale because of the different acquisition equipment and the data processing, which makes it hard to set fixed parameters to perform attacks. To solve the problems above, we propose a new adversarial attack method that perturbs the input human motion sequence by maximizing the prediction error with physical constraints. Specifically, we introduce a novel adaptable scheme that facilitates the attack to suit the scale of the target pose and two physical constraints to enhance the imperceptibility of the adversarial example. The evaluating experiments on three datasets show that the prediction errors of all target models are enlarged significantly, which means current convolution-based human motion prediction models can be easily disturbed under the proposed attack. The quantitative analysis shows that prior knowledge and semantic information modeling can be the key to the adversarial robustness of human motion predictors. The qualitative results indicate that the adversarial sample is hard to be noticed when compared frame by frame but is relatively easy to be detected when the sample is animated.
Target-Aware Spatio-Temporal Reasoning via Answering Questions in Dynamics Audio-Visual Scenarios
May 21, 2023Audio-visual question answering (AVQA) is a challenging task that requires multistep spatio-temporal reasoning over multimodal contexts. To achieve scene understanding ability similar to humans, the AVQA task presents specific challenges, including effectively fusing audio and visual information and capturing question-relevant audio-visual features while maintaining temporal synchronization. This paper proposes a Target-aware Joint Spatio-Temporal Grounding Network for AVQA to address these challenges. The proposed approach has two main components: the Target-aware Spatial Grounding module, the Tri-modal consistency loss and corresponding Joint audio-visual temporal grounding module. The Target-aware module enables the model to focus on audio-visual cues relevant to the inquiry subject by exploiting the explicit semantics of text modality. The Tri-modal consistency loss facilitates the interaction between audio and video during question-aware temporal grounding and incorporates fusion within a simpler single-stream architecture. Experimental results on the MUSIC-AVQA dataset demonstrate the effectiveness and superiority of the proposed method over existing state-of-the-art methods. Our code will be availiable soon.
SDVRF: Sparse-to-Dense Voxel Region Fusion for Multi-modal 3D Object Detection
May 02, 2023In the perception task of autonomous driving, multi-modal methods have become a trend due to the complementary characteristics of LiDAR point clouds and image data. However, the performance of previous methods is usually limited by the sparsity of the point cloud or the noise problem caused by the misalignment between LiDAR and the camera. To solve these two problems, we present a new concept, Voxel Region (VR), which is obtained by projecting the sparse local point clouds in each voxel dynamically. And we propose a novel fusion method, named Sparse-to-Dense Voxel Region Fusion (SDVRF). Specifically, more pixels of the image feature map inside the VR are gathered to supplement the voxel feature extracted from sparse points and achieve denser fusion. Meanwhile, different from prior methods, which project the size-fixed grids, our strategy of generating dynamic regions achieves better alignment and avoids introducing too much background noise. Furthermore, we propose a multi-scale fusion framework to extract more contextual information and capture the features of objects of different sizes. Experiments on the KITTI dataset show that our method improves the performance of different baselines, especially on classes of small size, including Pedestrian and Cyclist.
MLP-AIR: An Efficient MLP-Based Method for Actor Interaction Relation Learning in Group Activity Recognition
Apr 18, 2023



The task of Group Activity Recognition (GAR) aims to predict the activity category of the group by learning the actor spatial-temporal interaction relation in the group. Therefore, an effective actor relation learning method is crucial for the GAR task. The previous works mainly learn the interaction relation by the well-designed GCNs or Transformers. For example, to infer the actor interaction relation, GCNs need a learnable adjacency, and Transformers need to calculate the self-attention. Although the above methods can model the interaction relation effectively, they also increase the complexity of the model (the number of parameters and computations). In this paper, we design a novel MLP-based method for Actor Interaction Relation learning (MLP-AIR) in GAR. Compared with GCNs and Transformers, our method has a competitive but conceptually and technically simple alternative, significantly reducing the complexity. Specifically, MLP-AIR includes three sub-modules: MLP-based Spatial relation modeling module (MLP-S), MLP-based Temporal relation modeling module (MLP-T), and MLP-based Relation refining module (MLP-R). MLP-S is used to model the spatial relation between different actors in each frame. MLP-T is used to model the temporal relation between different frames for each actor. MLP-R is used further to refine the relation between different dimensions of relation features to improve the feature's expression ability. To evaluate the MLP-AIR, we conduct extensive experiments on two widely used benchmarks, including the Volleyball and Collective Activity datasets. Experimental results demonstrate that MLP-AIR can get competitive results but with low complexity.
Global Relation Modeling and Refinement for Bottom-Up Human Pose Estimation
Mar 27, 2023In this paper, we concern on the bottom-up paradigm in multi-person pose estimation (MPPE). Most previous bottom-up methods try to consider the relation of instances to identify different body parts during the post processing, while ignoring to model the relation among instances or environment in the feature learning process. In addition, most existing works adopt the operations of upsampling and downsampling. During the sampling process, there will be a problem of misalignment with the source features, resulting in deviations in the keypoint features learned by the model. To overcome the above limitations, we propose a convolutional neural network for bottom-up human pose estimation. It invovles two basic modules: (i) Global Relation Modeling (GRM) module globally learns relation (e.g., environment context, instance interactive information) among region of image by fusing multiple stages features in the feature learning process. It combines with the spatial-channel attention mechanism, which focuses on achieving adaptability in spatial and channel dimensions. (ii) Multi-branch Feature Align (MFA) module aggregates features from multiple branches to align fused feature and obtain refined local keypoint representation. Our model has the ability to focus on different granularity from local to global regions, which significantly boosts the performance of the multi-person pose estimation. Our results on the COCO and CrowdPose datasets demonstrate that it is an efficient framework for multi-person pose estimation.