 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Testable Certificate for Constant Collapse in Teacher-Guided VAEs
May 07, 2026Posterior collapse in variational autoencoders is often diagnosed by its symptoms: a small KL term, a strong decoder, or weak use of the latent code. These signals are useful, but they do not define a collapse boundary. We study a concrete failure mode, input-independent constant collapse, and show that this case admits an exact threshold. For any fixed nonconstant teacher distribution \(T(\cdot\mid x)\), the best constant student is the dataset-average teacher distribution, and its alignment cost is the teacher mutual information \(I_T(X;T)\). Therefore, if a strictly latent-only raw witness achieves alignment loss below this value, with a safety margin, the witness cannot be constant in the input. This identity turns a qualitative failure mode into a measurable one. In CIFAR-100 experiments with per-seed teacher search, full training stays on the certified side of the boundary, removing alignment drives the raw witness into the constant-student regime, and restarting from a collapsed checkpoint with alignment enabled restores the certificate. Tiny-ImageNet-200 fixed-target runs show the same prevention--collapse--rescue pattern across three independently searched teachers. Standard VAE-style baselines, including methods that preserve reconstruction quality or post-hoc predictability, remain negative under the raw certificate. The guarantee is intentionally narrow: it certifies that the matched nonconstant teacher-relative variation passes through the latent pathway, rather than claiming that all forms of posterior collapse have been ruled out.
TSAM: Temporal Link Prediction in Directed Networks based on Self-Attention Mechanism
Aug 23, 2020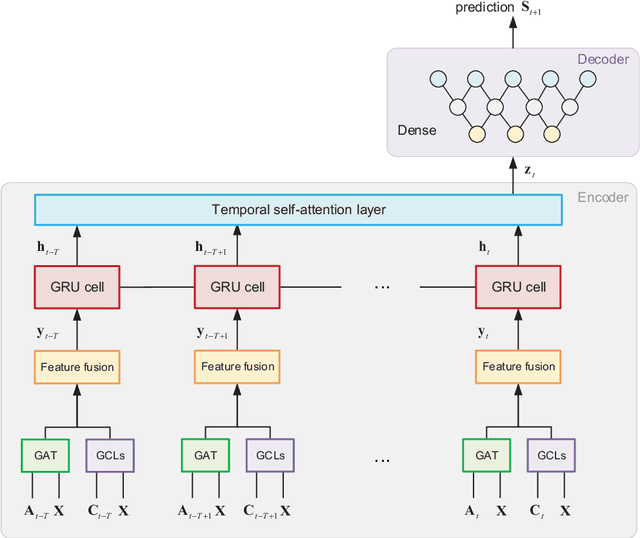
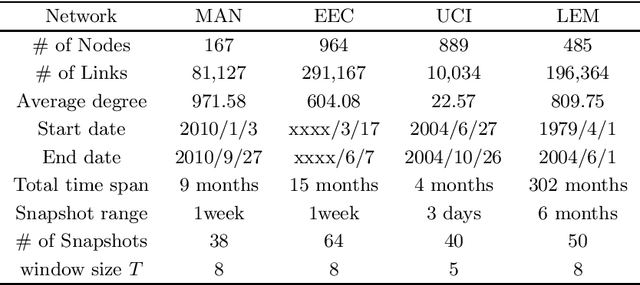

The development of graph neural networks (GCN) makes it possible to learn structural features from evolving complex networks. Even though a wide range of realistic networks are directed ones, few existing works investigated the properties of directed and temporal networks. In this paper, we address the problem of temporal link prediction in directed networks and propose a deep learning model based on GCN and self-attention mechanism, namely TSAM. The proposed model adopts an autoencoder architecture, which utilizes graph attentional layers to capture the structural feature of neighborhood nodes, as well as a set of graph convolutional layers to capture motif features. A graph recurrent unit layer with self-attention is utilized to learn temporal variations in the snapshot sequence. We run comparative experiments on four realistic networks to validate the effectiveness of TSAM. Experimental results show that TSAM outperforms most benchmarks under two evaluation metrics.
Sparse Coding with Earth Mover's Distance for Multi-Instance Histogram Representation
Mar 14, 2016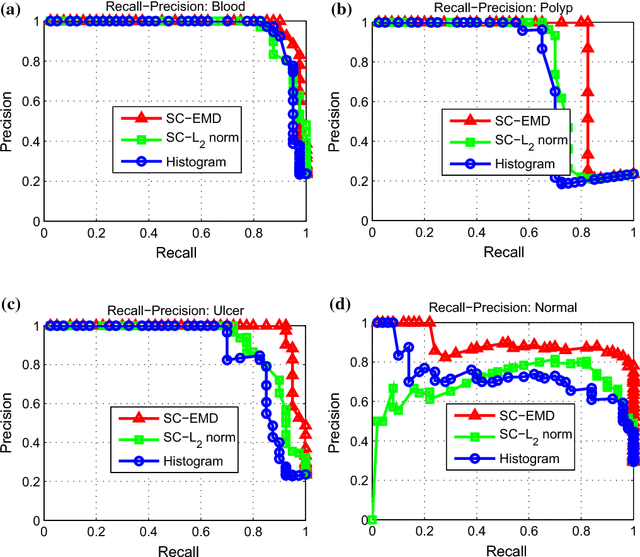
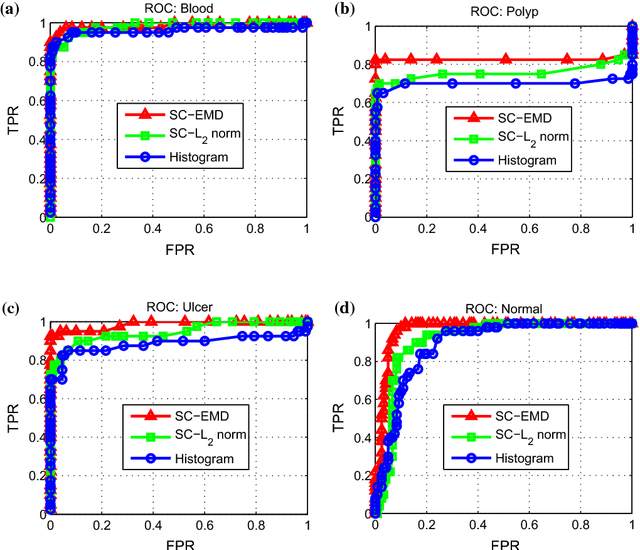
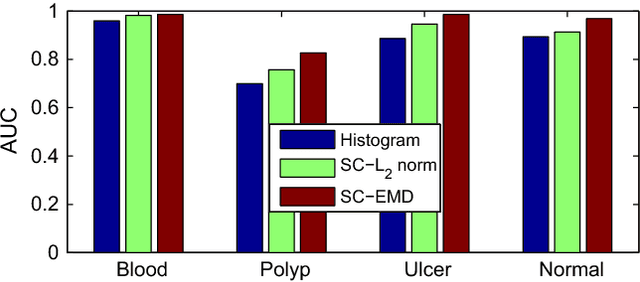
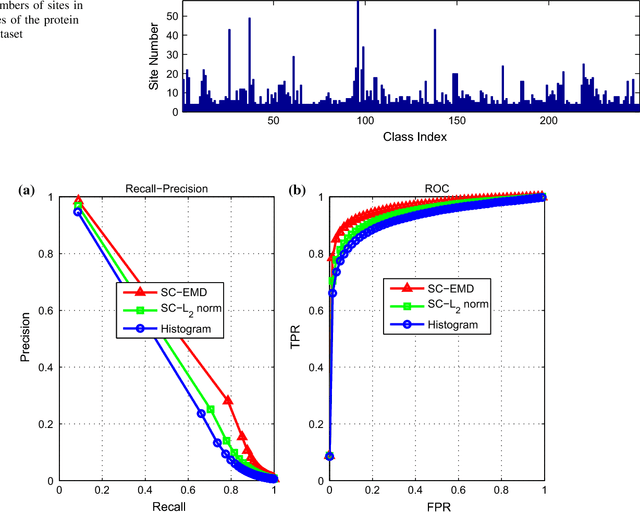
Sparse coding (Sc) has been studied very well as a powerful data representation method. It attempts to represent the feature vector of a data sample by reconstructing it as the sparse linear combination of some basic elements, and a $L_2$ norm distance function is usually used as the loss function for the reconstruction error. In this paper, we investigate using Sc as the representation method within multi-instance learning framework, where a sample is given as a bag of instances, and further represented as a histogram of the quantized instances. We argue that for the data type of histogram, using $L_2$ norm distance is not suitable, and propose to use the earth mover's distance (EMD) instead of $L_2$ norm distance as a measure of the reconstruction error. By minimizing the EMD between the histogram of a sample and the its reconstruction from some basic histograms, a novel sparse coding method is developed, which is refereed as SC-EMD. We evaluate its performances as a histogram representation method in tow multi-instance learning problems --- abnormal image detection in wireless capsule endoscopy videos, and protein binding site retrieval. The encouraging results demonstrate the advantages of the new method over the traditional method using $L_2$ norm distance.