 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory of Usable Information Under Computational Constraints
Feb 25, 2020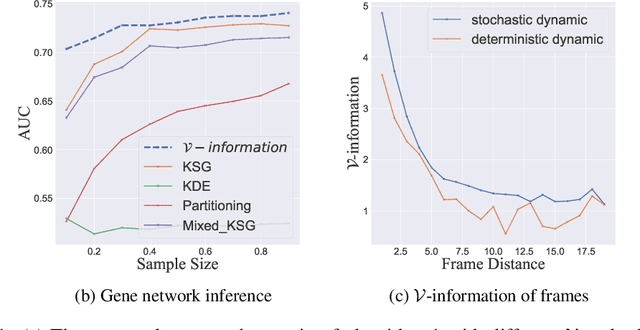
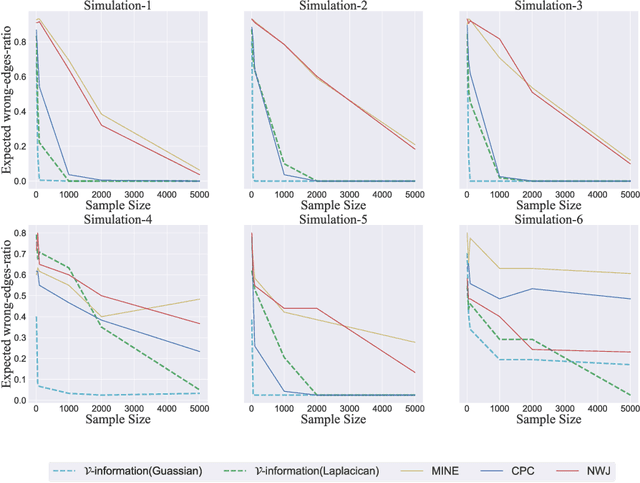

We propose a new framework for reasoning about information in complex systems. Our foundation is based on a variational extension of Shannon's information theory that takes into account the modeling power and computational constraints of the observer. The resulting \emph{predictive $\mathcal{V}$-information} encompasses mutual information and other notions of informativeness such as the coefficient of determination. Unlike Shannon's mutual information and in violation of the data processing inequality, $\mathcal{V}$-information can be created through computation. This is consistent with deep neural networks extracting hierarchies of progressively more informative features in representation learning. Additionally, we show that by incorporating computational constraints, $\mathcal{V}$-information can be reliably estimated from data even in high dimensions with PAC-style guarantees. Empirically, we demonstrate predictive $\mathcal{V}$-information is more effective than mutual information for structure learning and fair representation learning.
Bridging the Gap Between $f$-GANs and Wasserstein GANs
Oct 22, 2019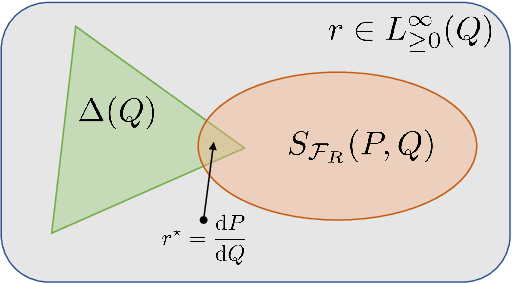

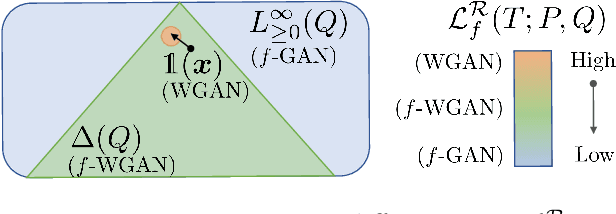
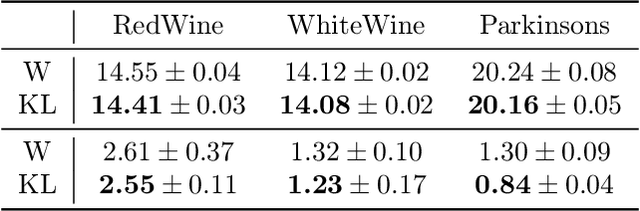
Generative adversarial networks (GANs) have enjoyed much success in learning high-dimensional distributions. Learning objectives approximately minimize an $f$-divergence ($f$-GANs) or an integral probability metric (Wasserstein GANs) between the model and the data distribution using a discriminator. Wasserstein GANs enjoy superior empirical performance, but in $f$-GANs the discriminator can be interpreted as a density ratio estimator which is necessary in some GAN applications. In this paper, we bridge the gap between $f$-GANs and Wasserstein GANs (WGANs). First, we list two constraints over variational $f$-divergence estimation objectives that preserves the optimal solution. Next, we minimize over a Lagrangian relaxation of the constrained objective, and show that it generalizes critic objectives of both $f$-GAN and WGAN. Based on this generalization, we propose a novel practical objective, named KL-Wasserstein GAN (KL-WGAN). We demonstrate empirical success of KL-WGAN on synthetic datasets and real-world image generation benchmarks, and achieve state-of-the-art FID scores on CIFAR10 image generation.
Unsupervised Out-of-Distribution Detection with Batch Normalization
Oct 21, 2019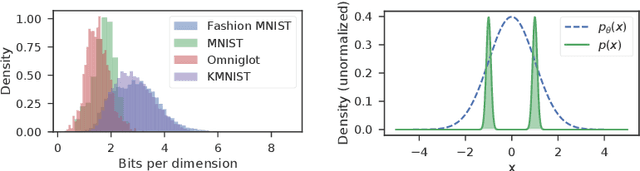
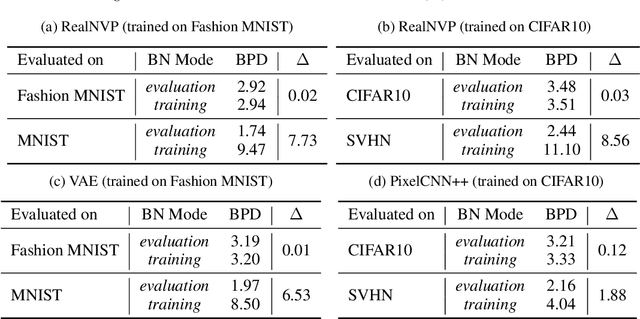
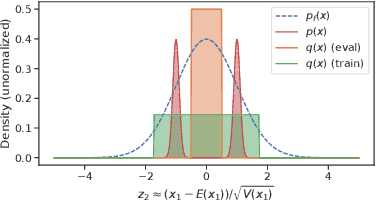
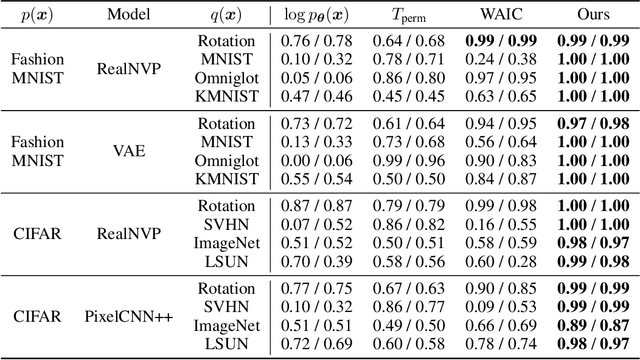
Likelihood from a generative model is a natural statistic for detecting out-of-distribution (OoD) samples. However, generative models have been shown to assign higher likelihood to OoD samples compared to ones from the training distribution, preventing simple threshold-based detection rules. We demonstrate that OoD detection fails even when using more sophisticated statistics based on the likelihoods of individual samples. To address these issues, we propose a new method that leverages batch normalization. We argue that batch normalization for generative models challenges the traditional i.i.d. data assumption and changes the corresponding maximum likelihood objective. Based on this insight, we propose to exploit in-batch dependencies for OoD detection. Empirical results suggest that this leads to more robust detection for high-dimensional images.
Understanding the Limitations of Variational Mutual Information Estimators
Oct 14, 2019
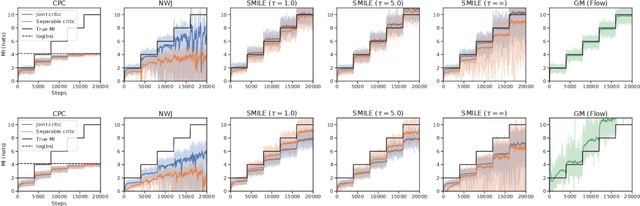
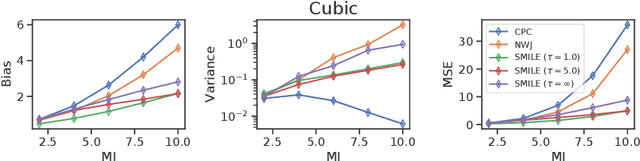
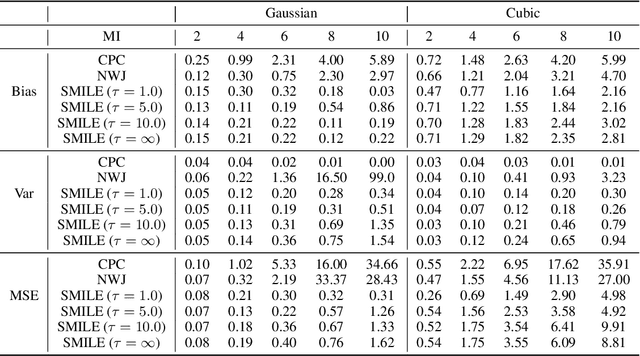
Variational approaches based on neural networks are showing promise for estimating mutual information (MI) between high dimensional variables. However, they can be difficult to use in practice due to poorly understood bias/variance tradeoffs. We theoretically show that, under some conditions, estimators such as MINE exhibit variance that could grow exponentially with the true amount of underlying MI. We also empirically demonstrate that existing estimators fail to satisfy basic self-consistency properties of MI, such as data processing and additivity under independence. Based on a unified perspective of variational approaches, we develop a new estimator that focuses on variance reduction. Empirical results on standard benchmark tasks demonstrate that our proposed estimator exhibits improved bias-variance trade-offs on standard benchmark tasks.
Cross Domain Imitation Learning
Sep 30, 2019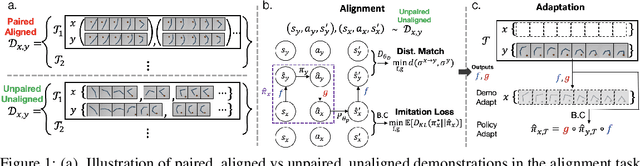
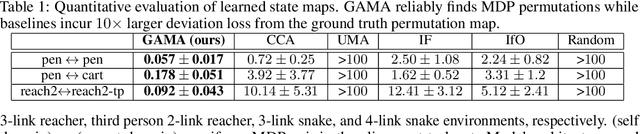
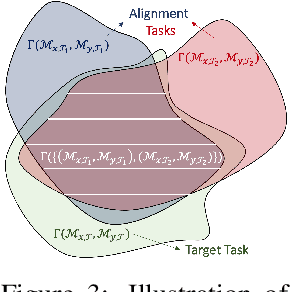
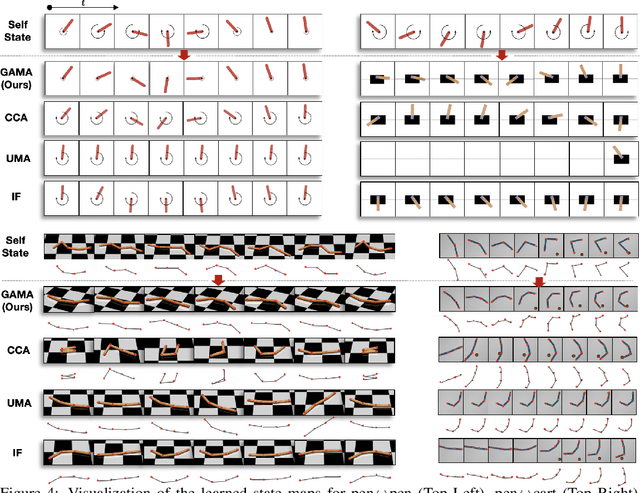
We study the question of how to imitate tasks across domains with discrepancies such as embodiment and viewpoint mismatch. Many prior works require paired, aligned demonstrations and an additional RL procedure for the task. However, paired, aligned demonstrations are seldom obtainable and RL procedures are expensive. In this work, we formalize the Cross Domain Imitation Learning (CDIL) problem, which encompasses imitation learning in the presence of viewpoint and embodiment mismatch. Informally, CDIL is the process of learning how to perform a task optimally, given demonstrations of the task in a distinct domain. We propose a two step approach to CDIL: alignment followed by adaptation. In the alignment step we execute a novel unsupervised MDP alignment algorithm, Generative Adversarial MDP Alignment (GAMA), to learn state and action correspondences from unpaired, unaligned demonstrations. In the adaptation step we leverage the correspondences to zero-shot imitate tasks across domains. To describe when CDIL is feasible via alignment and adaptation, we introduce a theory of MDP alignability. We experimentally evaluate GAMA against baselines in both embodiment and viewpoint mismatch scenarios where aligned demonstrations don't exist and show the effectiveness of our approach.
Multi-Agent Adversarial Inverse Reinforcement Learning
Jul 30, 2019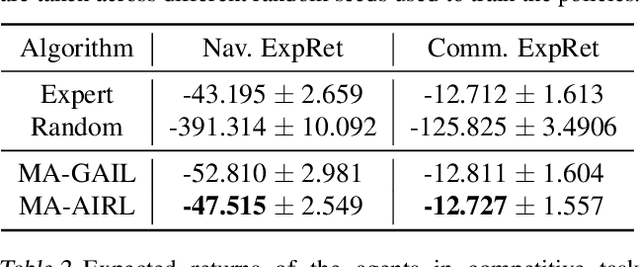
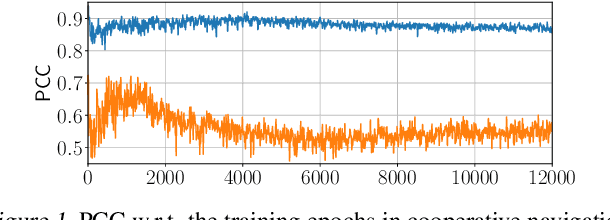
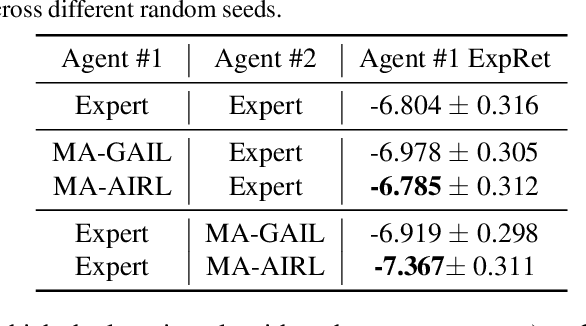
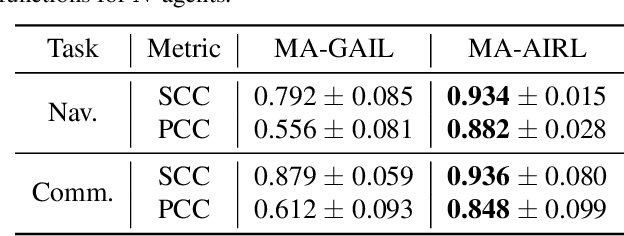
Reinforcement learning agents are prone to undesired behaviors due to reward mis-specification. Finding a set of reward functions to properly guide agent behaviors is particularly challenging in multi-agent scenarios. Inverse reinforcement learning provides a framework to automatically acquire suitable reward functions from expert demonstrations. Its extension to multi-agent settings, however, is difficult due to the more complex notions of rational behaviors. In this paper, we propose MA-AIRL, a new framework for multi-agent inverse reinforcement learning, which is effective and scalable for Markov games with high-dimensional state-action space and unknown dynamics. We derive our algorithm based on a new solution concept and maximum pseudolikelihood estimation within an adversarial reward learning framework. In the experiments, we demonstrate that MA-AIRL can recover reward functions that are highly correlated with ground truth ones, and significantly outperforms prior methods in terms of policy imitation.
Bias Correction of Learned Generative Models using Likelihood-Free Importance Weighting
Jun 23, 2019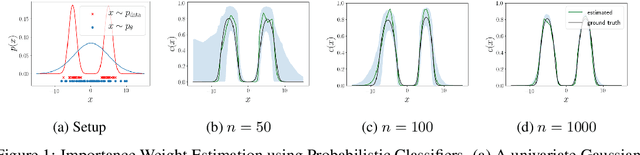

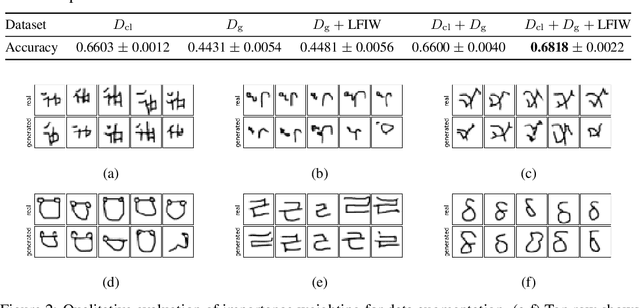
A learned generative model often produces biased statistics relative to the underlying data distribution. A standard technique to correct this bias is importance sampling, where samples from the model are weighted by the likelihood ratio under model and true distributions. When the likelihood ratio is unknown, it can be estimated by training a probabilistic classifier to distinguish samples from the two distributions. In this paper, we employ this likelihood-free importance weighting framework to correct for the bias in state-of-the-art deep generative models. We find that this technique consistently improves standard goodness-of-fit metrics for evaluating the sample quality of state-of-the-art generative models, suggesting reduced bias. Finally, we demonstrate its utility on representative applications in a) data augmentation for classification using generative adversarial networks, and b) model-based policy evaluation using off-policy data.
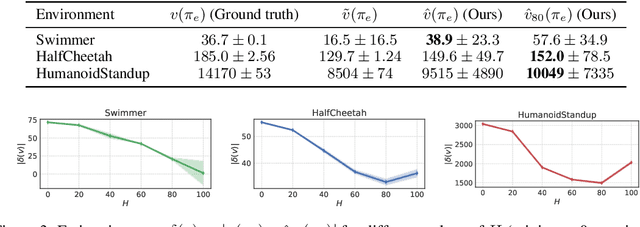
Calibrated Model-Based Deep Reinforcement Learning
Jun 19, 2019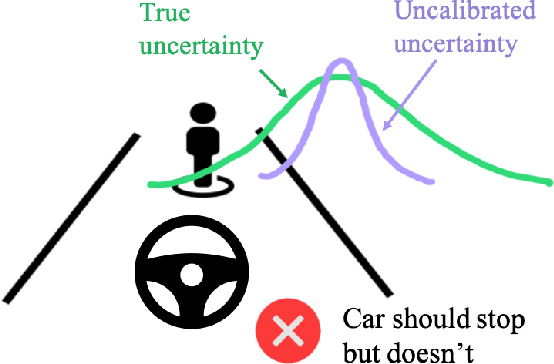
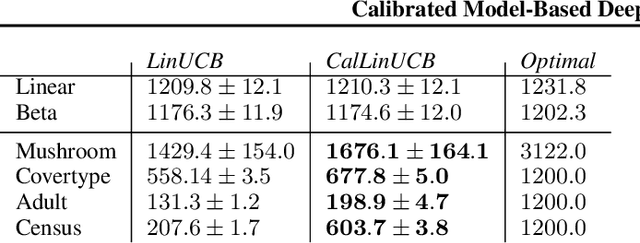
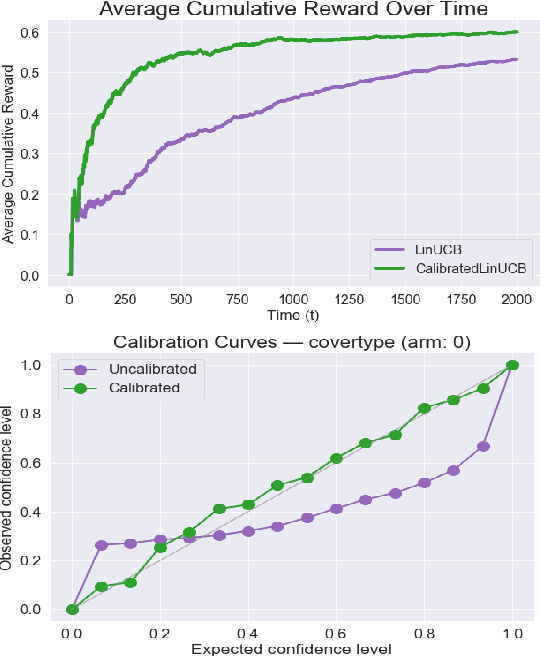
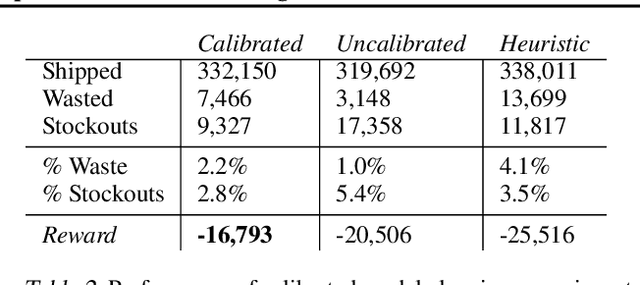
Estimates of predictive uncertainty are important for accurate model-based planning and reinforcement learning. However, predictive uncertainties---especially ones derived from modern deep learning systems---can be inaccurate and impose a bottleneck on performance. This paper explores which uncertainties are needed for model-based reinforcement learning and argues that good uncertainties must be calibrated, i.e. their probabilities should match empirical frequencies of predicted events. We describe a simple way to augment any model-based reinforcement learning agent with a calibrated model and show that doing so consistently improves planning, sample complexity, and exploration. On the \textsc{HalfCheetah} MuJoCo task, our system achieves state-of-the-art performance using 50\% fewer samples than the current leading approach. Our findings suggest that calibration can improve the performance of model-based reinforcement learning with minimal computational and implementation overhead.
Learning Controllable Fair Representations
Dec 11, 2018
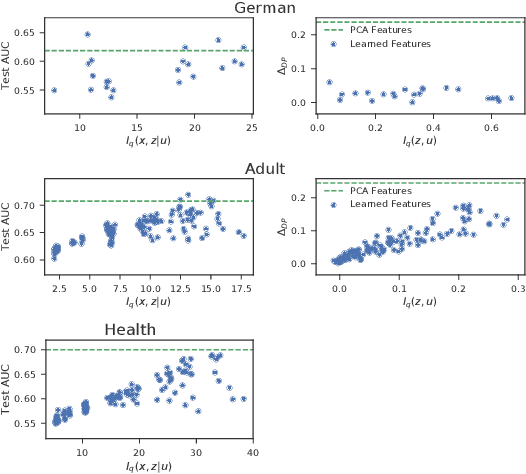
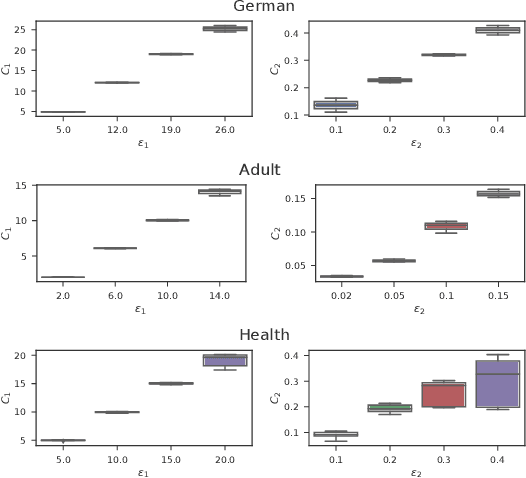
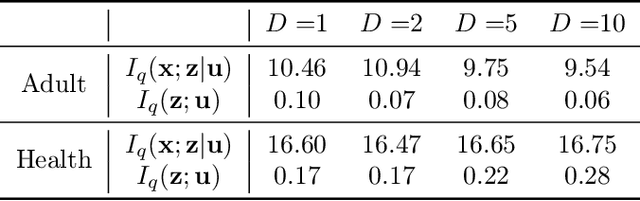
Learning data representations that are transferable and fair with respect to certain protected attributes is crucial to reducing unfair decisions made downstream, while preserving the utility of the data. We propose an information-theoretically motivated objective for learning maximally expressive representations subject to fairness constraints. We demonstrate that a range of existing approaches optimize approximations to the Lagrangian dual of our objective. In contrast to these existing approaches, our objective provides the user control over the fairness of representations by specifying limits on unfairness. We introduce a dual optimization method that optimizes the model as well as the expressiveness-fairness trade-off. Empirical evidence suggests that our proposed method can account for multiple notions of fairness and achieves higher expressiveness at a lower computational cost.
Bias and Generalization in Deep Generative Models: An Empirical Study
Nov 08, 2018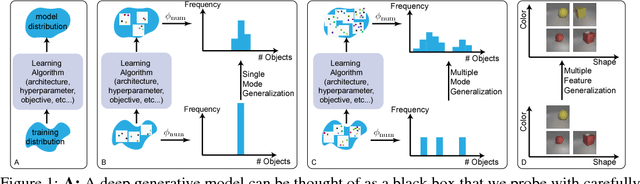

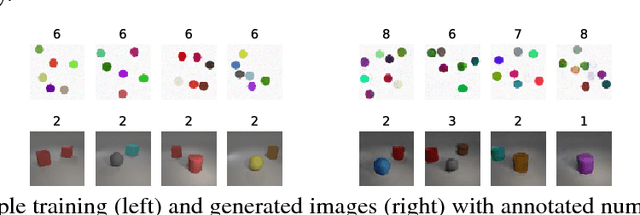
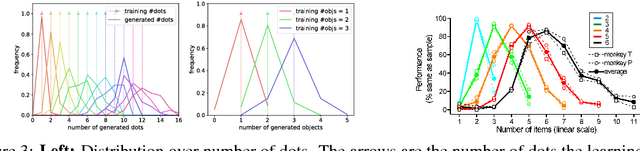
In high dimensional settings, density estimation algorithms rely crucially on their inductive bias. Despite recent empirical success, the inductive bias of deep generative models is not well understood. In this paper we propose a framework to systematically investigate bias and generalization in deep generative models of images. Inspired by experimental methods from cognitive psychology, we probe each learning algorithm with carefully designed training datasets to characterize when and how existing models generate novel attributes and their combinations. We identify similarities to human psychology and verify that these patterns are consistent across commonly used models and architectures.