 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONCAT: Consensus- and Confidence-Driven Ad Hoc Teaming for Efficient LLM-Based Multi-Agent Systems
May 28, 2026Although large language model (LLM) based multi-agent systems (MAS) show their capability to solve complex tasks and achieve higher performance over single agent systems, they lead to huge computational overheads because of heavy communication between agents. Previous research has made efforts to train a sparse multi-agent graph or fine-tune a planner to orchestrate the workflow better. However, such extra training processes introduce computational costs and limit MAS to specific domains, therefore compromising their generalizability. In this paper, we propose CONCAT, a training-free multi-agent collaboration framework based on CONsensus and Confidence-driven Ad hoc Teaming to efficiently organize agent interactions. Specifically, agents are clustered based on their initial answers, and leaders of each cluster are selected based on the agents' confidence. Then, a heuristic function based on the Theory of Mind is designed to predict the collaboration benefits between every two leaders according to their answers and confidence. Finally, an ad hoc multi-agent network is organized after evicting a percentage of communications based on the predicted benefits. Experiments across three LLMs and three benchmarks show that CONCAT achieves up to 2.02x higher efficiency (accuracy/latency ratio) than LLM-Debate and outperforms training-aware methods such as AgentDropout, while reducing average latency by 50.1% on Qwen2.5-14B-Instruct, without any task-specific training.
When KV Cache Reuse Fails in Multi-Agent Systems: Cross-Candidate Interaction is Crucial for LLM Judges
Jan 13, 2026Multi-agent LLM systems routinely generate multiple candidate responses that are aggregated by an LLM judge. To reduce the dominant prefill cost in such pipelines, recent work advocates KV cache reuse across partially shared contexts and reports substantial speedups for generation agents. In this work, we show that these efficiency gains do not transfer uniformly to judge-centric inference. Across GSM8K, MMLU, and HumanEval, we find that reuse strategies that are effective for execution agents can severely perturb judge behavior: end-task accuracy may appear stable, yet the judge's selection becomes highly inconsistent with dense prefill. We quantify this risk using Judge Consistency Rate (JCR) and provide diagnostics showing that reuse systematically weakens cross-candidate attention, especially for later candidate blocks. Our ablation further demonstrates that explicit cross-candidate interaction is crucial for preserving dense-prefill decisions. Overall, our results identify a previously overlooked failure mode of KV cache reuse and highlight judge-centric inference as a distinct regime that demands dedicated, risk-aware system design.
Affinity Space Adaptation for Semantic Segmentation Across Domains
Sep 26, 2020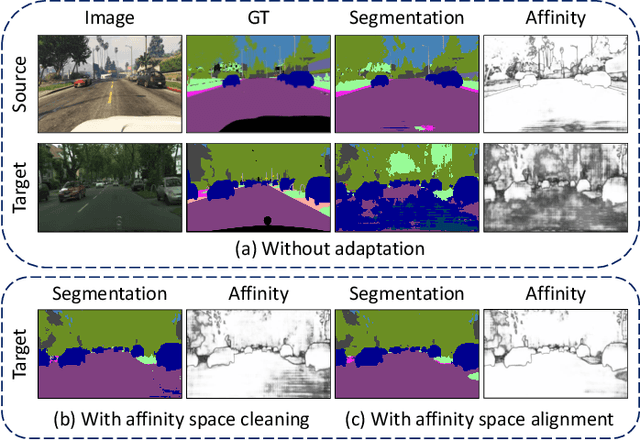
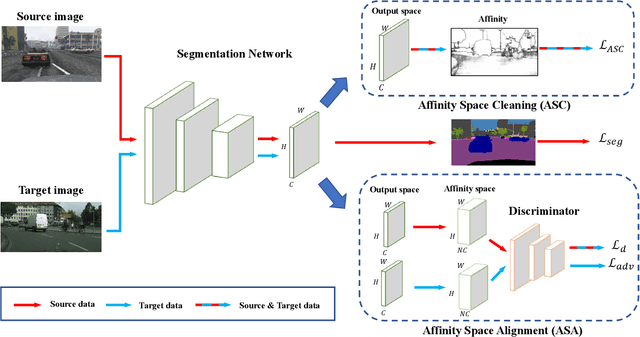

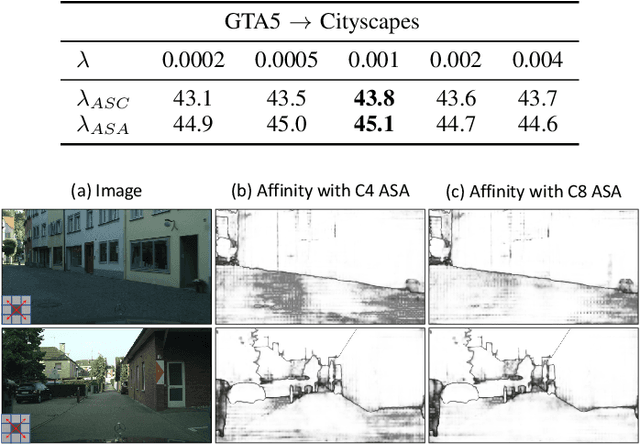
Semantic segmentation with dense pixel-wise annotation has achieved excellent performance thanks to deep learning. However, the generalization of semantic segmentation in the wild remains challenging. In this paper, we address the problem of unsupervised domain adaptation (UDA) in semantic segmentation. Motivated by the fact that source and target domain have invariant semantic structures, we propose to exploit such invariance across domains by leveraging co-occurring patterns between pairwise pixels in the output of structured semantic segmentation. This is different from most existing approaches that attempt to adapt domains based on individual pixel-wise information in image, feature, or output level. Specifically, we perform domain adaptation on the affinity relationship between adjacent pixels termed affinity space of source and target domain. To this end, we develop two affinity space adaptation strategies: affinity space cleaning and adversarial affinity space alignment. Extensive experiments demonstrate that the proposed method achieves superior performance against some state-of-the-art methods on several challenging benchmarks for semantic segmentation across domains. The code is available at https://github.com/idealwei/ASANet.