 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJesse Hoey
ALOHA: Artificial Learning of Human Attributes for Dialogue Agents
Nov 21, 2019
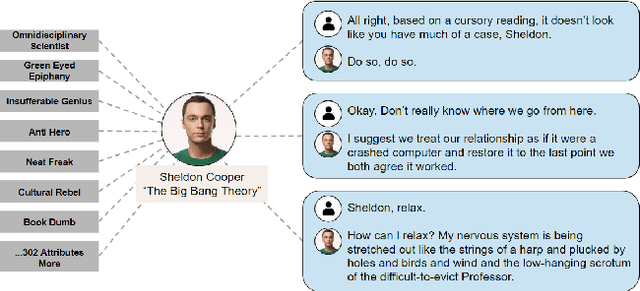

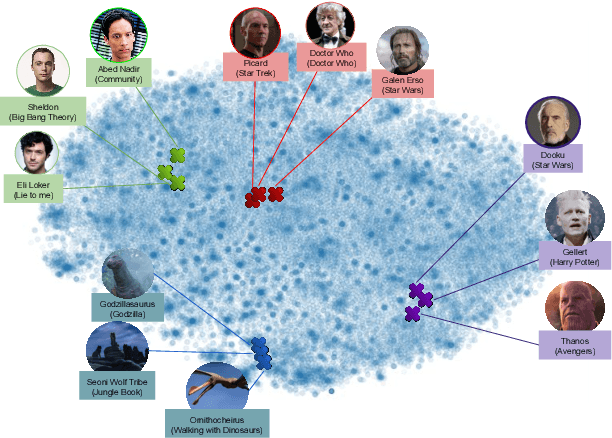
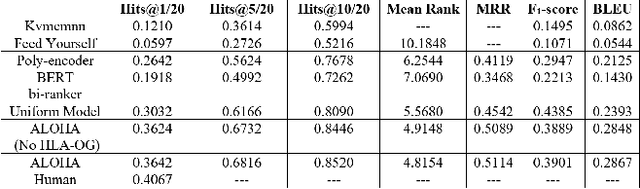
For conversational AI and virtual assistants to communicate with humans in a realistic way, they must exhibit human characteristics such as expression of emotion and personality. Current attempts toward constructing human-like dialogue agents have presented significant difficulties. We propose Human Level Attributes (HLAs) based on tropes as the basis of a method for learning dialogue agents that can imitate the personalities of fictional characters. Tropes are characteristics of fictional personalities that are observed recurrently and determined by viewers' impressions. By combining detailed HLA data with dialogue data for specific characters, we present a dataset, HLA-Chat, that models character profiles and gives dialogue agents the ability to learn characters' language styles through their HLAs. We then introduce a three-component system, ALOHA (which stands for Artificial Learning of Human Attributes), that combines character space mapping, character community detection, and language style retrieval to build a character (or personality) specific language model. Our preliminary experiments demonstrate that two variations of ALOHA, combined with our proposed dataset, can outperform baseline models at identifying the correct dialogue responses of chosen target characters, and are stable regardless of the character's identity, the genre of the show, and the context of the dialogue.
Follow Alice into the Rabbit Hole: Giving Dialogue Agents Understanding of Human Level Attributes
Oct 18, 2019For conversational AI and virtual assistants to communicate with humans in a realistic way, they must exhibit human characteristics such as expression of emotion and personality. Current attempts toward constructing human-like dialogue agents have presented significant difficulties. We propose Human Level Attributes (HLAs) based on tropes as the basis of a method for learning dialogue agents that can imitate the personalities of fictional characters. Tropes are characteristics of fictional personalities that are observed recurrently and determined by viewers' impressions. By combining detailed HLA data with dialogue data for specific characters, we present a dataset that models character profiles and gives dialogue agents the ability to learn characters' language styles through their HLAs. We then introduce a three-component system, ALOHA (which stands for Artificial Learning On Human Attributes), that combines character space mapping, character community detection, and language style retrieval to build a character (or personality) specific language model. Our preliminary experiments demonstrate that ALOHA, combined with our proposed dataset, can outperform baseline models at identifying correct dialogue responses of any chosen target character, and is stable regardless of the character's identity, genre of the show, and context of the dialogue.
"Conservatives Overfit, Liberals Underfit": The Social-Psychological Control of Affect and Uncertainty
Sep 01, 2019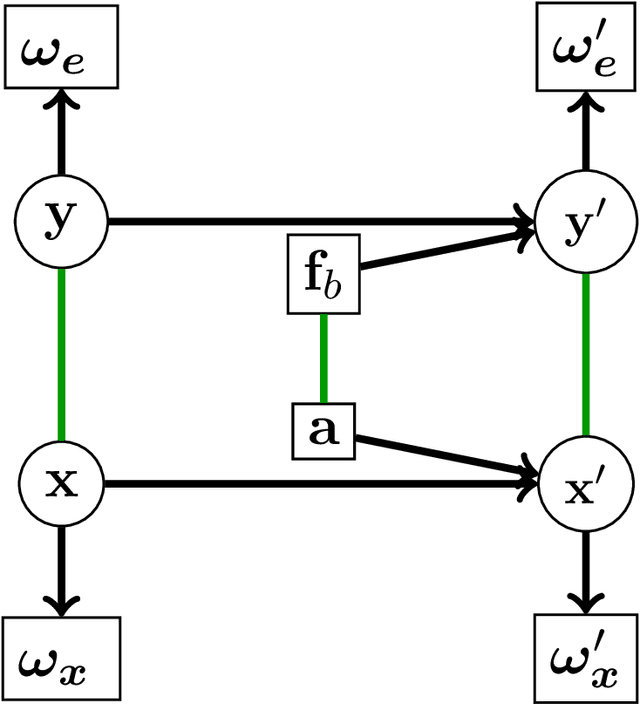
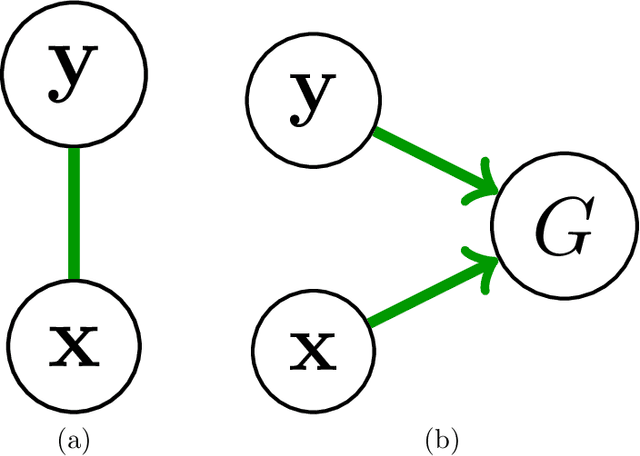
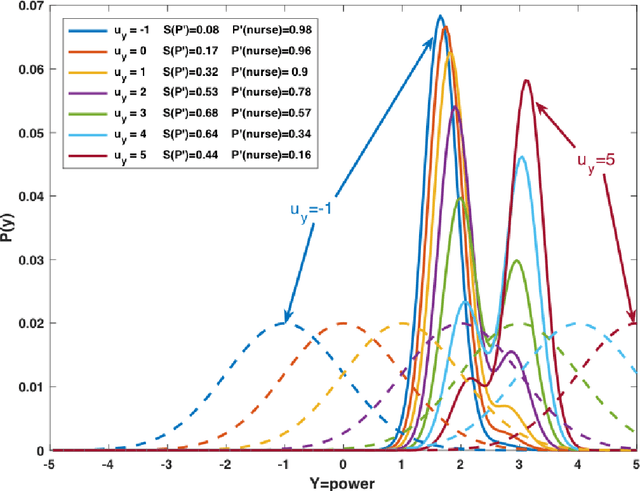
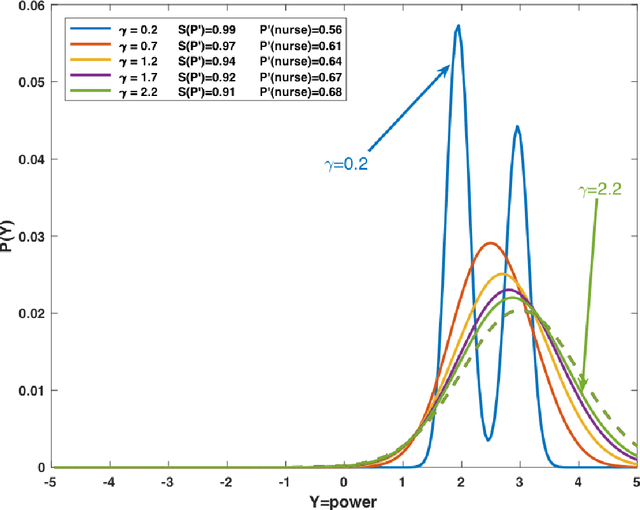
The presence of artificial agents in human social networks is growing. From chatbots to robots, human experience in the developed world is moving towards a socio-technical system in which agents can be technological or biological, with increasingly blurred distinctions between. Given that emotion is a key element of human interaction, enabling artificial agents with the ability to reason about affect is a key stepping stone towards a future in which technological agents and humans can work together. This paper presents work on building intelligent computational agents that integrate both emotion and cognition. These agents are grounded in the well-established social-psychological Bayesian Affect Control Theory (BayesAct). The core idea of BayesAct is that humans are motivated in their social interactions by affective alignment: they strive for their social experiences to be coherent at a deep, emotional level with their sense of identity and general world views as constructed through culturally shared symbols. This affective alignment creates cohesive bonds between group members, and is instrumental for collaborations to solidify as relational group commitments. BayesAct agents are motivated in their social interactions by a combination of affective alignment and decision theoretic reasoning, trading the two off as a function of the uncertainty or unpredictability of the situation. This paper provides a high-level view of dual process theories and advances BayesAct as a plausible, computationally tractable model based in social-psychological theory. We introduce a revised BayesAct model that more deeply integrates social-psychological theorising, and we demonstrate a component of the model as being sufficient to account for cognitive biases about fairness, dissonance and conformity. We show how the model can unify different exploration strategies in reinforcement learning.
Keep Calm and Switch On! Preserving Sentiment and Fluency in Semantic Text Exchange
Aug 30, 2019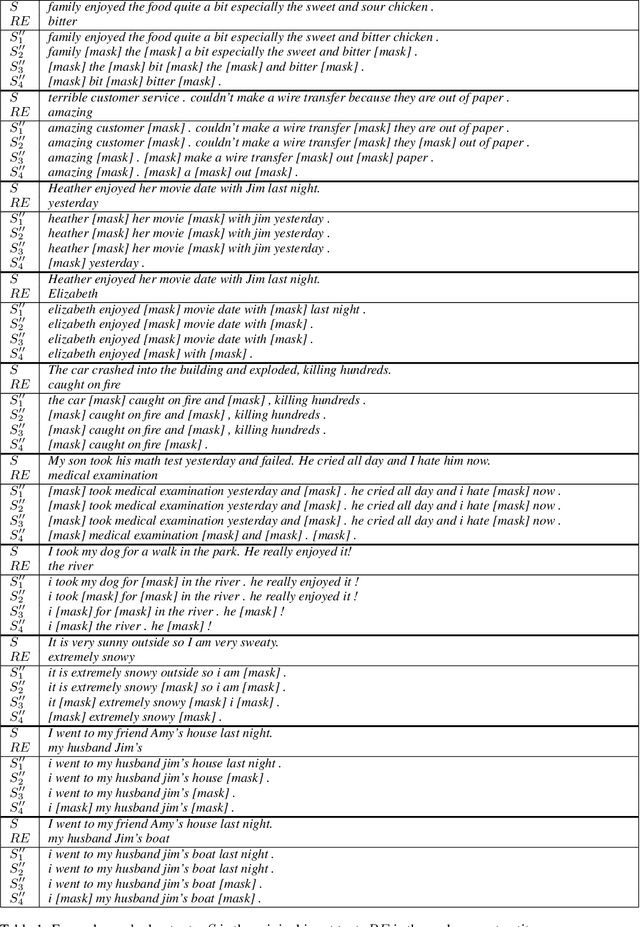
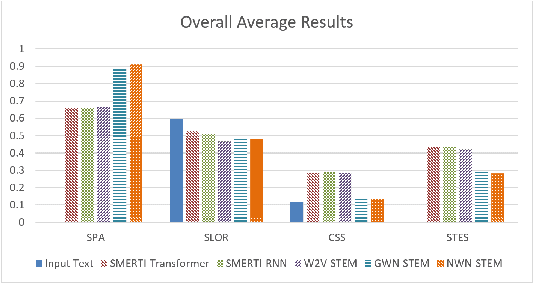
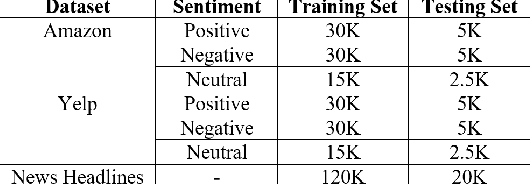
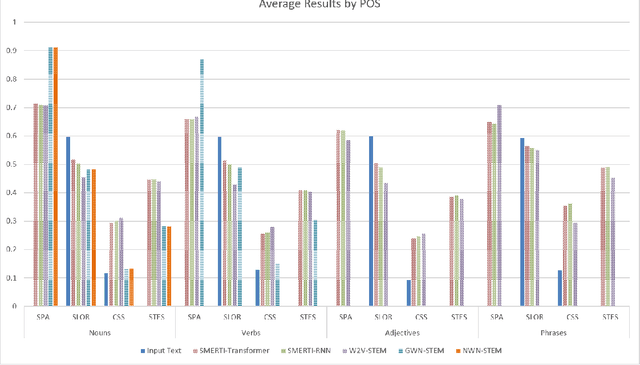
In this paper, we present a novel method for measurably adjusting the semantics of text while preserving its sentiment and fluency, a task we call semantic text exchange. This is useful for text data augmentation and the semantic correction of text generated by chatbots and virtual assistants. We introduce a pipeline called SMERTI that combines entity replacement, similarity masking, and text infilling. We measure our pipeline's success by its Semantic Text Exchange Score (STES): the ability to preserve the original text's sentiment and fluency while adjusting semantic content. We propose to use masking (replacement) rate threshold as an adjustable parameter to control the amount of semantic change in the text. Our experiments demonstrate that SMERTI can outperform baseline models on Yelp reviews, Amazon reviews, and news headlines.
Improving Humanness of Virtual Agents and Users' Cooperation through Emotions
Mar 10, 2019
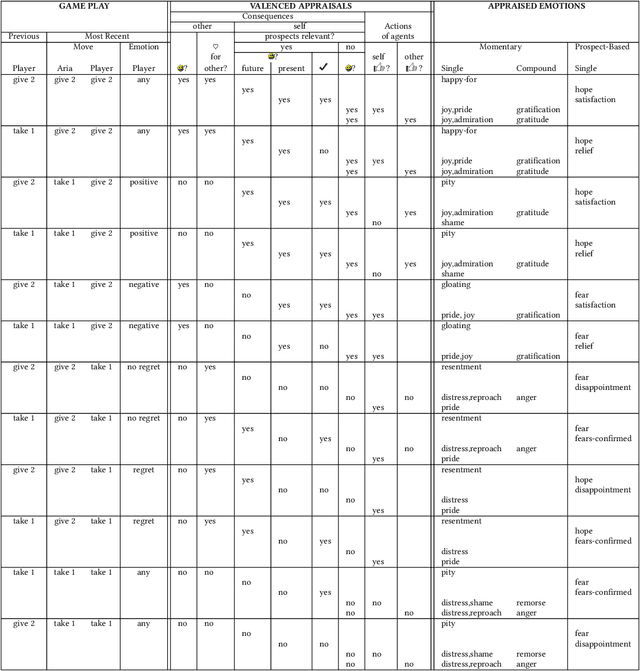

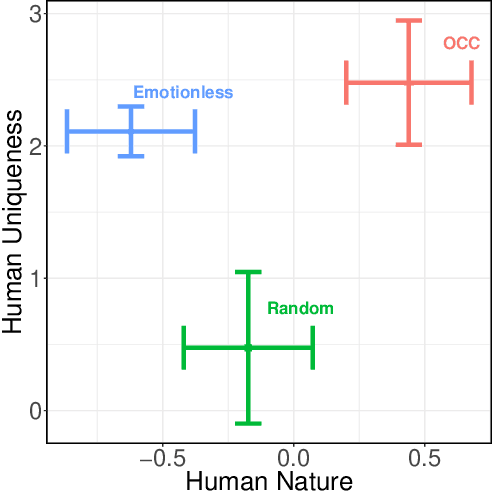
In this paper, we analyze the performance of an agent developed according to a well-accepted appraisal theory of human emotion with respect to how it modulates play in the context of a social dilemma. We ask if the agent will be capable of generating interactions that are considered to be more human than machine-like. We conduct an experiment with 117 participants and show how participants rate our agent on dimensions of human-uniqueness (which separates humans from animals) and human-nature (which separates humans from machines). We show that our appraisal theoretic agent is perceived to be more human-like than baseline models, by significantly improving both human-nature and human-uniqueness aspects of the intelligent agent. We also show that perception of humanness positively affects enjoyment and cooperation in the social dilemma.
Affective Neural Response Generation
Sep 12, 2017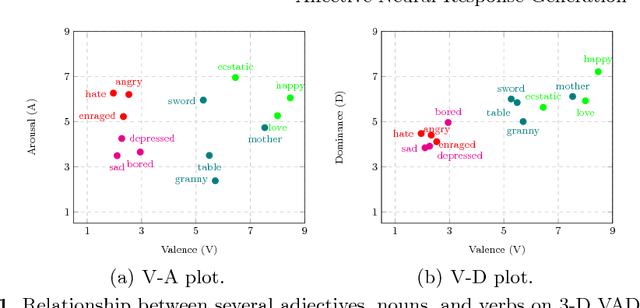
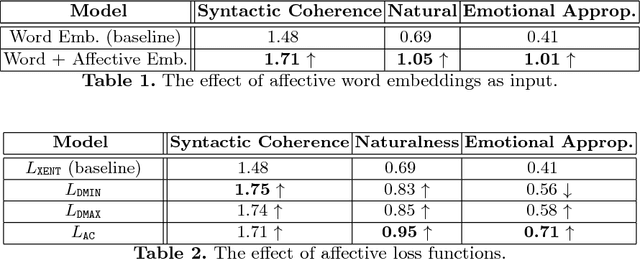
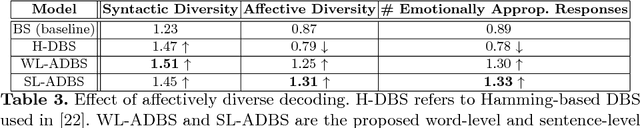
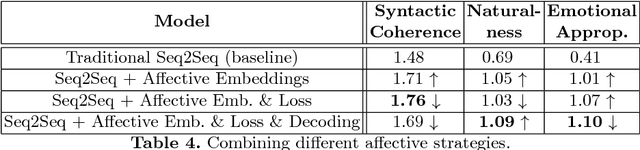
Existing neural conversational models process natural language primarily on a lexico-syntactic level, thereby ignoring one of the most crucial components of human-to-human dialogue: its affective content. We take a step in this direction by proposing three novel ways to incorporate affective/emotional aspects into long short term memory (LSTM) encoder-decoder neural conversation models: (1) affective word embeddings, which are cognitively engineered, (2) affect-based objective functions that augment the standard cross-entropy loss, and (3) affectively diverse beam search for decoding. Experiments show that these techniques improve the open-domain conversational prowess of encoder-decoder networks by enabling them to produce emotionally rich responses that are more interesting and natural.
Semi-Supervised Affective Meaning Lexicon Expansion Using Semantic and Distributed Word Representations
Mar 28, 2017
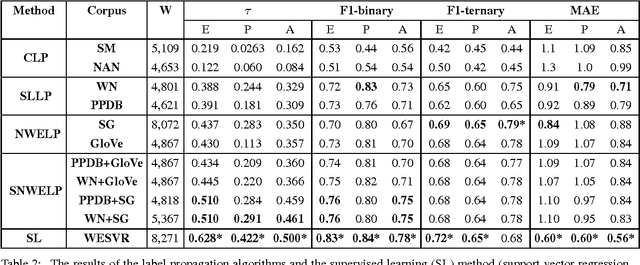
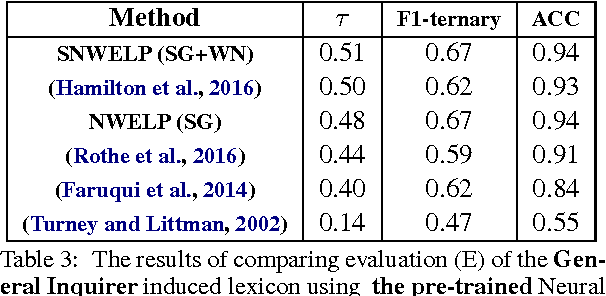
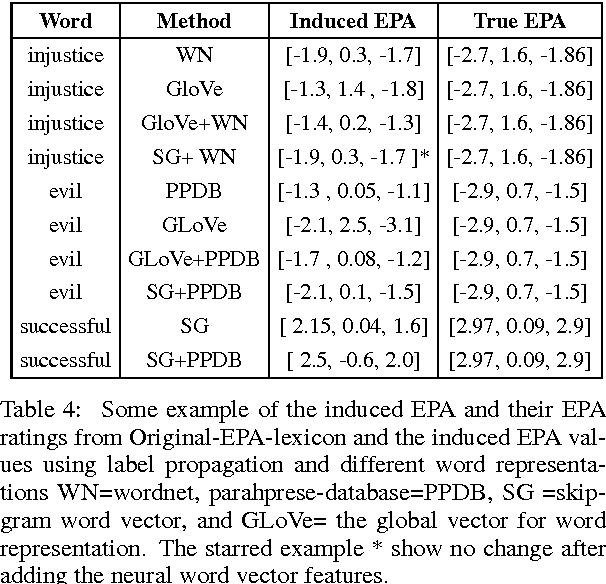
In this paper, we propose an extension to graph-based sentiment lexicon induction methods by incorporating distributed and semantic word representations in building the similarity graph to expand a three-dimensional sentiment lexicon. We also implemented and evaluated the label propagation using four different word representations and similarity metrics. Our comprehensive evaluation of the four approaches was performed on a single data set, demonstrating that all four methods can generate a significant number of new sentiment assignments with high accuracy. The highest correlations (tau=0.51) and the lowest error (mean absolute error < 1.1%), obtained by combining both the semantic and the distributional features, outperformed the distributional-based and semantic-based label-propagation models and approached a supervised algorithm.
Detecting Falls with X-Factor Hidden Markov Models
Jan 20, 2017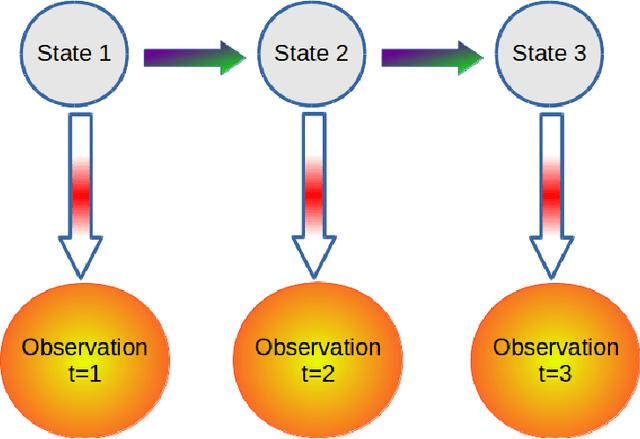
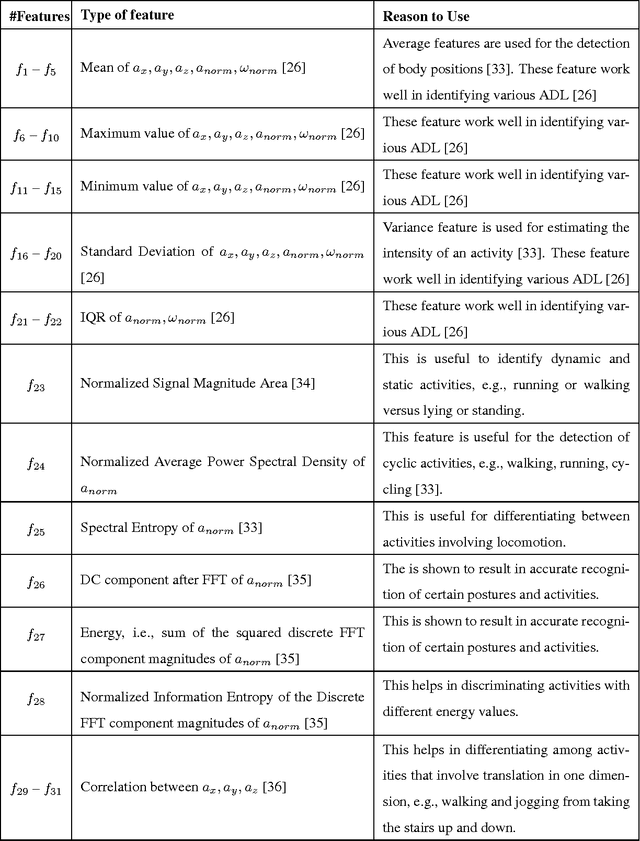
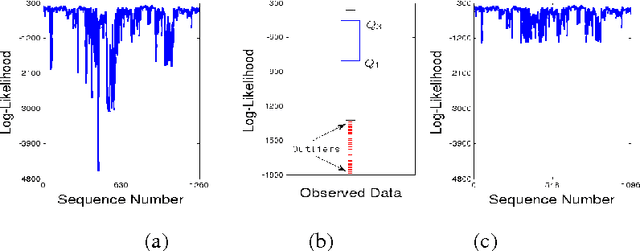
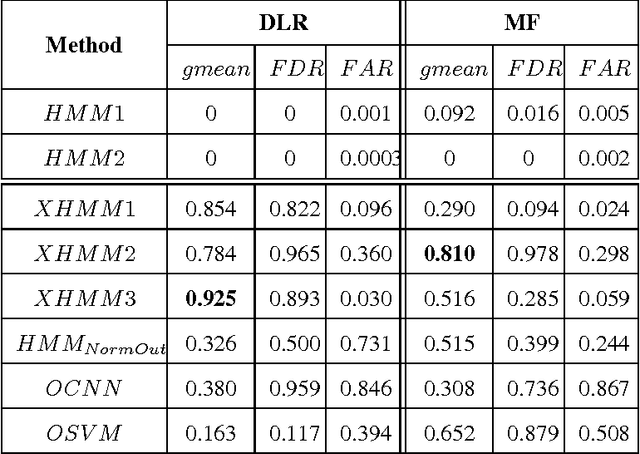
Identification of falls while performing normal activities of daily living (ADL) is important to ensure personal safety and well-being. However, falling is a short term activity that occurs infrequently. This poses a challenge to traditional classification algorithms, because there may be very little training data for falls (or none at all). This paper proposes an approach for the identification of falls using a wearable device in the absence of training data for falls but with plentiful data for normal ADL. We propose three `X-Factor' Hidden Markov Model (XHMMs) approaches. The XHMMs model unseen falls using "inflated" output covariances (observation models). To estimate the inflated covariances, we propose a novel cross validation method to remove "outliers" from the normal ADL that serve as proxies for the unseen falls and allow learning the XHMMs using only normal activities. We tested the proposed XHMM approaches on two activity recognition datasets and show high detection rates for falls in the absence of fall-specific training data. We show that the traditional method of choosing a threshold based on maximum of negative of log-likelihood to identify unseen falls is ill-posed for this problem. We also show that supervised classification methods perform poorly when very limited fall data are available during the training phase.
* 27 pages, 4 figures, 3 tables, Applied Soft Computing, 2017