 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePinPoint: Monocular Needle Pose Estimation for Robotic Suturing via Stein Variational Newton and Geometric Residuals
Mar 24, 2026Reliable estimation of surgical needle 3D position and orientation is essential for autonomous robotic suturing, yet existing methods operate almost exclusively under stereoscopic vision. In monocular endoscopic settings, common in transendoscopic and intraluminal procedures, depth ambiguity and rotational symmetry render needle pose estimation inherently ill-posed, producing a multimodal distribution over feasible configurations, rather than a single, well-grounded estimate. We present PinPoint, a probabilistic variational inference framework that treats this ambiguity directly, maintaining a distribution of pose hypotheses rather than suppressing it. PinPoint combines monocular image observations with robot-grasp constraints through analytical geometric likelihoods with closed-form Jacobians. This framework enables efficient Gauss-Newton preconditioning in a Stein Variational Newton inference, where second-order particle transport deterministically moves particles toward high-probability regions while kernel-based repulsion preserves diversity in the multimodal structure. On real needle-tracking sequences, PinPoint reduces mean translational error by 80% (down to 1.00 mm) and rotational error by 78% (down to 13.80°) relative to a particle-filter baseline, with substantially better-calibrated uncertainty. On induced-rotation sequences, where monocular ambiguity is most severe, PinPoint maintains a bimodal posterior 84% of the time, almost three times the rate of the particle filter baseline, correctly preserving the alternative hypothesis rather than committing prematurely to one mode. Suturing experiments in ex vivo tissue demonstrate stable tracking through intermittent occlusion, with average errors during occlusion of 1.34 mm in translation and 19.18° in rotation, even when the needle is fully embedded.
ProbeMDE: Uncertainty-Guided Active Proprioception for Monocular Depth Estimation in Surgical Robotics
Dec 17, 2025Monocular depth estimation (MDE) provides a useful tool for robotic perception, but its predictions are often uncertain and inaccurate in challenging environments such as surgical scenes where textureless surfaces, specular reflections, and occlusions are common. To address this, we propose ProbeMDE, a cost-aware active sensing framework that combines RGB images with sparse proprioceptive measurements for MDE. Our approach utilizes an ensemble of MDE models to predict dense depth maps conditioned on both RGB images and on a sparse set of known depth measurements obtained via proprioception, where the robot has touched the environment in a known configuration. We quantify predictive uncertainty via the ensemble's variance and measure the gradient of the uncertainty with respect to candidate measurement locations. To prevent mode collapse while selecting maximally informative locations to propriocept (touch), we leverage Stein Variational Gradient Descent (SVGD) over this gradient map. We validate our method in both simulated and physical experiments on central airway obstruction surgical phantoms. Our results demonstrate that our approach outperforms baseline methods across standard depth estimation metrics, achieving higher accuracy while minimizing the number of required proprioceptive measurements. Project page: https://brittonjordan.github.io/probe_mde/
A Supervised Autonomous Resection and Retraction Framework for Transurethral Enucleation of the Prostatic Median Lobe
Nov 11, 2025Concentric tube robots (CTRs) offer dexterous motion at millimeter scales, enabling minimally invasive procedures through natural orifices. This work presents a coordinated model-based resection planner and learning-based retraction network that work together to enable semi-autonomous tissue resection using a dual-arm transurethral concentric tube robot (the Virtuoso). The resection planner operates directly on segmented CT volumes of prostate phantoms, automatically generating tool trajectories for a three-phase median lobe resection workflow: left/median trough resection, right/median trough resection, and median blunt dissection. The retraction network, PushCVAE, trained on surgeon demonstrations, generates retractions according to the procedural phase. The procedure is executed under Level-3 (supervised) autonomy on a prostate phantom composed of hydrogel materials that replicate the mechanical and cutting properties of tissue. As a feasibility study, we demonstrate that our combined autonomous system achieves a 97.1% resection of the targeted volume of the median lobe. Our study establishes a foundation for image-guided autonomy in transurethral robotic surgery and represents a first step toward fully automated minimally-invasive prostate enucleation.
From Monocular Vision to Autonomous Action: Guiding Tumor Resection via 3D Reconstruction
Mar 20, 2025Surgical automation requires precise guidance and understanding of the scene. Current methods in the literature rely on bulky depth cameras to create maps of the anatomy, however this does not translate well to space-limited clinical applications. Monocular cameras are small and allow minimally invasive surgeries in tight spaces but additional processing is required to generate 3D scene understanding. We propose a 3D mapping pipeline that uses only RGB images to create segmented point clouds of the target anatomy. To ensure the most precise reconstruction, we compare different structure from motion algorithms' performance on mapping the central airway obstructions, and test the pipeline on a downstream task of tumor resection. In several metrics, including post-procedure tissue model evaluation, our pipeline performs comparably to RGB-D cameras and, in some cases, even surpasses their performance. These promising results demonstrate that automation guidance can be achieved in minimally invasive procedures with monocular cameras. This study is a step toward the complete autonomy of surgical robots.
Multi Jet Fusion of Nylon-12: A Viable Method to 3D-print Concentric Tube Robots?
Apr 01, 2022
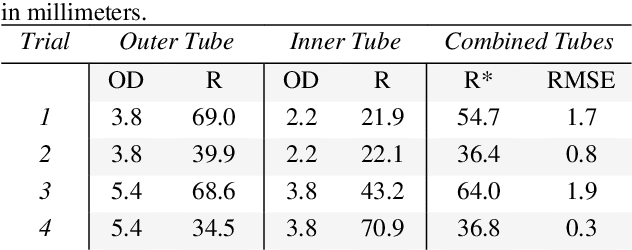

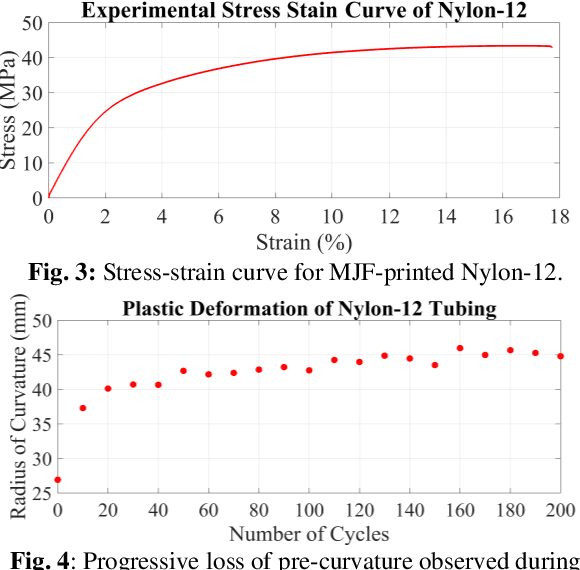
In this paper, we present a study on the viability of fabricating Concentric Tube Robots using Multi Jet Fusion (MJF) of Nylon-12, a type of elastic polymer commonly used in additive manufacturing. We note that Nylon-12 was already evaluated for the purpose of building CTRs in prior work, but fabrication was performed with Selective Laser Sintering (SLS), which produced unsatisfactory results. Our study is the first study to evaluate the suitability of MJF to 3Dprint CTRs.
* in press