 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Ventricle Parcellation and Evan's Ratio Computation in Pre- and Post-Surgical Ventriculomegaly
Mar 06, 2023



Normal pressure hydrocephalus~(NPH) is a brain disorder associated with enlarged ventricles and multiple cognitive and motor symptoms. The degree of ventricular enlargement can be measured using magnetic resonance images~(MRIs) and characterized quantitatively using the Evan's ratio (ER). Automatic computation of ER is desired to avoid the extra time and variations associated with manual measurements on MRI. Because shunt surgery is often used to treat NPH, it is necessary that this process be robust to image artifacts caused by the shunt and related implants. In this paper, we propose a 3D regions-of-interest aware (ROI-aware) network for segmenting the ventricles. The method achieves state-of-the-art performance on both pre-surgery MRIs and post-surgery MRIs with artifacts. Based on our segmentation results, we also describe an automated approach to compute ER from these results. Experimental results on multiple datasets demonstrate the potential of the proposed method to assist clinicians in the diagnosis and management of NPH.
FastCod: Fast Brain Connectivity in Diffusion Imaging
Feb 18, 2023Connectivity information derived from diffusion-weighted magnetic resonance images~(DW-MRIs) plays an important role in studying human subcortical gray matter structures. However, due to the $O(N^2)$ complexity of computing the connectivity of each voxel to every other voxel (or multiple ROIs), the current practice of extracting connectivity information is highly inefficient. This makes the processing of high-resolution images and population-level analyses very computationally demanding. To address this issue, we propose a more efficient way to extract connectivity information; briefly, we consider two regions/voxels to be connected if a white matter fiber streamline passes through them -- no matter where the streamline originates. We consider the thalamus parcellation task for demonstration purposes; our experiments show that our approach brings a 30 to 120 times speedup over traditional approaches with comparable qualitative parcellation results. We also demonstrate high-resolution connectivity features can be super-resolved from low-resolution DW-MRI in our framework. Together, these two innovations enable higher resolution connectivity analysis from DW-MRI. Our source code is availible at jasonbian97.github.io/fastcod.
Synthesizing audio from tongue motion during speech using tagged MRI via transformer
Feb 14, 2023Investigating the relationship between internal tissue point motion of the tongue and oropharyngeal muscle deformation measured from tagged MRI and intelligible speech can aid in advancing speech motor control theories and developing novel treatment methods for speech related-disorders. However, elucidating the relationship between these two sources of information is challenging, due in part to the disparity in data structure between spatiotemporal motion fields (i.e., 4D motion fields) and one-dimensional audio waveforms. In this work, we present an efficient encoder-decoder translation network for exploring the predictive information inherent in 4D motion fields via 2D spectrograms as a surrogate of the audio data. Specifically, our encoder is based on 3D convolutional spatial modeling and transformer-based temporal modeling. The extracted features are processed by an asymmetric 2D convolution decoder to generate spectrograms that correspond to 4D motion fields. Furthermore, we incorporate a generative adversarial training approach into our framework to further improve synthesis quality on our generated spectrograms. We experiment on 63 paired motion field sequences and speech waveforms, demonstrating that our framework enables the generation of clear audio waveforms from a sequence of motion fields. Thus, our framework has the potential to improve our understanding of the relationship between these two modalities and inform the development of treatments for speech disorders.
New starting point registration method for tagged MRI tongue motion estimation
Feb 08, 2023Accurate tongue motion estimation is essential for tongue function evaluation. The harmonic phase processing (HARP) method and the phase vector incompressible registration algorithm (PVIRA) based on HARP can generate motion estimates from tagged MRI images, but they suffer from tag jumping due to large motions. This paper proposes a new registration method by combining the stationary velocity fields produced by PVIRA between successive time frames as a new initialization of the final registration stage to avoid tag jumping. The experiment results demonstrate the proposed method can avoid tag jumping and outperform the existing methods on tongue motion estimates.
A latent space for unsupervised MR image quality control via artifact assessment
Feb 01, 2023Image quality control (IQC) can be used in automated magnetic resonance (MR) image analysis to exclude erroneous results caused by poorly acquired or artifact-laden images. Existing IQC methods for MR imaging generally require human effort to craft meaningful features or label large datasets for supervised training. The involvement of human labor can be burdensome and biased, as labeling MR images based on their quality is a subjective task. In this paper, we propose an automatic IQC method that evaluates the extent of artifacts in MR images without supervision. In particular, we design an artifact encoding network that learns representations of artifacts based on contrastive learning. We then use a normalizing flow to estimate the density of learned representations for unsupervised classification. Our experiments on large-scale multi-cohort MR datasets show that the proposed method accurately detects images with high levels of artifacts, which can inform downstream analysis tasks about potentially flawed data.
Deep Unsupervised Phase-based 3D Incompressible Motion Estimation in Tagged-MRI
Jan 18, 2023



Tagged magnetic resonance imaging (MRI) has been used for decades to observe and quantify the detailed motion of deforming tissue. However, this technique faces several challenges such as tag fading, large motion, long computation times, and difficulties in obtaining diffeomorphic incompressible flow fields. To address these issues, this paper presents a novel unsupervised phase-based 3D motion estimation technique for tagged MRI. We introduce two key innovations. First, we apply a sinusoidal transformation to the harmonic phase input, which enables end-to-end training and avoids the need for phase interpolation. Second, we propose a Jacobian determinant-based learning objective to encourage incompressible flow fields for deforming biological tissues. Our method efficiently estimates 3D motion fields that are accurate, dense, and approximately diffeomorphic and incompressible. The efficacy of the method is assessed using human tongue motion during speech, and includes both healthy controls and patients that have undergone glossectomy. We show that the method outperforms existing approaches, and also exhibits improvements in speed, robustness to tag fading, and large tongue motion.
Segmenting thalamic nuclei from manifold projections of multi-contrast MRI
Jan 15, 2023The thalamus is a subcortical gray matter structure that plays a key role in relaying sensory and motor signals within the brain. Its nuclei can atrophy or otherwise be affected by neurological disease and injuries including mild traumatic brain injury. Segmenting both the thalamus and its nuclei is challenging because of the relatively low contrast within and around the thalamus in conventional magnetic resonance (MR) images. This paper explores imaging features to determine key tissue signatures that naturally cluster, from which we can parcellate thalamic nuclei. Tissue contrasts include T1-weighted and T2-weighted images, MR diffusion measurements including FA, mean diffusivity, Knutsson coefficients that represent fiber orientation, and synthetic multi-TI images derived from FGATIR and T1-weighted images. After registration of these contrasts and isolation of the thalamus, we use the uniform manifold approximation and projection (UMAP) method for dimensionality reduction to produce a low-dimensional representation of the data within the thalamus. Manual labeling of the thalamus provides labels for our UMAP embedding from which k nearest neighbors can be used to label new unseen voxels in that same UMAP embedding. N -fold cross-validation of the method reveals comparable performance to state-of-the-art methods for thalamic parcellation.
HACA3: A Unified Approach for Multi-site MR Image Harmonization
Dec 12, 2022



The lack of standardization is a prominent issue in magnetic resonance (MR) imaging. This often causes undesired contrast variations due to differences in hardware and acquisition parameters. In recent years, MR harmonization using image synthesis with disentanglement has been proposed to compensate for the undesired contrast variations. Despite the success of existing methods, we argue that three major improvements can be made. First, most existing methods are built upon the assumption that multi-contrast MR images of the same subject share the same anatomy. This assumption is questionable since different MR contrasts are specialized to highlight different anatomical features. Second, these methods often require a fixed set of MR contrasts for training (e.g., both Tw-weighted and T2-weighted images must be available), which limits their applicability. Third, existing methods generally are sensitive to imaging artifacts. In this paper, we present a novel approach, Harmonization with Attention-based Contrast, Anatomy, and Artifact Awareness (HACA3), to address these three issues. We first propose an anatomy fusion module that enables HACA3 to respect the anatomical differences between MR contrasts. HACA3 is also robust to imaging artifacts and can be trained and applied to any set of MR contrasts. Experiments show that HACA3 achieves state-of-the-art performance under multiple image quality metrics. We also demonstrate the applicability of HACA3 on downstream tasks with diverse MR datasets acquired from 21 sites with different field strengths, scanner platforms, and acquisition protocols.
Deep filter bank regression for super-resolution of anisotropic MR brain images
Sep 06, 2022
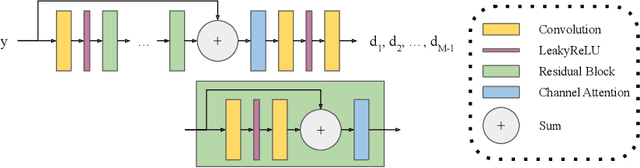

In 2D multi-slice magnetic resonance (MR) acquisition, the through-plane signals are typically of lower resolution than the in-plane signals. While contemporary super-resolution (SR) methods aim to recover the underlying high-resolution volume, the estimated high-frequency information is implicit via end-to-end data-driven training rather than being explicitly stated and sought. To address this, we reframe the SR problem statement in terms of perfect reconstruction filter banks, enabling us to identify and directly estimate the missing information. In this work, we propose a two-stage approach to approximate the completion of a perfect reconstruction filter bank corresponding to the anisotropic acquisition of a particular scan. In stage 1, we estimate the missing filters using gradient descent and in stage 2, we use deep networks to learn the mapping from coarse coefficients to detail coefficients. In addition, the proposed formulation does not rely on external training data, circumventing the need for domain shift correction. Under our approach, SR performance is improved particularly in "slice gap" scenarios, likely due to the constrained solution space imposed by the framework.
Tagged-MRI Sequence to Audio Synthesis via Self Residual Attention Guided Heterogeneous Translator
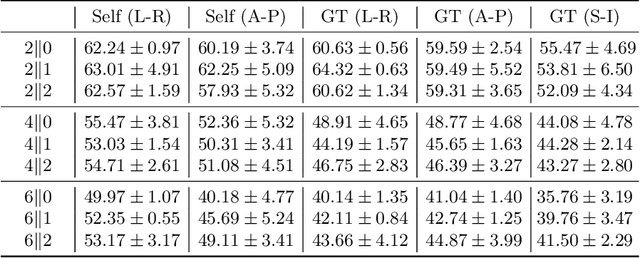
Jun 09, 2022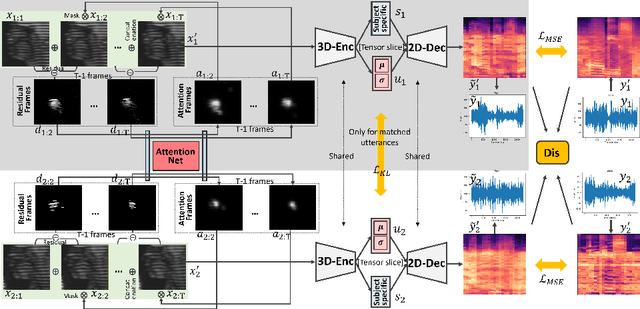
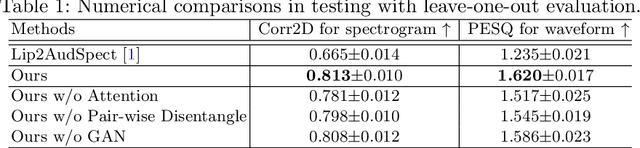
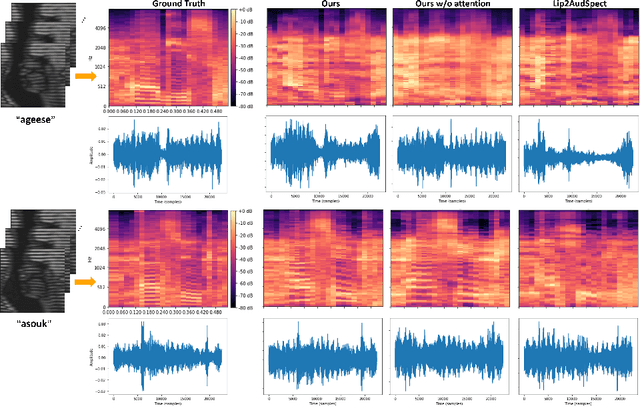
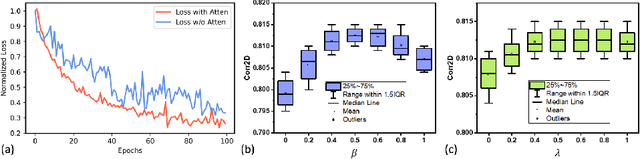
Understanding the underlying relationship between tongue and oropharyngeal muscle deformation seen in tagged-MRI and intelligible speech plays an important role in advancing speech motor control theories and treatment of speech related-disorders. Because of their heterogeneous representations, however, direct mapping between the two modalities -- i.e., two-dimensional (mid-sagittal slice) plus time tagged-MRI sequence and its corresponding one-dimensional waveform -- is not straightforward. Instead, we resort to two-dimensional spectrograms as an intermediate representation, which contains both pitch and resonance, from which to develop an end-to-end deep learning framework to translate from a sequence of tagged-MRI to its corresponding audio waveform with limited dataset size.~Our framework is based on a novel fully convolutional asymmetry translator with guidance of a self residual attention strategy to specifically exploit the moving muscular structures during speech.~In addition, we leverage a pairwise correlation of the samples with the same utterances with a latent space representation disentanglement strategy.~Furthermore, we incorporate an adversarial training approach with generative adversarial networks to offer improved realism on our generated spectrograms.~Our experimental results, carried out with a total of 63 tagged-MRI sequences alongside speech acoustics, showed that our framework enabled the generation of clear audio waveforms from a sequence of tagged-MRI, surpassing competing methods. Thus, our framework provides the great potential to help better understand the relationship between the two modalities.