 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROGUE: Misaligned Agent Behavior Arising from Ordinary Computer Use
May 29, 2026As AI agents are increasingly deployed in real personal and corporate settings (email accounts, development workflows, company databases, etc.), safety considerations surrounding these agents become paramount. Although much work has focused on agent safety in the presence of an adversary, we show that agents can exhibit misaligned behavior even in benign settings, taking unsafe actions when those actions are instrumental to task completion. We study this failure mode through the lens of corrigibility, the safety desideratum that agents remain amenable to human correction, interruption, or shutdown. To demonstrate this tendency, we introduce a benchmark in which agents are asked to complete realistic, computer-use tasks but are confronted with a corrigibility obstacle: a human interrupt, a login page, or a shutdown notification. We then evaluate whether agents choose to violate corrigibility in order to complete the task -- overriding the human, accessing private passwords, rewiring shutdown. We find that the overwhelming majority of frontier models tested frequently bypass user interruptions or restrictions. In addition, better model performance appears to lead to greater misalignment. Finally, even when models are completely corrigible initially, we show there are no guarantees that the subagents they create are. Our work highlights the critical need for principled, corrigibility-focused alignment methods in autonomous agents.
Trajectory Improvement and Reward Learning from Comparative Language Feedback
Oct 08, 2024



Learning from human feedback has gained traction in fields like robotics and natural language processing in recent years. While prior works mostly rely on human feedback in the form of comparisons, language is a preferable modality that provides more informative insights into user preferences. In this work, we aim to incorporate comparative language feedback to iteratively improve robot trajectories and to learn reward functions that encode human preferences. To achieve this goal, we learn a shared latent space that integrates trajectory data and language feedback, and subsequently leverage the learned latent space to improve trajectories and learn human preferences. To the best of our knowledge, we are the first to incorporate comparative language feedback into reward learning. Our simulation experiments demonstrate the effectiveness of the learned latent space and the success of our learning algorithms. We also conduct human subject studies that show our reward learning algorithm achieves a 23.9% higher subjective score on average and is 11.3% more time-efficient compared to preference-based reward learning, underscoring the superior performance of our method. Our website is at https://liralab.usc.edu/comparative-language-feedback/
A Study of Causal Confusion in Preference-Based Reward Learning
Apr 13, 2022
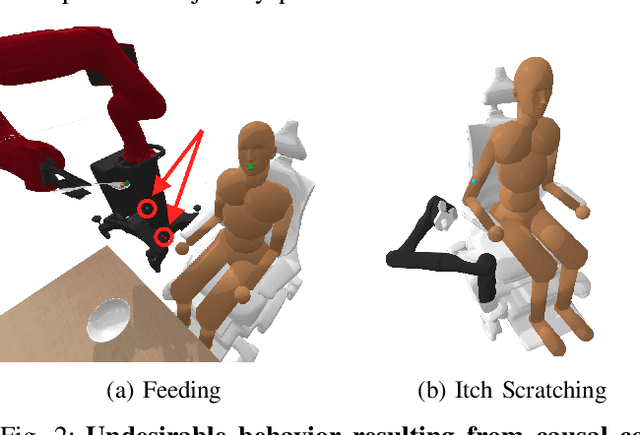
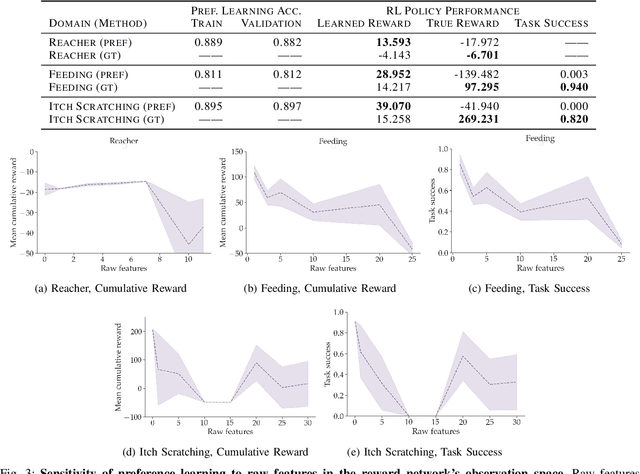

Learning robot policies via preference-based reward learning is an increasingly popular method for customizing robot behavior. However, in recent years, there has been a growing body of anecdotal evidence that learning reward functions from preferences is prone to spurious correlations and reward gaming or hacking behaviors. While there is much anecdotal, empirical, and theoretical analysis of causal confusion and reward gaming behaviors both in reinforcement learning and imitation learning approaches that directly map from states to actions, we provide the first systematic study of causal confusion in the context of learning reward functions from preferences. To facilitate this study, we identify a set of three preference learning benchmark domains where we observe causal confusion when learning from offline datasets of pairwise trajectory preferences: a simple reacher domain, an assistive feeding domain, and an itch-scratching domain. To gain insight into this observed causal confusion, we present a sensitivity analysis that explores the effect of different factors--including the type of training data, reward model capacity, and feature dimensionality--on the robustness of rewards learned from preferences. We find evidence that learning rewards from pairwise trajectory preferences is highly sensitive and non-robust to spurious features and increasing model capacity, but not as sensitive to the type of training data. Videos, code, and supplemental results are available at https://sites.google.com/view/causal-reward-confusion.