 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Fact Retrieval from Knowledge Graphs without Entity Linking
May 21, 2023



There has been a surge of interest in utilizing Knowledge Graphs (KGs) for various natural language processing/understanding tasks. The conventional mechanism to retrieve facts in KGs usually involves three steps: entity span detection, entity disambiguation, and relation classification. However, this approach requires additional labels for training each of the three subcomponents in addition to pairs of input texts and facts, and also may accumulate errors propagated from failures in previous steps. To tackle these limitations, we propose a simple knowledge retrieval framework, which directly retrieves facts from the KGs given the input text based on their representational similarities, which we refer to as Direct Fact Retrieval (DiFaR). Specifically, we first embed all facts in KGs onto a dense embedding space by using a language model trained by only pairs of input texts and facts, and then provide the nearest facts in response to the input text. Since the fact, consisting of only two entities and one relation, has little context to encode, we propose to further refine ranks of top-k retrieved facts with a reranker that contextualizes the input text and the fact jointly. We validate our DiFaR framework on multiple fact retrieval tasks, showing that it significantly outperforms relevant baselines that use the three-step approach.
Retention Is All You Need
Apr 06, 2023



Skilled employees are usually seen as the most important pillar of an organization. Despite this, most organizations face high attrition and turnover rates. While several machine learning models have been developed for analyzing attrition and its causal factors, the interpretations of those models remain opaque. In this paper, we propose the HR-DSS approach, which stands for Human Resource Decision Support System, and uses explainable AI for employee attrition problems. The system is designed to assist human resource departments in interpreting the predictions provided by machine learning models. In our experiments, eight machine learning models are employed to provide predictions, and the results achieved by the best-performing model are further processed by the SHAP explainability process. We optimize both the correctness and explanation of the results. Furthermore, using "What-if-analysis", we aim to observe plausible causes for attrition of an individual employee. The results show that by adjusting the specific dominant features of each individual, employee attrition can turn into employee retention through informative business decisions. Reducing attrition is not only a problem for any specific organization but also, in some countries, becomes a significant societal problem that impacts the well-being of both employers and employees.
Contrastive Representation Learning for Conversational Question Answering over Knowledge Graphs
Oct 09, 2022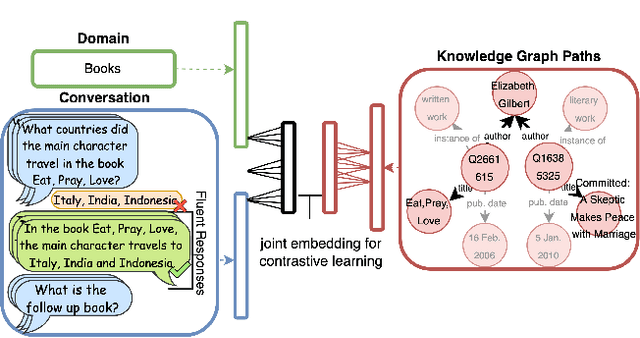
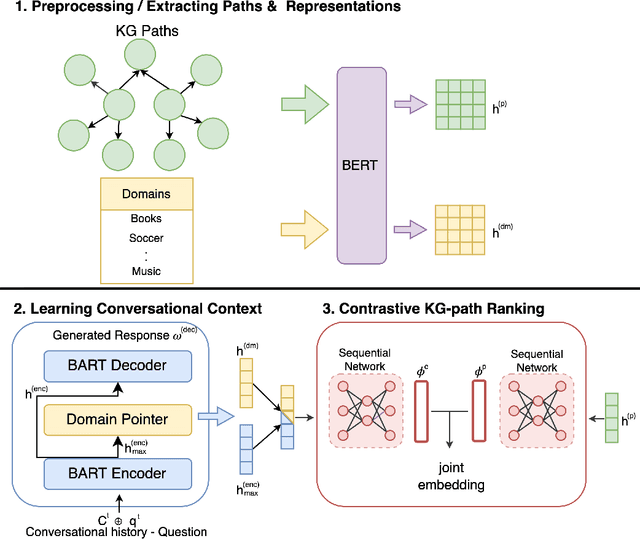
This paper addresses the task of conversational question answering (ConvQA) over knowledge graphs (KGs). The majority of existing ConvQA methods rely on full supervision signals with a strict assumption of the availability of gold logical forms of queries to extract answers from the KG. However, creating such a gold logical form is not viable for each potential question in a real-world scenario. Hence, in the case of missing gold logical forms, the existing information retrieval-based approaches use weak supervision via heuristics or reinforcement learning, formulating ConvQA as a KG path ranking problem. Despite missing gold logical forms, an abundance of conversational contexts, such as entire dialog history with fluent responses and domain information, can be incorporated to effectively reach the correct KG path. This work proposes a contrastive representation learning-based approach to rank KG paths effectively. Our approach solves two key challenges. Firstly, it allows weak supervision-based learning that omits the necessity of gold annotations. Second, it incorporates the conversational context (entire dialog history and domain information) to jointly learn its homogeneous representation with KG paths to improve contrastive representations for effective path ranking. We evaluate our approach on standard datasets for ConvQA, on which it significantly outperforms existing baselines on all domains and overall. Specifically, in some cases, the Mean Reciprocal Rank (MRR) and Hit@5 ranking metrics improve by absolute 10 and 18 points, respectively, compared to the state-of-the-art performance.
An Answer Verbalization Dataset for Conversational Question Answerings over Knowledge Graphs
Aug 13, 2022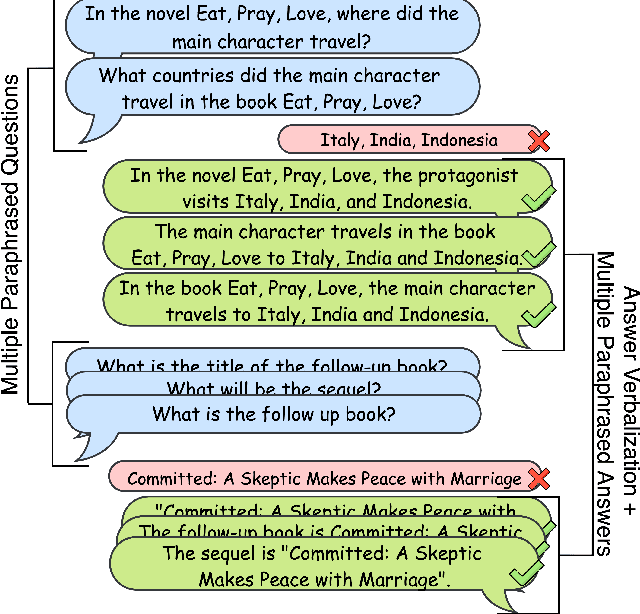

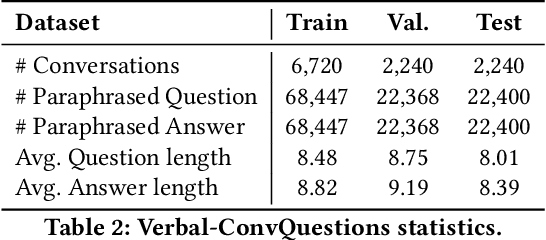
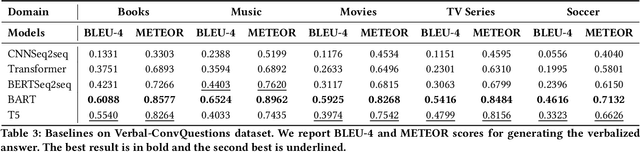
We introduce a new dataset for conversational question answering over Knowledge Graphs (KGs) with verbalized answers. Question answering over KGs is currently focused on answer generation for single-turn questions (KGQA) or multiple-tun conversational question answering (ConvQA). However, in a real-world scenario (e.g., voice assistants such as Siri, Alexa, and Google Assistant), users prefer verbalized answers. This paper contributes to the state-of-the-art by extending an existing ConvQA dataset with multiple paraphrased verbalized answers. We perform experiments with five sequence-to-sequence models on generating answer responses while maintaining grammatical correctness. We additionally perform an error analysis that details the rates of models' mispredictions in specified categories. Our proposed dataset extended with answer verbalization is publicly available with detailed documentation on its usage for wider utility.
Integrating Knowledge Graph embedding and pretrained Language Models in Hypercomplex Spaces
Aug 05, 2022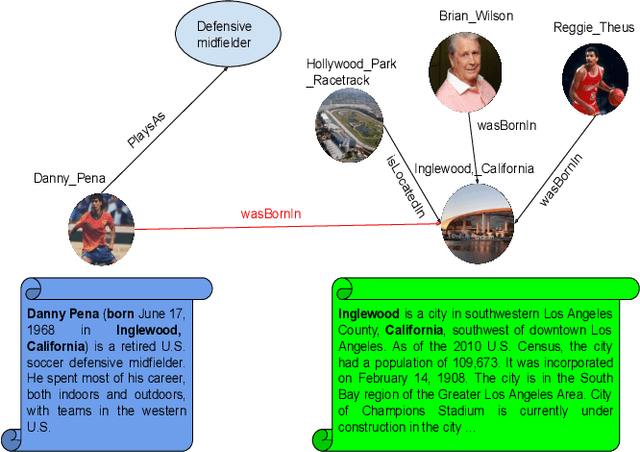

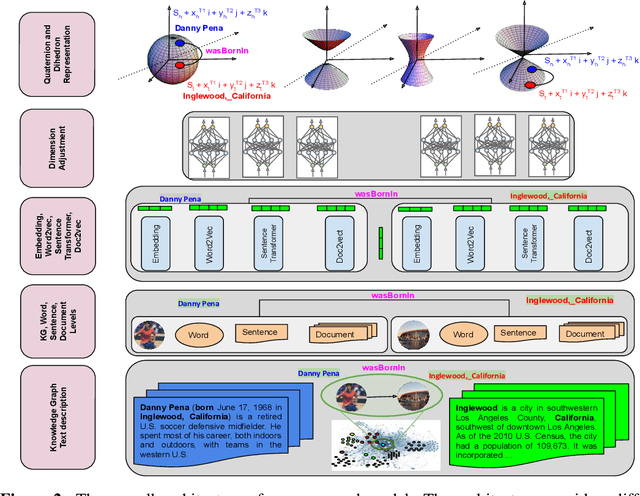
Knowledge Graphs, such as Wikidata, comprise structural and textual knowledge in order to represent knowledge. For each of the two modalities dedicated approaches for graph embedding and language models learn patterns that allow for predicting novel structural knowledge. Few approaches have integrated learning and inference with both modalities and these existing ones could only partially exploit the interaction of structural and textual knowledge. In our approach, we build on existing strong representations of single modalities and we use hypercomplex algebra to represent both, (i), single-modality embedding as well as, (ii), the interaction between different modalities and their complementary means of knowledge representation. More specifically, we suggest Dihedron and Quaternion representations of 4D hypercomplex numbers to integrate four modalities namely structural knowledge graph embedding, word-level representations (e.g.\ Word2vec, Fasttext), sentence-level representations (Sentence transformer), and document-level representations (sentence transformer, Doc2vec). Our unified vector representation scores the plausibility of labelled edges via Hamilton and Dihedron products, thus modeling pairwise interactions between different modalities. Extensive experimental evaluation on standard benchmark datasets shows the superiority of our two new models using abundant textual information besides sparse structural knowledge to enhance performance in link prediction tasks.
DialoKG: Knowledge-Structure Aware Task-Oriented Dialogue Generation
Apr 19, 2022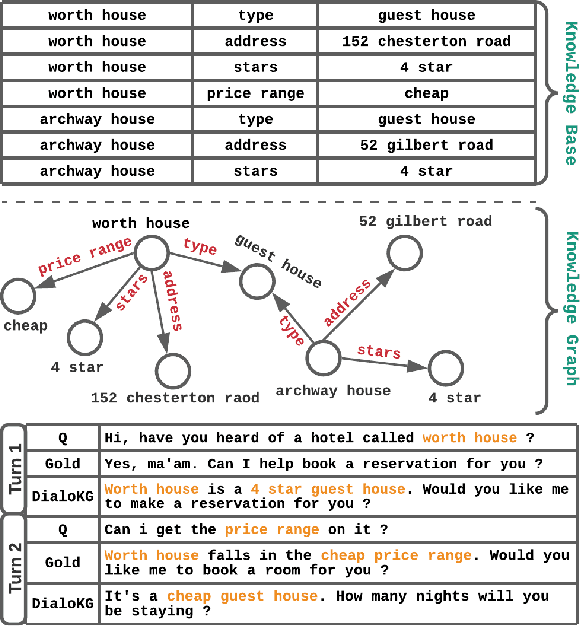

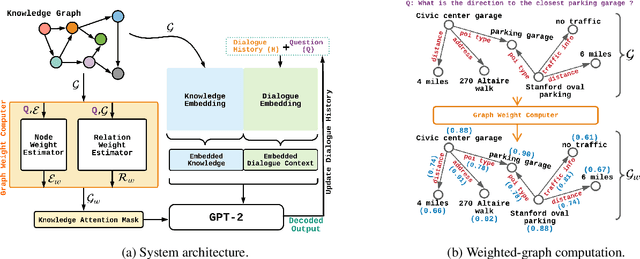
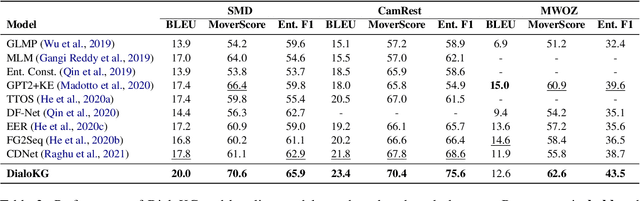
Task-oriented dialogue generation is challenging since the underlying knowledge is often dynamic and effectively incorporating knowledge into the learning process is hard. It is particularly challenging to generate both human-like and informative responses in this setting. Recent research primarily focused on various knowledge distillation methods where the underlying relationship between the facts in a knowledge base is not effectively captured. In this paper, we go one step further and demonstrate how the structural information of a knowledge graph can improve the system's inference capabilities. Specifically, we propose DialoKG, a novel task-oriented dialogue system that effectively incorporates knowledge into a language model. Our proposed system views relational knowledge as a knowledge graph and introduces (1) a structure-aware knowledge embedding technique, and (2) a knowledge graph-weighted attention masking strategy to facilitate the system selecting relevant information during the dialogue generation. An empirical evaluation demonstrates the effectiveness of DialoKG over state-of-the-art methods on several standard benchmark datasets.
RoMe: A Robust Metric for Evaluating Natural Language Generation
Mar 17, 2022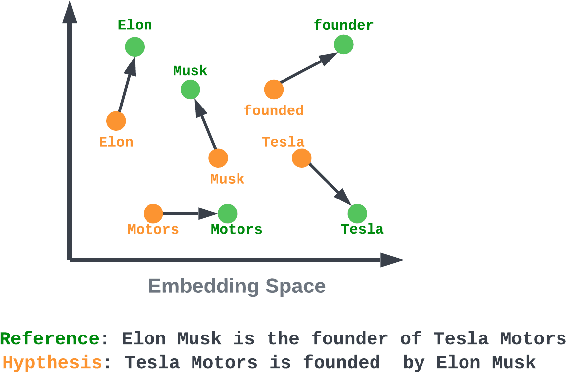
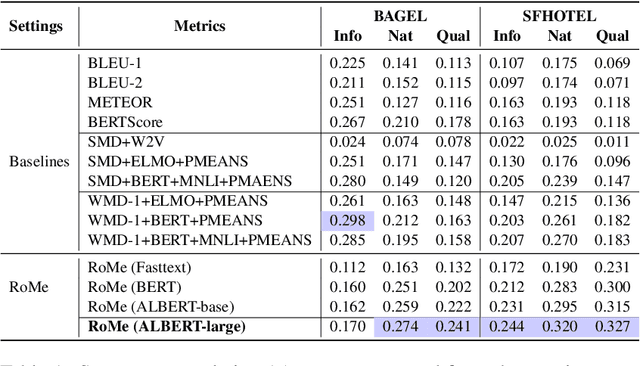
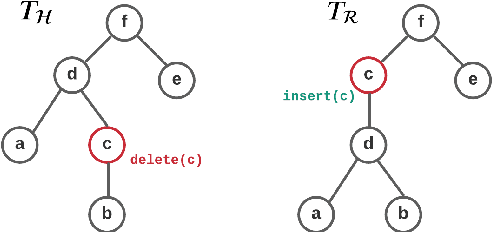

Evaluating Natural Language Generation (NLG) systems is a challenging task. Firstly, the metric should ensure that the generated hypothesis reflects the reference's semantics. Secondly, it should consider the grammatical quality of the generated sentence. Thirdly, it should be robust enough to handle various surface forms of the generated sentence. Thus, an effective evaluation metric has to be multifaceted. In this paper, we propose an automatic evaluation metric incorporating several core aspects of natural language understanding (language competence, syntactic and semantic variation). Our proposed metric, RoMe, is trained on language features such as semantic similarity combined with tree edit distance and grammatical acceptability, using a self-supervised neural network to assess the overall quality of the generated sentence. Moreover, we perform an extensive robustness analysis of the state-of-the-art methods and RoMe. Empirical results suggest that RoMe has a stronger correlation to human judgment over state-of-the-art metrics in evaluating system-generated sentences across several NLG tasks.
Time-aware Graph Neural Networks for Entity Alignment between Temporal Knowledge Graphs
Mar 13, 2022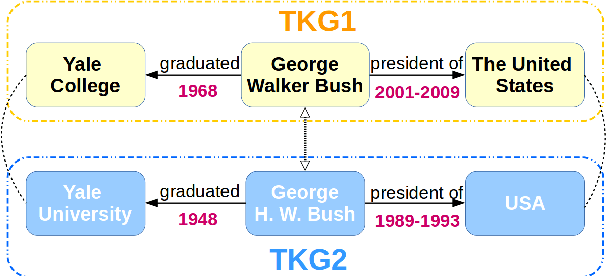

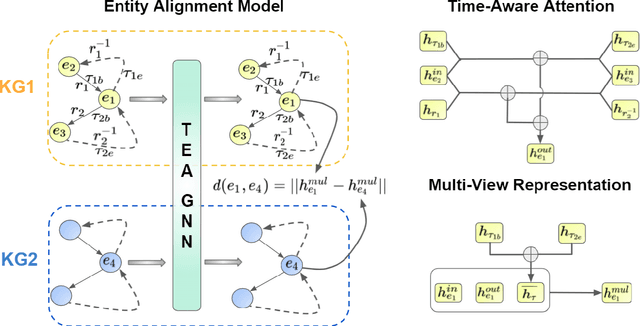
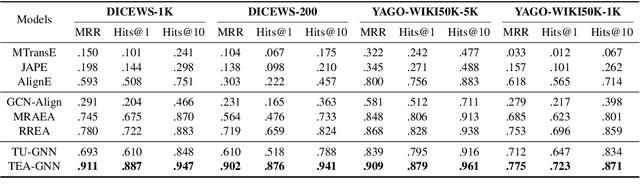
Entity alignment aims to identify equivalent entity pairs between different knowledge graphs (KGs). Recently, the availability of temporal KGs (TKGs) that contain time information created the need for reasoning over time in such TKGs. Existing embedding-based entity alignment approaches disregard time information that commonly exists in many large-scale KGs, leaving much room for improvement. In this paper, we focus on the task of aligning entity pairs between TKGs and propose a novel Time-aware Entity Alignment approach based on Graph Neural Networks (TEA-GNN). We embed entities, relations and timestamps of different KGs into a vector space and use GNNs to learn entity representations. To incorporate both relation and time information into the GNN structure of our model, we use a time-aware attention mechanism which assigns different weights to different nodes with orthogonal transformation matrices computed from embeddings of the relevant relations and timestamps in a neighborhood. Experimental results on multiple real-world TKG datasets show that our method significantly outperforms the state-of-the-art methods due to the inclusion of time information.
Language Model-driven Negative Sampling
Mar 09, 2022


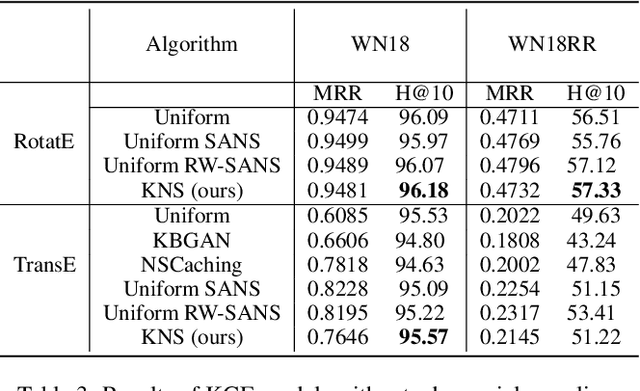
Knowledge Graph Embeddings (KGEs) encode the entities and relations of a knowledge graph (KG) into a vector space with a purpose of representation learning and reasoning for an ultimate downstream task (i.e., link prediction, question answering). Since KGEs follow closed-world assumption and assume all the present facts in KGs to be positive (correct), they also require negative samples as a counterpart for learning process for truthfulness test of existing triples. Therefore, there are several approaches for creating negative samples from the existing positive ones through a randomized distribution. This choice of generating negative sampling affects the performance of the embedding models as well as their generalization. In this paper, we propose an approach for generating negative sampling considering the existing rich textual knowledge in KGs. %The proposed approach is leveraged to cluster other relevant representations of the entities inside a KG. Particularly, a pre-trained Language Model (LM) is utilized to obtain the contextual representation of symbolic entities. Our approach is then capable of generating more meaningful negative samples in comparison to other state of the art methods. Our comprehensive evaluations demonstrate the effectiveness of the proposed approach across several benchmark datasets for like prediction task. In addition, we show cased our the functionality of our approach on a clustering task where other methods fall short.
Geometric Algebra based Embeddings for Static and Temporal Knowledge Graph Completion
Feb 25, 2022
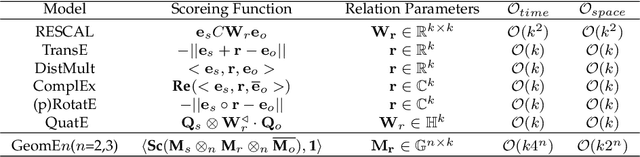
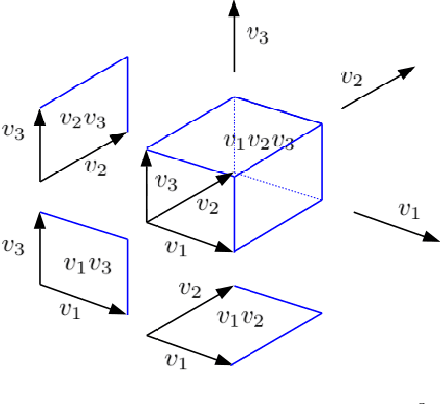
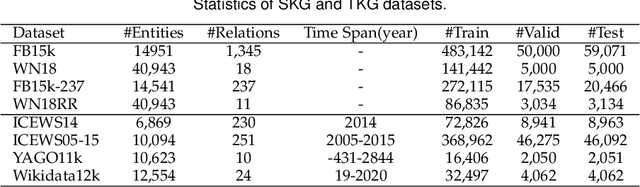
Recent years, Knowledge Graph Embeddings (KGEs) have shown promising performance on link prediction tasks by mapping the entities and relations from a Knowledge Graph (KG) into a geometric space and thus have gained increasing attentions. In addition, many recent Knowledge Graphs involve evolving data, e.g., the fact (\textit{Obama}, \textit{PresidentOf}, \textit{USA}) is valid only from 2009 to 2017. This introduces important challenges for knowledge representation learning since such temporal KGs change over time. In this work, we strive to move beyond the complex or hypercomplex space for KGE and propose a novel geometric algebra based embedding approach, GeomE, which uses multivector representations and the geometric product to model entities and relations. GeomE subsumes several state-of-the-art KGE models and is able to model diverse relations patterns. On top of this, we extend GeomE to TGeomE for temporal KGE, which performs 4th-order tensor factorization of a temporal KG and devises a new linear temporal regularization for time representation learning. Moreover, we study the effect of time granularity on the performance of TGeomE models. Experimental results show that our proposed models achieve the state-of-the-art performances on link prediction over four commonly-used static KG datasets and four well-established temporal KG datasets across various metrics.