 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexical Features Are More Vulnerable, Syntactic Features Have More Predictive Power
Sep 30, 2019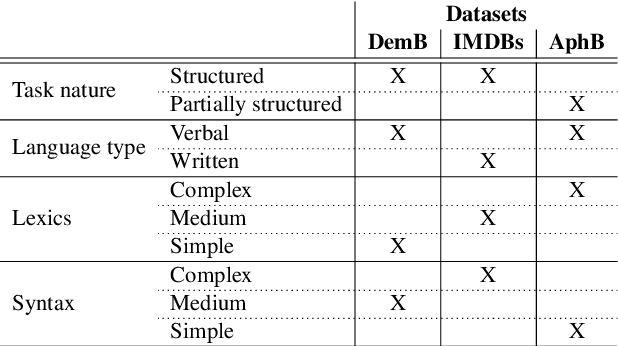
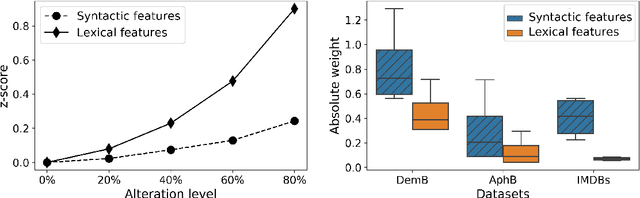
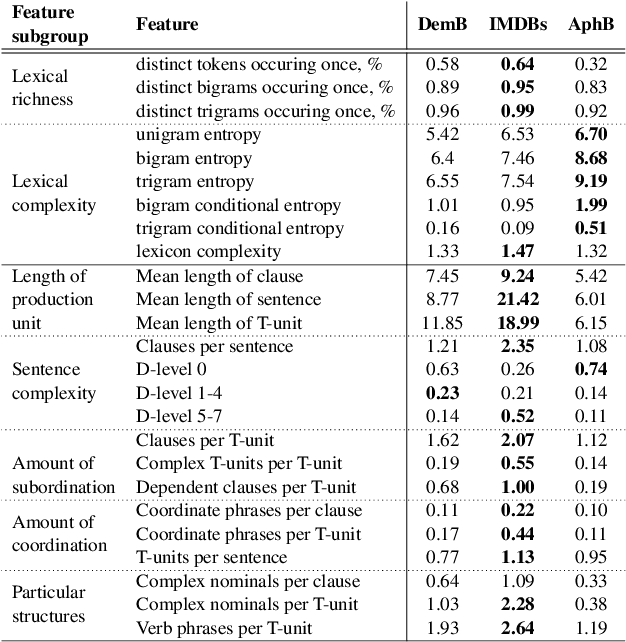
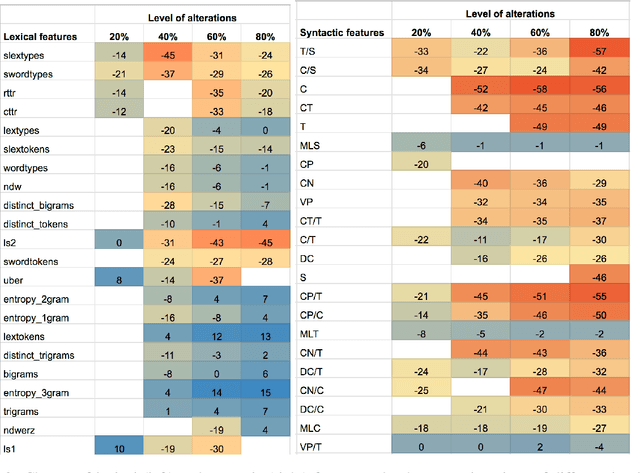
Understanding the vulnerability of linguistic features extracted from noisy text is important for both developing better health text classification models and for interpreting vulnerabilities of natural language models. In this paper, we investigate how generic language characteristics, such as syntax or the lexicon, are impacted by artificial text alterations. The vulnerability of features is analysed from two perspectives: (1) the level of feature value change, and (2) the level of change of feature predictive power as a result of text modifications. We show that lexical features are more sensitive to text modifications than syntactic ones. However, we also demonstrate that these smaller changes of syntactic features have a stronger influence on classification performance downstream, compared to the impact of changes to lexical features. Results are validated across three datasets representing different text-classification tasks, with different levels of lexical and syntactic complexity of both conversational and written language.
Variations on the Chebyshev-Lagrange Activation Function
Jun 24, 2019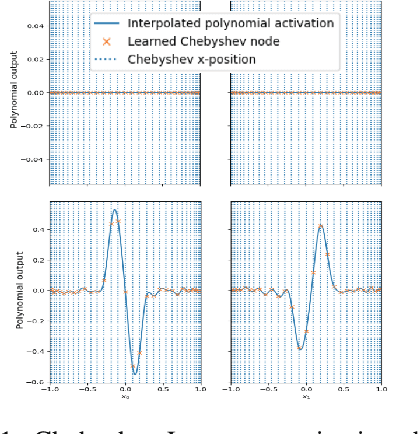
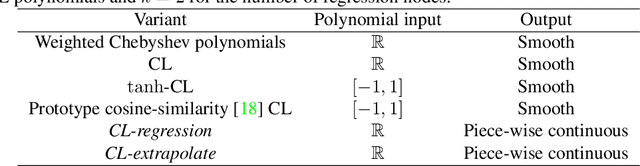
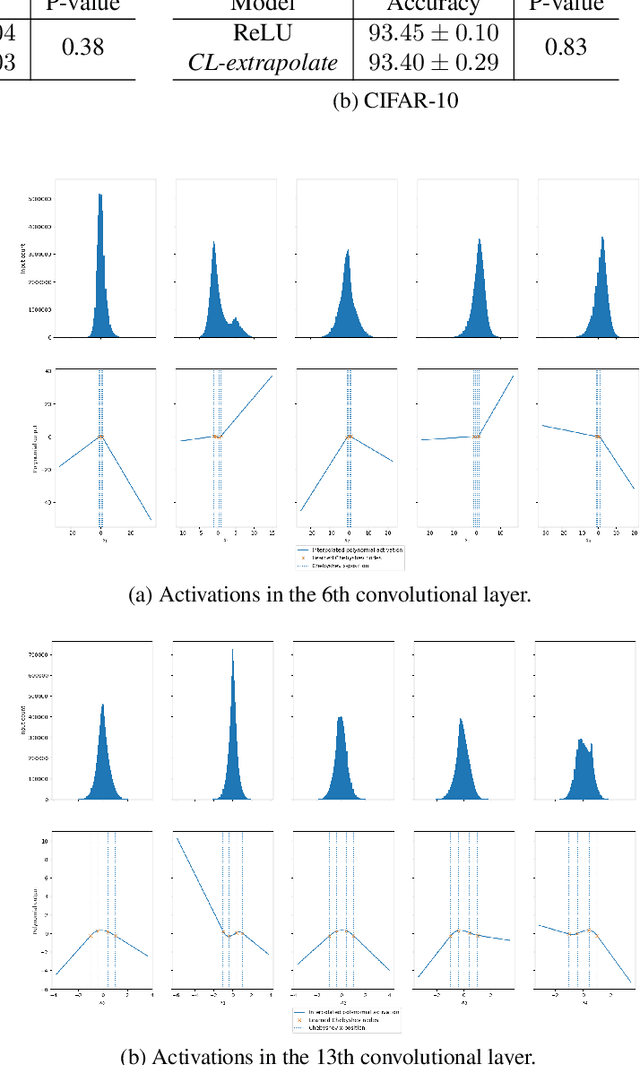

We seek to improve the data efficiency of neural networks and present novel implementations of parameterized piece-wise polynomial activation functions. The parameters are the y-coordinates of n+1 Chebyshev nodes per hidden unit and Lagrangian interpolation between the nodes produces the polynomial on [-1, 1]. We show results for different methods of handling inputs outside [-1, 1] on synthetic datasets, finding significant improvements in capacity of expression and accuracy of interpolation in models that compute some form of linear extrapolation from either ends. We demonstrate competitive or state-of-the-art performance on the classification of images (MNIST and CIFAR-10) and minimally-correlated vectors (DementiaBank) when we replace ReLU or tanh with linearly extrapolated Chebyshev-Lagrange activations in deep residual architectures.
Impact of ASR on Alzheimer's Disease Detection: All Errors are Equal, but Deletions are More Equal than Others
Apr 08, 2019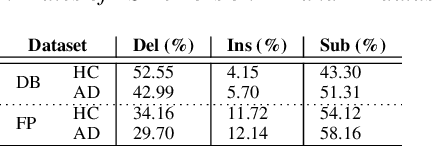
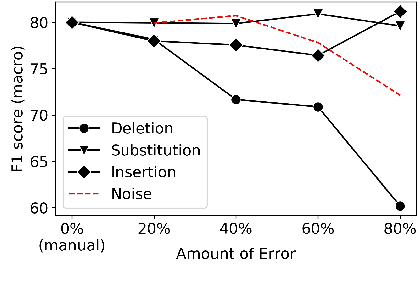
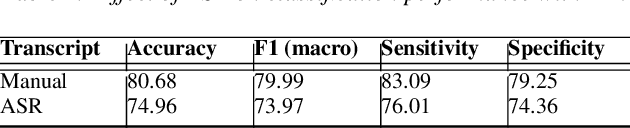
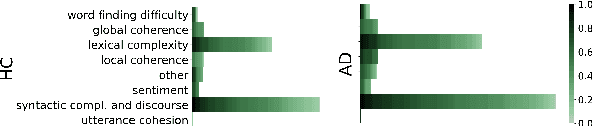
Automatic Speech Recognition (ASR) is a critical component of any fully-automated speech-based Alzheimer's disease (AD) detection model. However, despite years of speech recognition research, little is known about the impact of ASR performance on AD detection. In this paper, we experiment with controlled amounts of artificially generated ASR errors and investigate their influence on AD detection. We find that deletion errors affect AD detection performance the most, due to their impact on the features of syntactic complexity and discourse representation in speech. We show the trend to be generalisable across two different datasets and two different speech-related tasks. As a conclusion, we propose changing the ASR optimization functions to reflect a higher penalty for deletion errors when using ASR for AD detection.
Evaluating the State-of-the-Art of End-to-End Natural Language Generation: The E2E NLG Challenge
Jan 23, 2019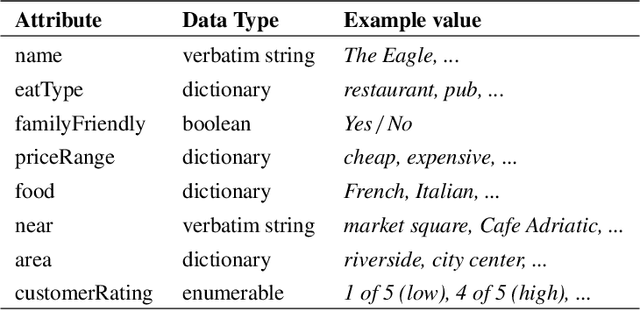
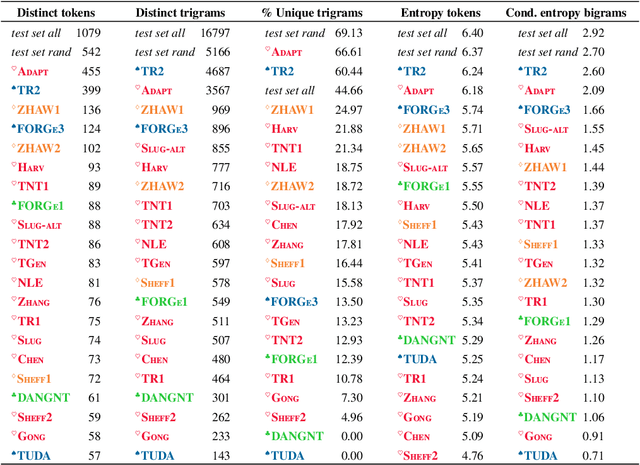
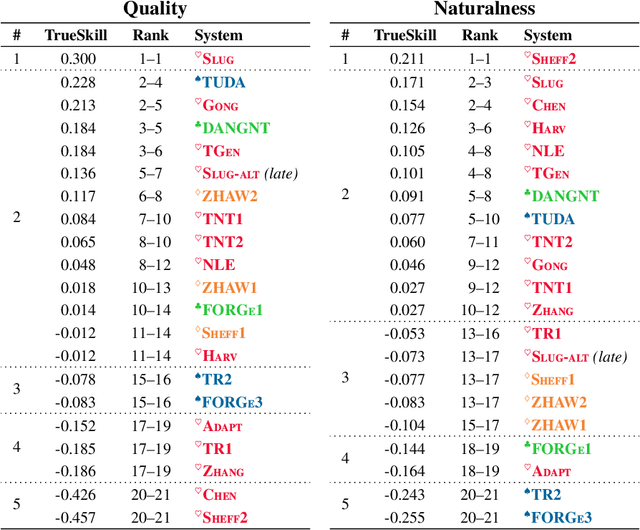
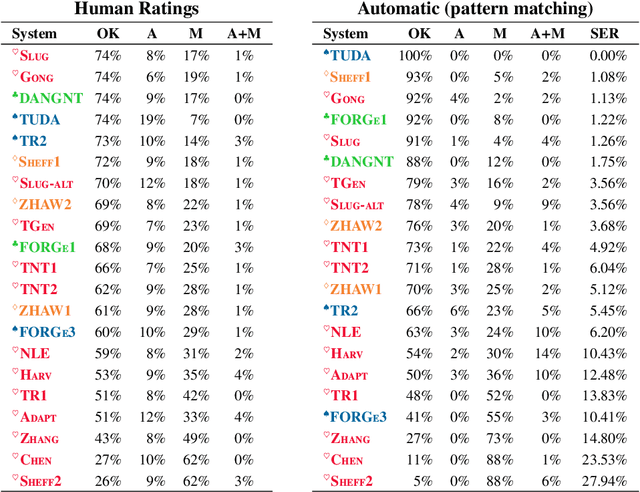
This paper provides a detailed summary of the first shared task on End-to-End Natural Language Generation (NLG) and identifies avenues for future research based on the results. This shared task aimed to assess whether recent end-to-end NLG systems can generate more complex output by learning from datasets containing higher lexical richness, syntactic complexity and diverse discourse phenomena. We compare 62 systems submitted by 17 institutions, covering a wide range of approaches, including machine learning architectures -- with the majority implementing sequence-to-sequence models (seq2seq) -- as well as systems based on grammatical rules and templates. Seq2seq-based systems have demonstrated a great potential for NLG in the challenge. We find that seq2seq systems generally score high in terms of word-overlap metrics and human evaluations of naturalness -- with the winning SLUG system (Juraska et al. 2018) being seq2seq-based. However, vanilla seq2seq models often fail to correctly express a given meaning representation if they lack a strong semantic control mechanism applied during decoding. Moreover, seq2seq models can be outperformed by hand-engineered systems in terms of overall quality, as well as complexity, length and diversity of outputs.
The Effect of Heterogeneous Data for Alzheimer's Disease Detection from Speech
Nov 29, 2018
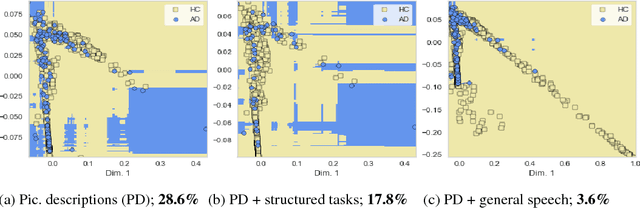
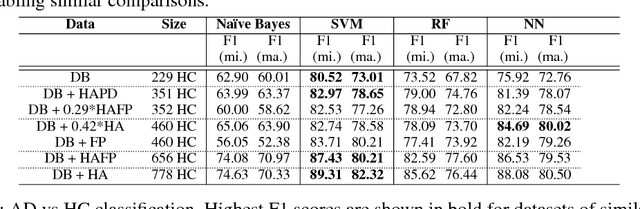
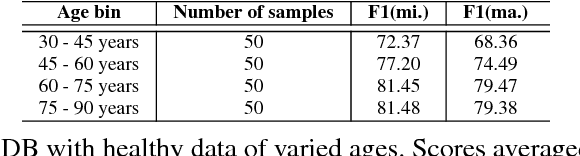
Speech datasets for identifying Alzheimer's disease (AD) are generally restricted to participants performing a single task, e.g. describing an image shown to them. As a result, models trained on linguistic features derived from such datasets may not be generalizable across tasks. Building on prior work demonstrating that same-task data of healthy participants helps improve AD detection on a single-task dataset of pathological speech, we augment an AD-specific dataset consisting of subjects describing a picture with multi-task healthy data. We demonstrate that normative data from multiple speech-based tasks helps improve AD detection by up to 9%. Visualization of decision boundaries reveals that models trained on a combination of structured picture descriptions and unstructured conversational speech have the least out-of-task error and show the most potential to generalize to multiple tasks. We analyze the impact of age of the added samples and if they affect fairness in classification. We also provide explanations for a possible inductive bias effect across tasks using model-agnostic feature anchors. This work highlights the need for heterogeneous datasets for encoding changes in multiple facets of cognition and for developing a task-independent AD detection model.
Findings of the E2E NLG Challenge
Oct 02, 2018

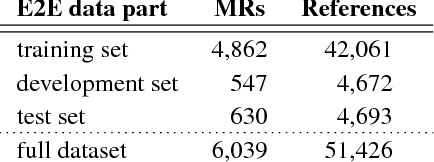
This paper summarises the experimental setup and results of the first shared task on end-to-end (E2E) natural language generation (NLG) in spoken dialogue systems. Recent end-to-end generation systems are promising since they reduce the need for data annotation. However, they are currently limited to small, delexicalised datasets. The E2E NLG shared task aims to assess whether these novel approaches can generate better-quality output by learning from a dataset containing higher lexical richness, syntactic complexity and diverse discourse phenomena. We compare 62 systems submitted by 17 institutions, covering a wide range of approaches, including machine learning architectures -- with the majority implementing sequence-to-sequence models (seq2seq) -- as well as systems based on grammatical rules and templates.
Isolating effects of age with fair representation learning when assessing dementia
Sep 26, 2018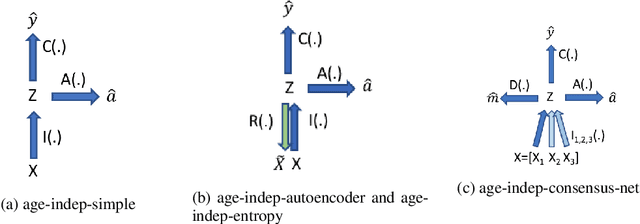
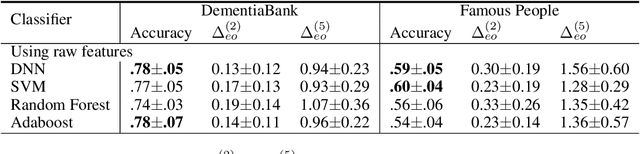
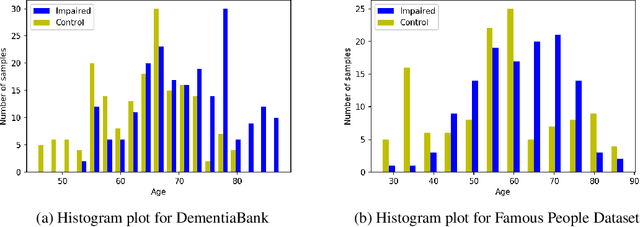
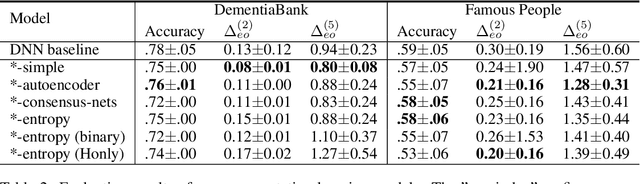
One of the most prevalent symptoms among the elderly population, dementia, can be detected by classifiers trained on linguistic features extracted from narrative transcripts. However, these linguistic features are impacted in a similar but different fashion by the normal aging process. Aging is therefore a confounding factor, whose effects have been hard for machine learning classifiers to isolate. In this paper, we show that deep neural network (DNN) classifiers can infer ages from linguistic features, which is an entanglement that could lead to unfairness across age groups. We show this problem is caused by undesired activations of v-structures in causality diagrams, and it could be addressed with fair representation learning. We build neural network classifiers that learn low-dimensional representations reflecting the impacts of dementia yet discarding the effects of age. To evaluate these classifiers, we specify a model-agnostic score $\Delta_{eo}^{(N)}$ measuring how classifier results are disentangled from age. Our best models outperform baseline neural network classifiers in disentanglement, while compromising accuracy by as little as 2.56\% and 2.25\% on DementiaBank and the Famous People dataset respectively.
Detecting cognitive impairments by agreeing on interpretations of linguistic features
Sep 04, 2018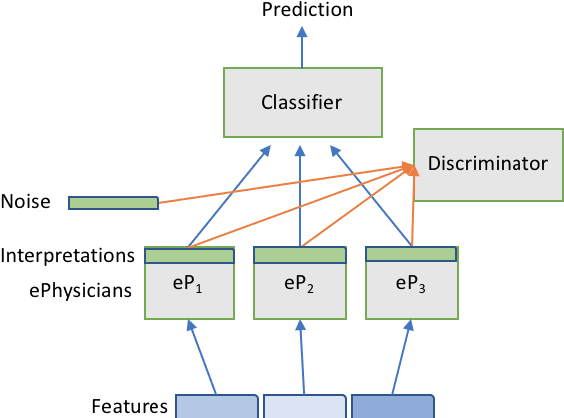



Linguistic features have shown promising applications for detecting various cognitive impairments. To improve detection accuracies, increasing the amount of data or the number of linguistic features have been two applicable approaches. However, acquiring additional clinical data could be expensive, and hand-carving features are burdensome. In this paper, we take a third approach, putting forward Consensus Networks (CN), a framework to classify after reaching agreements between modalities. We divide the linguistic features into non-overlapping subsets according to their modalities, let neural networks learn low-dimensional representations that agree with each other. These representations are passed into a classifier network. All neural networks are optimized iteratively. In this paper, we also present two methods that empirically improve the performance of CN. We then present ablation studies to illustrate the effectiveness of modality division. To understand further what happens in Consensus Networks, we visualize the interpretation vectors during training procedures. They demonstrate symmetry in an aggregate manner. Overall, using all of the 413 linguistic features, our models significantly outperform traditional classifiers, which are used by the state-of-the-art papers.
Semi-supervised classification by reaching consensus among modalities
May 23, 2018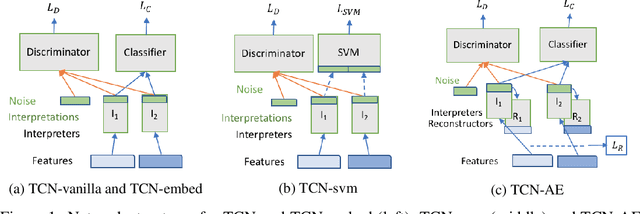

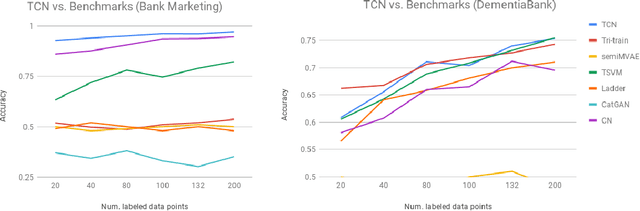
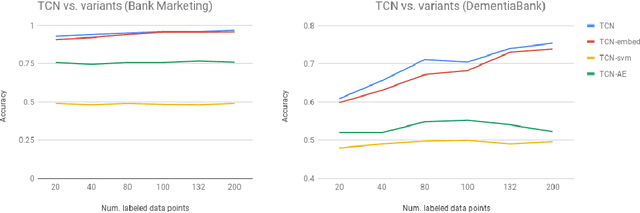
This paper introduces transductive consensus network (TCNs), as an extension of a consensus network (CN), for semi-supervised learning. TCN does multi-modal classification based on a few available labels by urging the {\em interpretations} of different modalities to resemble each other. We formulate the multi-modal, semi-supervised learning problem, put forward TCN for multi-modal semi-supervised learning task, and its several variants. To understand the mechanisms of TCN, we formulate the {\em similarity} of the interpretations as the negative relative Jensen-Shannon divergence, and show that a consensus state beneficial for classification desires a stable but not perfect similarity between the interpretations. We show the performances of TCN are better than best benchmark algorithms given only 20 and 80 labeled samples on Bank Marketing and the DementiaBank dataset respectively, and align with their performances given more labeled samples.
RankME: Reliable Human Ratings for Natural Language Generation
Mar 15, 2018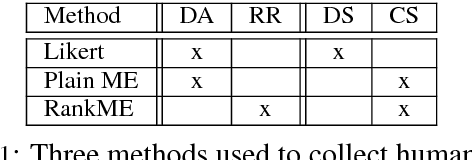

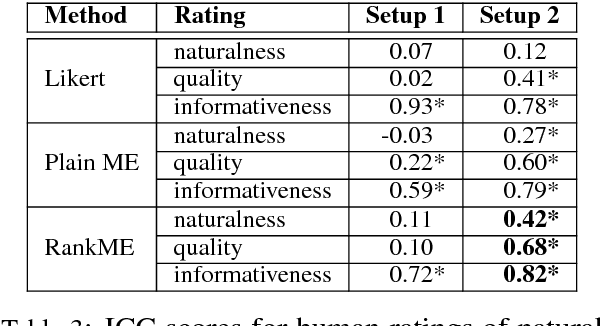
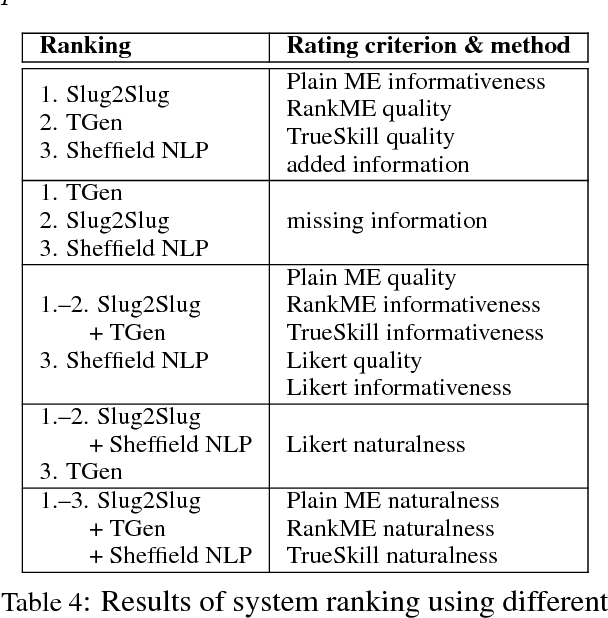
Human evaluation for natural language generation (NLG) often suffers from inconsistent user ratings. While previous research tends to attribute this problem to individual user preferences, we show that the quality of human judgements can also be improved by experimental design. We present a novel rank-based magnitude estimation method (RankME), which combines the use of continuous scales and relative assessments. We show that RankME significantly improves the reliability and consistency of human ratings compared to traditional evaluation methods. In addition, we show that it is possible to evaluate NLG systems according to multiple, distinct criteria, which is important for error analysis. Finally, we demonstrate that RankME, in combination with Bayesian estimation of system quality, is a cost-effective alternative for ranking multiple NLG systems.
* Accepted to NAACL 2018 (The 2018 Conference of the North American Chapter of the Association for Computational Linguistics)