 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Properties of Decision Trees on Real-valued and Categorical Features
Oct 18, 2022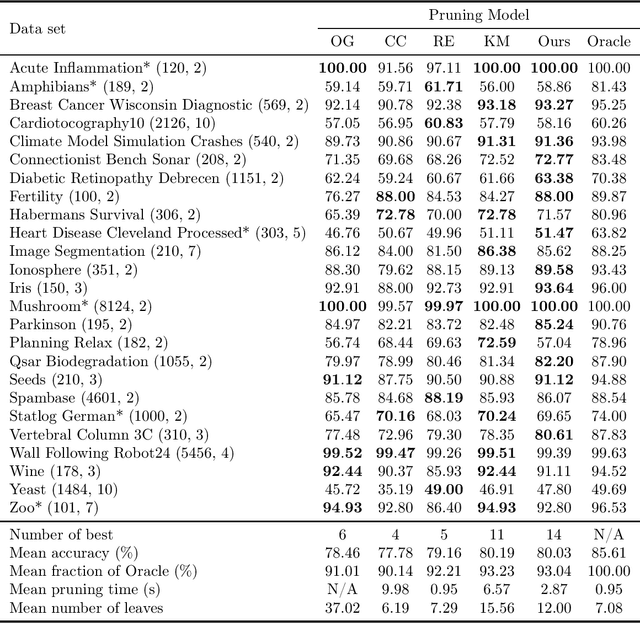

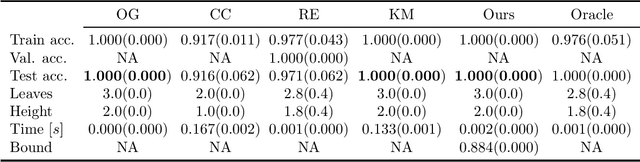
We revisit binary decision trees from the perspective of partitions of the data. We introduce the notion of partitioning function, and we relate it to the growth function and to the VC dimension. We consider three types of features: real-valued, categorical ordinal and categorical nominal, with different split rules for each. For each feature type, we upper bound the partitioning function of the class of decision stumps before extending the bounds to the class of general decision tree (of any fixed structure) using a recursive approach. Using these new results, we are able to find the exact VC dimension of decision stumps on examples of $\ell$ real-valued features, which is given by the largest integer $d$ such that $2\ell \ge \binom{d}{\lfloor\frac{d}{2}\rfloor}$. Furthermore, we show that the VC dimension of a binary tree structure with $L_T$ leaves on examples of $\ell$ real-valued features is in $O(L_T \log(L_T\ell))$. Finally, we elaborate a pruning algorithm based on these results that performs better than the cost-complexity and reduced-error pruning algorithms on a number of data sets, with the advantage that no cross-validation is required.
Improving Generalization Bounds for VC Classes Using the Hypergeometric Tail Inversion
Oct 29, 2021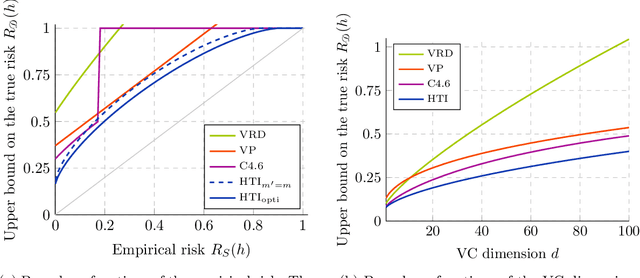
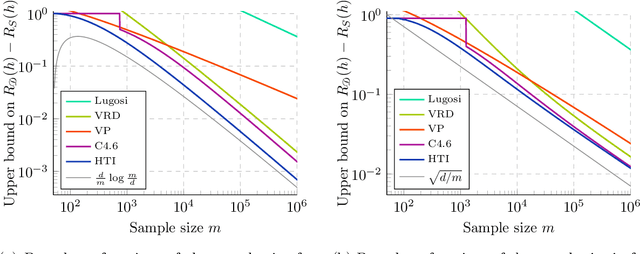
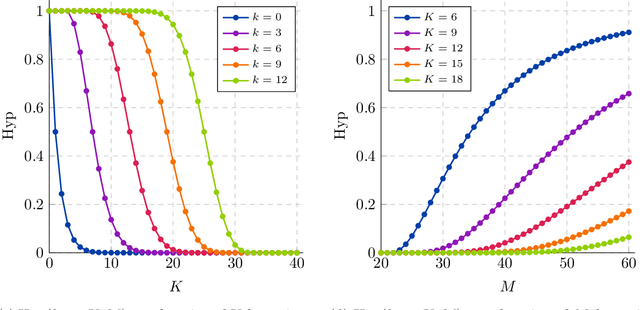
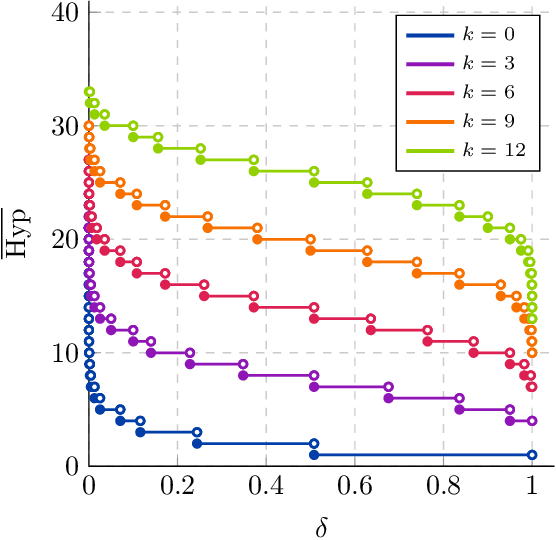
We significantly improve the generalization bounds for VC classes by using two main ideas. First, we consider the hypergeometric tail inversion to obtain a very tight non-uniform distribution-independent risk upper bound for VC classes. Second, we optimize the ghost sample trick to obtain a further non-negligible gain. These improvements are then used to derive a relative deviation bound, a multiclass margin bound, as well as a lower bound. Numerical comparisons show that the new bound is nearly never vacuous, and is tighter than other VC bounds for all reasonable data set sizes.
Decision trees as partitioning machines to characterize their generalization properties
Oct 14, 2020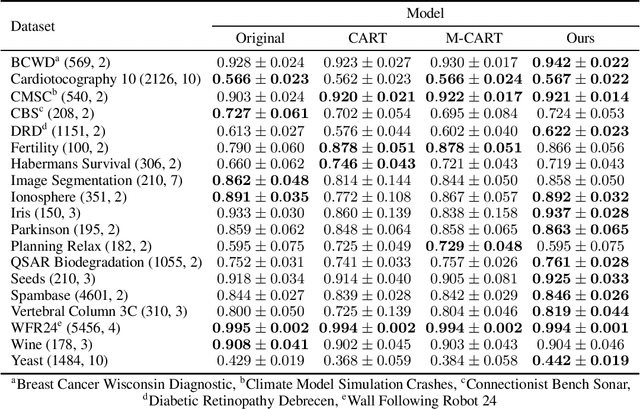

Decision trees are popular machine learning models that are simple to build and easy to interpret. Even though algorithms to learn decision trees date back to almost 50 years, key properties affecting their generalization error are still weakly bounded. Hence, we revisit binary decision trees on real-valued features from the perspective of partitions of the data. We introduce the notion of partitioning function, and we relate it to the growth function and to the VC dimension. Using this new concept, we are able to find the exact VC dimension of decision stumps, which is given by the largest integer $d$ such that $2\ell \ge \binom{d}{\left\lfloor\frac{d}{2}\right\rfloor}$, where $\ell$ is the number of real-valued features. We provide a recursive expression to bound the partitioning functions, resulting in a upper bound on the growth function of any decision tree structure. This allows us to show that the VC dimension of a binary tree structure with $N$ internal nodes is of order $N \log(N\ell)$. Finally, we elaborate a pruning algorithm based on these results that performs better than the CART algorithm on a number of datasets, with the advantage that no cross-validation is required.
Attending Form and Context to Generate Specialized Out-of-VocabularyWords Representations
Dec 14, 2019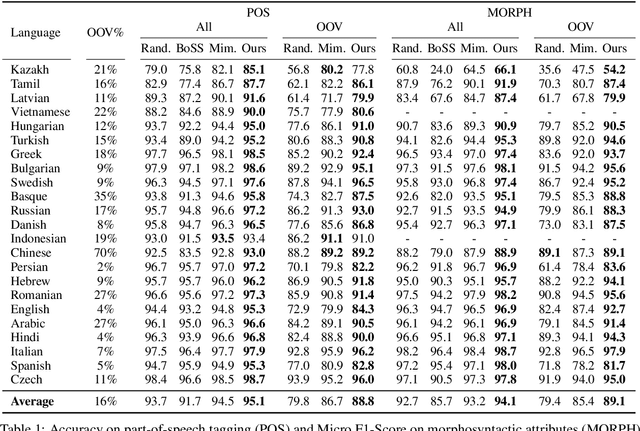
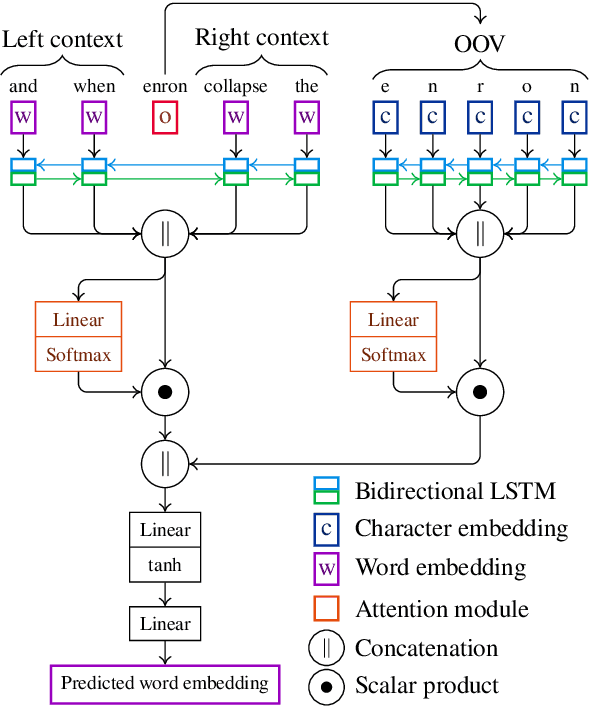
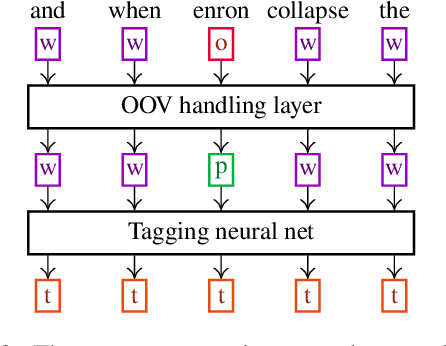

We propose a new contextual-compositional neural network layer that handles out-of-vocabulary (OOV) words in natural language processing (NLP) tagging tasks. This layer consists of a model that attends to both the character sequence and the context in which the OOV words appear. We show that our model learns to generate task-specific \textit{and} sentence-dependent OOV word representations without the need for pre-training on an embedding table, unlike previous attempts. We insert our layer in the state-of-the-art tagging model of \citet{plank2016multilingual} and thoroughly evaluate its contribution on 23 different languages on the task of jointly tagging part-of-speech and morphosyntactic attributes. Our OOV handling method successfully improves performances of this model on every language but one to achieve a new state-of-the-art on the Universal Dependencies Dataset 1.4.
Predicting and interpreting embeddings for out of vocabulary words in downstream tasks
Mar 02, 2019
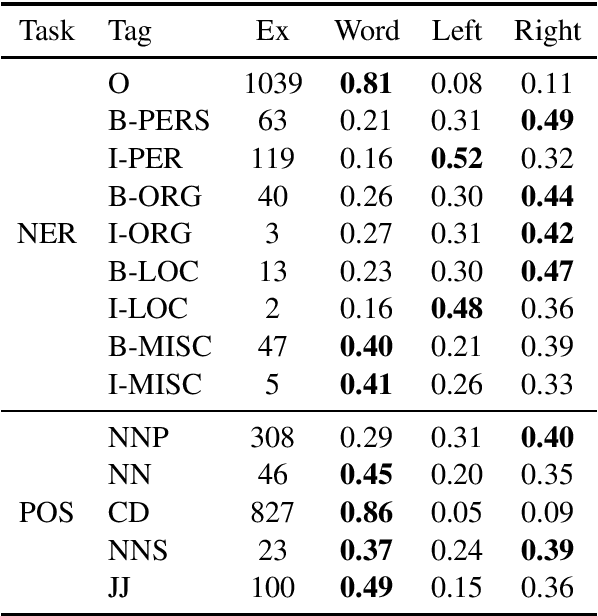

We propose a novel way to handle out of vocabulary (OOV) words in downstream natural language processing (NLP) tasks. We implement a network that predicts useful embeddings for OOV words based on their morphology and on the context in which they appear. Our model also incorporates an attention mechanism indicating the focus allocated to the left context words, the right context words or the word's characters, hence making the prediction more interpretable. The model is a ``drop-in'' module that is jointly trained with the downstream task's neural network, thus producing embeddings specialized for the task at hand. When the task is mostly syntactical, we observe that our model aims most of its attention on surface form characters. On the other hand, for tasks more semantical, the network allocates more attention to the surrounding words. In all our tests, the module helps the network to achieve better performances in comparison to the use of simple random embeddings.
* 2 pages, 0 figures, 2 tables