 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCasual Indoor HDR Radiance Capture from Omnidirectional Images
Aug 16, 2022
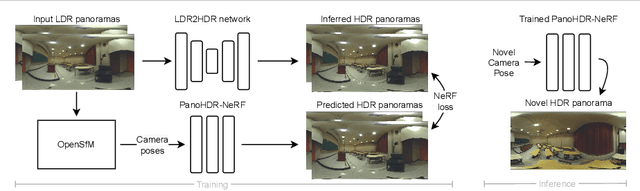


We present PanoHDR-NeRF, a novel pipeline to casually capture a plausible full HDR radiance field of a large indoor scene without elaborate setups or complex capture protocols. First, a user captures a low dynamic range (LDR) omnidirectional video of the scene by freely waving an off-the-shelf camera around the scene. Then, an LDR2HDR network uplifts the captured LDR frames to HDR, subsequently used to train a tailored NeRF++ model. The resulting PanoHDR-NeRF pipeline can estimate full HDR panoramas from any location of the scene. Through experiments on a novel test dataset of a variety of real scenes with the ground truth HDR radiance captured at locations not seen during training, we show that PanoHDR-NeRF predicts plausible radiance from any scene point. We also show that the HDR images produced by PanoHDR-NeRF can synthesize correct lighting effects, enabling the augmentation of indoor scenes with synthetic objects that are lit correctly.
Robust Scene Inference under Noise-Blur Dual Corruptions
Jul 24, 2022
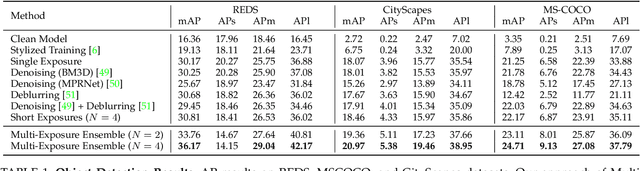
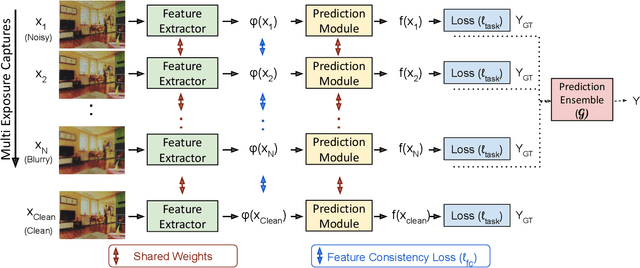
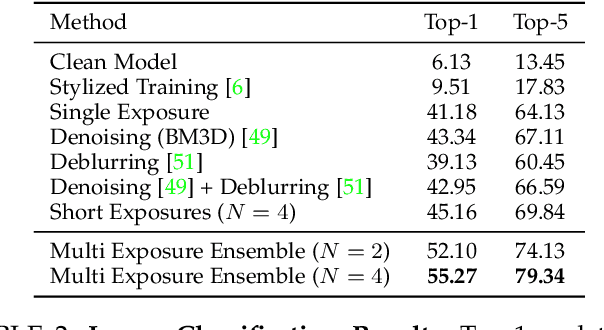
Scene inference under low-light is a challenging problem due to severe noise in the captured images. One way to reduce noise is to use longer exposure during the capture. However, in the presence of motion (scene or camera motion), longer exposures lead to motion blur, resulting in loss of image information. This creates a trade-off between these two kinds of image degradations: motion blur (due to long exposure) vs. noise (due to short exposure), also referred as a dual image corruption pair in this paper. With the rise of cameras capable of capturing multiple exposures of the same scene simultaneously, it is possible to overcome this trade-off. Our key observation is that although the amount and nature of degradation varies for these different image captures, the semantic content remains the same across all images. To this end, we propose a method to leverage these multi exposure captures for robust inference under low-light and motion. Our method builds on a feature consistency loss to encourage similar results from these individual captures, and uses the ensemble of their final predictions for robust visual recognition. We demonstrate the effectiveness of our approach on simulated images as well as real captures with multiple exposures, and across the tasks of object detection and image classification.
Overparameterization Improves StyleGAN Inversion
May 12, 2022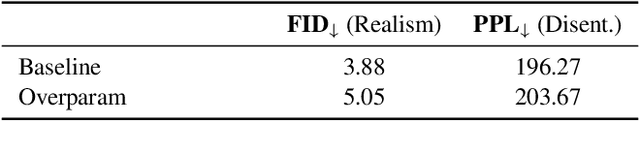
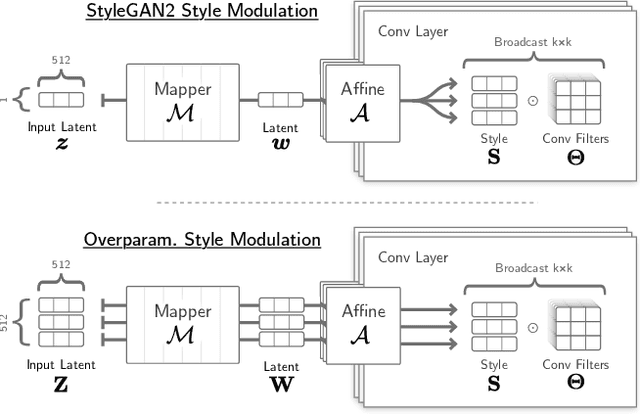
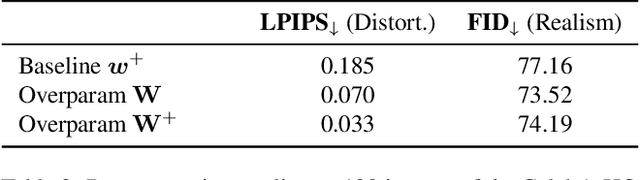
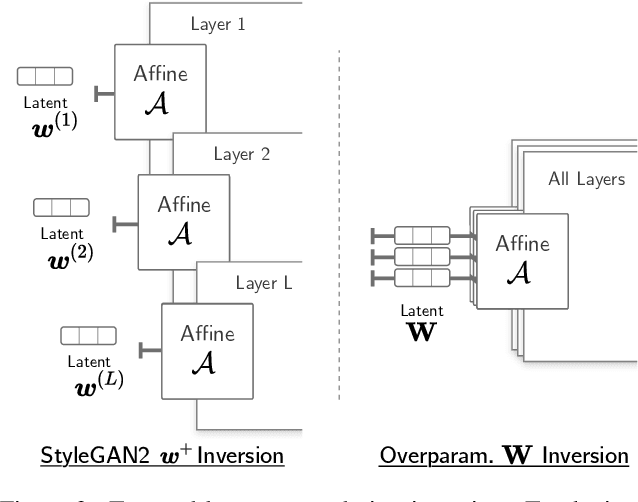
Deep generative models like StyleGAN hold the promise of semantic image editing: modifying images by their content, rather than their pixel values. Unfortunately, working with arbitrary images requires inverting the StyleGAN generator, which has remained challenging so far. Existing inversion approaches obtain promising yet imperfect results, having to trade-off between reconstruction quality and downstream editability. To improve quality, these approaches must resort to various techniques that extend the model latent space after training. Taking a step back, we observe that these methods essentially all propose, in one way or another, to increase the number of free parameters. This suggests that inversion might be difficult because it is underconstrained. In this work, we address this directly and dramatically overparameterize the latent space, before training, with simple changes to the original StyleGAN architecture. Our overparameterization increases the available degrees of freedom, which in turn facilitates inversion. We show that this allows us to obtain near-perfect image reconstruction without the need for encoders nor for altering the latent space after training. Our approach also retains editability, which we demonstrate by realistically interpolating between images.
Guided Co-Modulated GAN for 360° Field of View Extrapolation
Apr 15, 2022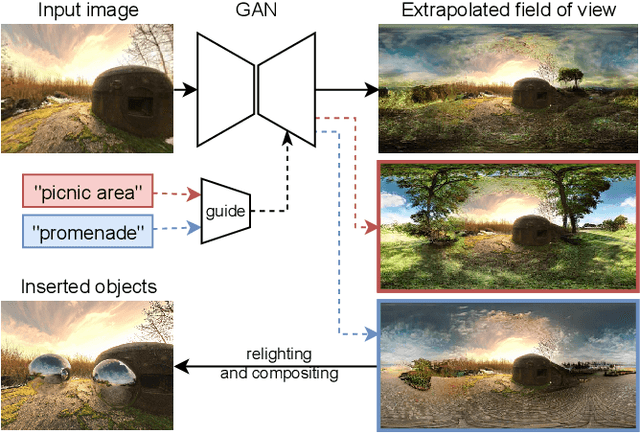
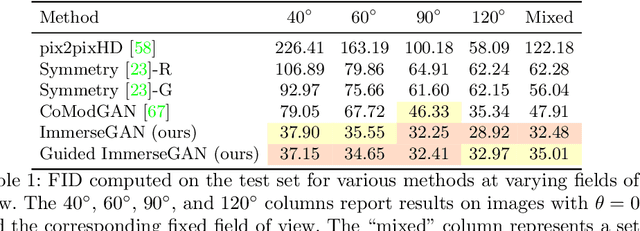
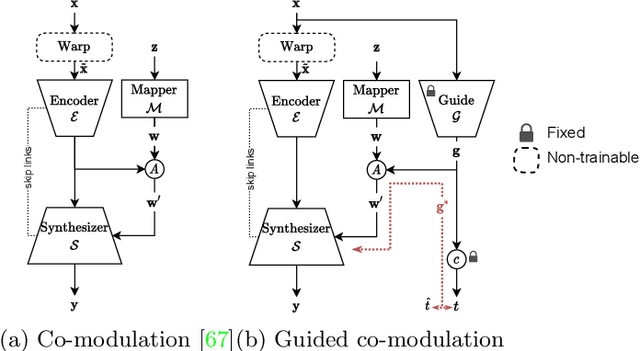

We propose a method to extrapolate a 360{\deg} field of view from a single image that allows for user-controlled synthesis of the out-painted content. To do so, we propose improvements to an existing GAN-based in-painting architecture for out-painting panoramic image representation. Our method obtains state-of-the-art results and outperforms previous methods on standard image quality metrics. To allow controlled synthesis of out-painting, we introduce a novel guided co-modulation framework, which drives the image generation process with a common pretrained discriminative model. Doing so maintains the high visual quality of generated panoramas while enabling user-controlled semantic content in the extrapolated field of view. We demonstrate the state-of-the-art results of our method on field of view extrapolation both qualitatively and quantitatively, providing thorough analysis of our novel editing capabilities. Finally, we demonstrate that our approach benefits the photorealistic virtual insertion of highly glossy objects in photographs.
Matching Feature Sets for Few-Shot Image Classification
Apr 02, 2022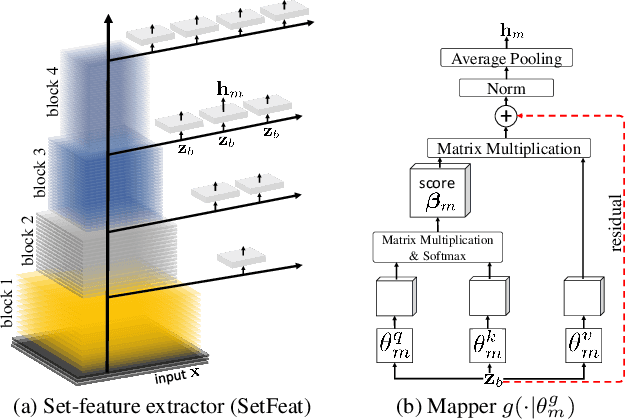
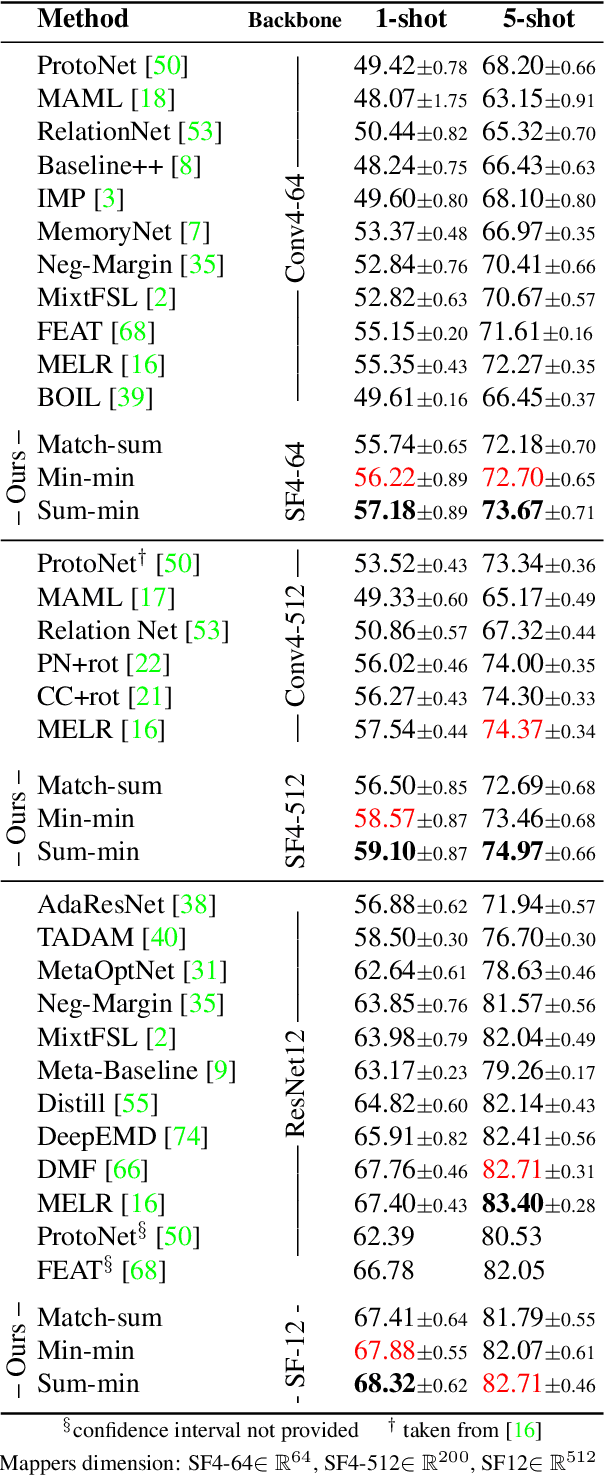
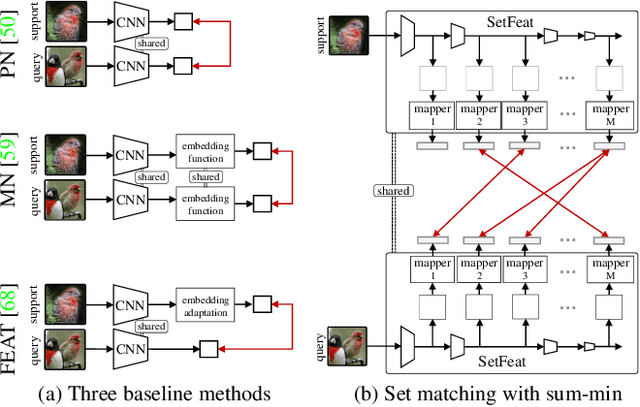
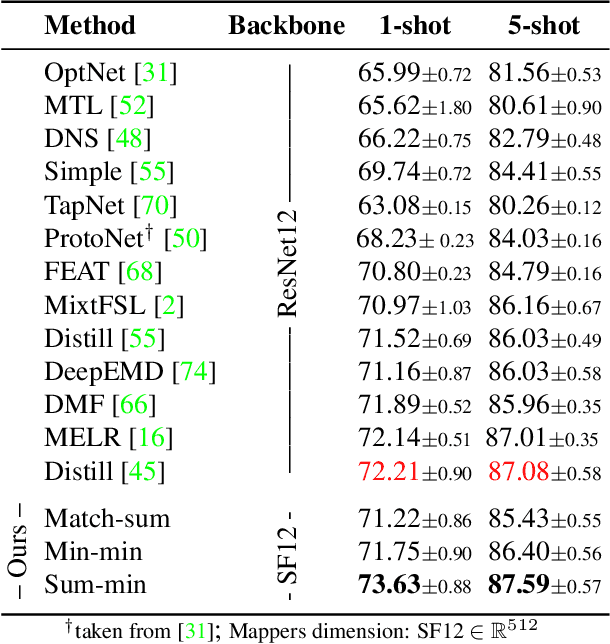
In image classification, it is common practice to train deep networks to extract a single feature vector per input image. Few-shot classification methods also mostly follow this trend. In this work, we depart from this established direction and instead propose to extract sets of feature vectors for each image. We argue that a set-based representation intrinsically builds a richer representation of images from the base classes, which can subsequently better transfer to the few-shot classes. To do so, we propose to adapt existing feature extractors to instead produce sets of feature vectors from images. Our approach, dubbed SetFeat, embeds shallow self-attention mechanisms inside existing encoder architectures. The attention modules are lightweight, and as such our method results in encoders that have approximately the same number of parameters as their original versions. During training and inference, a set-to-set matching metric is used to perform image classification. The effectiveness of our proposed architecture and metrics is demonstrated via thorough experiments on standard few-shot datasets -- namely miniImageNet, tieredImageNet, and CUB -- in both the 1- and 5-shot scenarios. In all cases but one, our method outperforms the state-of-the-art.
ManiFest: Manifold Deformation for Few-shot Image Translation
Nov 29, 2021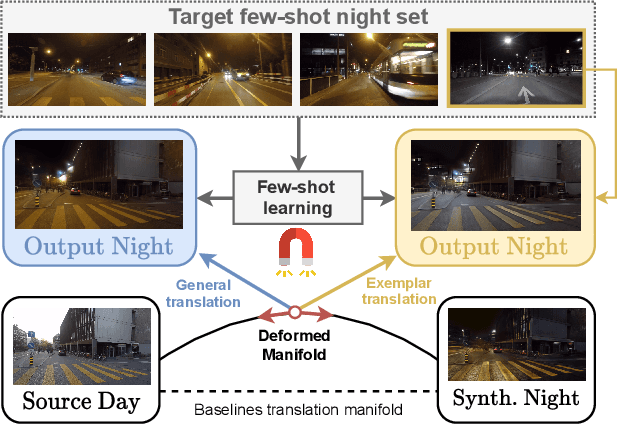
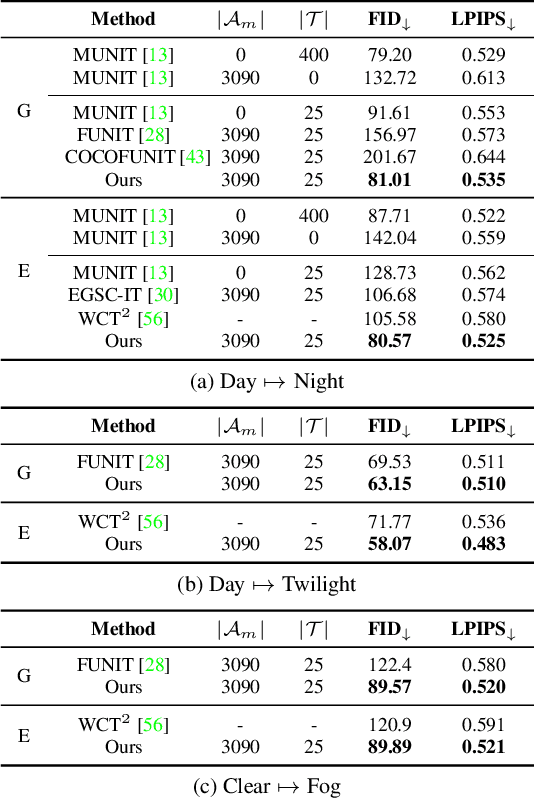
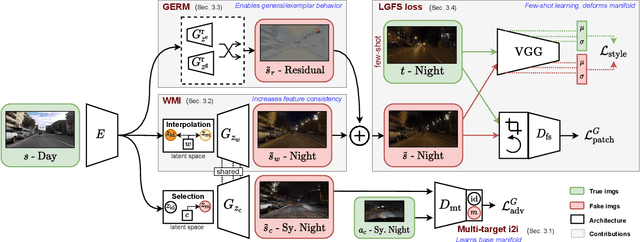
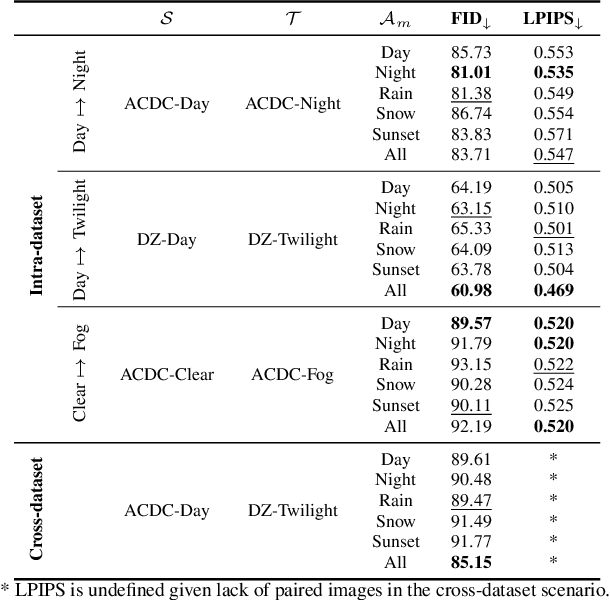
Most image-to-image translation methods require a large number of training images, which restricts their applicability. We instead propose ManiFest: a framework for few-shot image translation that learns a context-aware representation of a target domain from a few images only. To enforce feature consistency, our framework learns a style manifold between source and proxy anchor domains (assumed to be composed of large numbers of images). The learned manifold is interpolated and deformed towards the few-shot target domain via patch-based adversarial and feature statistics alignment losses. All of these components are trained simultaneously during a single end-to-end loop. In addition to the general few-shot translation task, our approach can alternatively be conditioned on a single exemplar image to reproduce its specific style. Extensive experiments demonstrate the efficacy of ManiFest on multiple tasks, outperforming the state-of-the-art on all metrics and in both the general- and exemplar-based scenarios. Our code is available at https://github.com/cv-rits/Manifest .
Image-to-Image Translation with Low Resolution Conditioning
Jul 23, 2021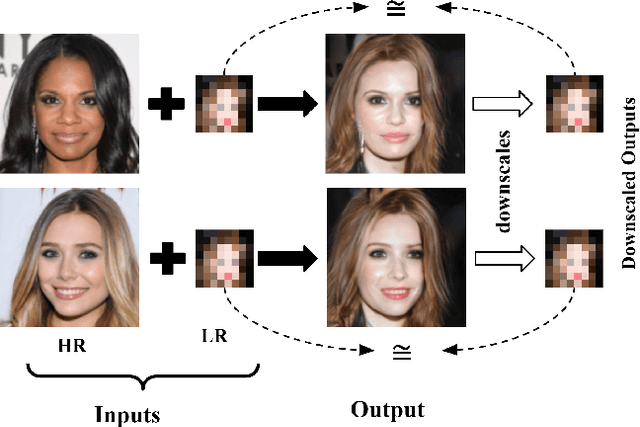
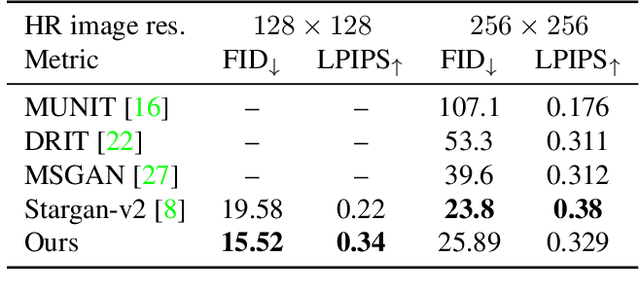
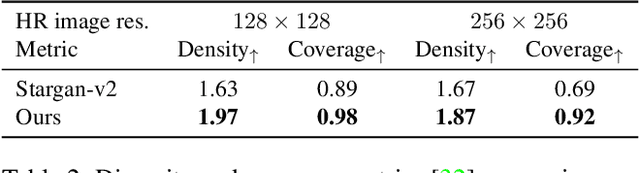
Most image-to-image translation methods focus on learning mappings across domains with the assumption that images share content (e.g., pose) but have their own domain-specific information known as style. When conditioned on a target image, such methods aim to extract the style of the target and combine it with the content of the source image. In this work, we consider the scenario where the target image has a very low resolution. More specifically, our approach aims at transferring fine details from a high resolution (HR) source image to fit a coarse, low resolution (LR) image representation of the target. We therefore generate HR images that share features from both HR and LR inputs. This differs from previous methods that focus on translating a given image style into a target content, our translation approach being able to simultaneously imitate the style and merge the structural information of the LR target. Our approach relies on training the generative model to produce HR target images that both 1) share distinctive information of the associated source image; 2) correctly match the LR target image when downscaled. We validate our method on the CelebA-HQ and AFHQ datasets by demonstrating improvements in terms of visual quality, diversity and coverage. Qualitative and quantitative results show that when dealing with intra-domain image translation, our method generates more realistic samples compared to state-of-the-art methods such as Stargan-v2
Persistent Mixture Model Networks for Few-Shot Image Classification
Nov 24, 2020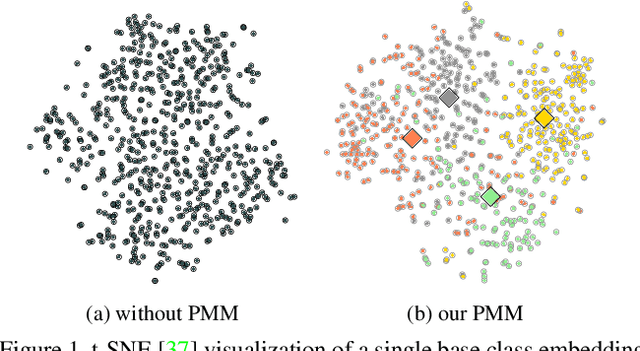
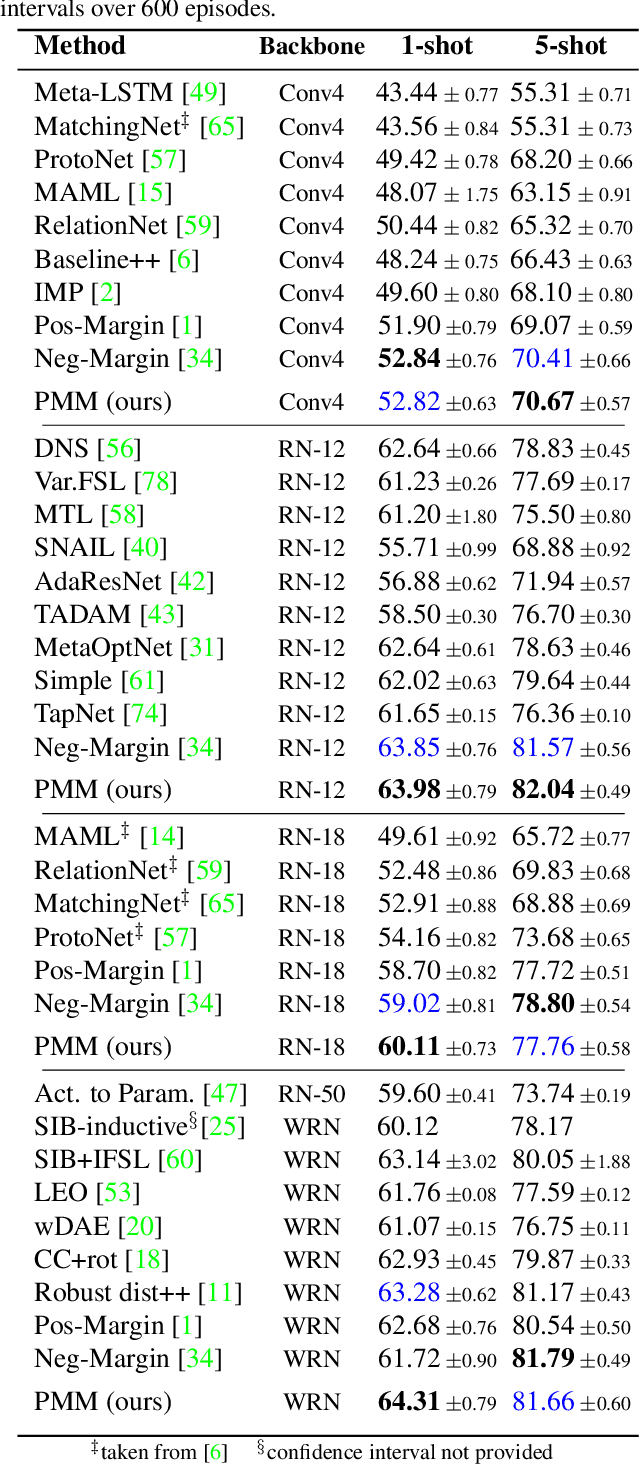
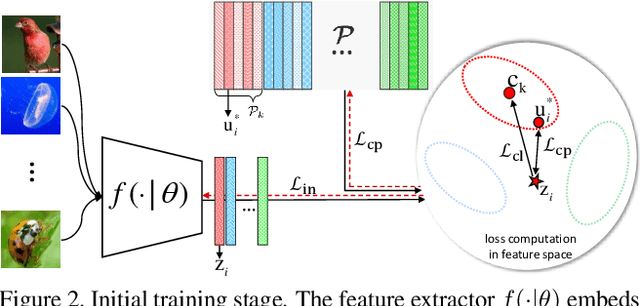
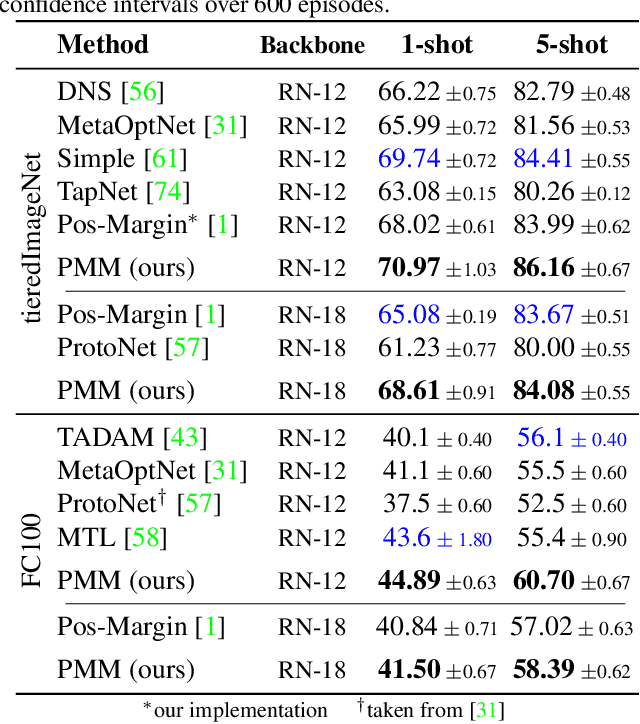
We introduce Persistent Mixture Model (PMM) networks for representation learning in the few-shot image classification context. While previous methods represent classes with a single centroid or rely on post hoc clustering methods, our method learns a mixture model for each base class jointly with the data representation in an end-to-end manner. The PMM training algorithm is organized into two main stages: 1) initial training and 2) progressive following. First, the initial estimate for multi-component mixtures is learned for each class in the base domain using a combination of two loss functions (competitive and collaborative). The resulting network is then progressively refined through a leader-follower learning procedure, which uses the current estimate of the learner as a fixed "target" network. This target network is used to make a consistent assignment of instances to mixture components, in order to increase performance while stabilizing the training. The effectiveness of our joint representation/mixture learning approach is demonstrated with extensive experiments on four standard datasets and four backbones. In particular, we demonstrate that when we combine our robust representation with recent alignment- and margin-based approaches, we achieve new state-of-the-art results in the inductive setting, with an absolute accuracy for 5-shot classification of 82.45% on miniImageNet, 88.20% with tieredImageNet, and 60.70% in FC100, all using the ResNet-12 backbone.
Deep SVBRDF Estimation on Real Materials
Oct 08, 2020

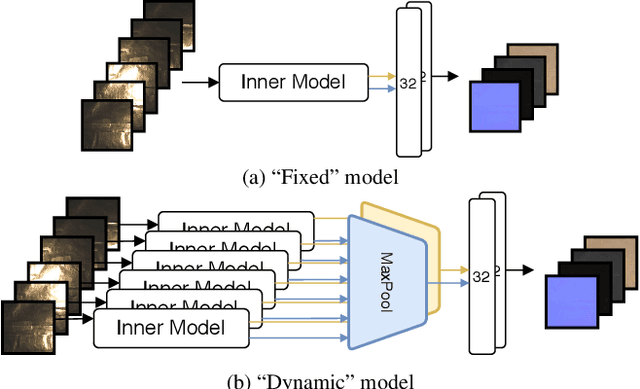
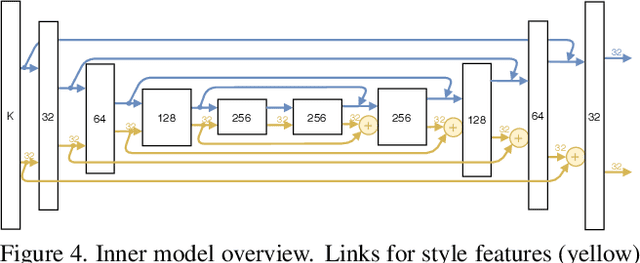
Recent work has demonstrated that deep learning approaches can successfully be used to recover accurate estimates of the spatially-varying BRDF (SVBRDF) of a surface from as little as a single image. Closer inspection reveals, however, that most approaches in the literature are trained purely on synthetic data, which, while diverse and realistic, is often not representative of the richness of the real world. In this paper, we show that training such networks exclusively on synthetic data is insufficient to achieve adequate results when tested on real data. Our analysis leverages a new dataset of real materials obtained with a novel portable multi-light capture apparatus. Through an extensive series of experiments and with the use of a novel deep learning architecture, we explore two strategies for improving results on real data: finetuning, and a per-material optimization procedure. We show that adapting network weights to real data is of critical importance, resulting in an approach which significantly outperforms previous methods for SVBRDF estimation on real materials. Dataset and code are available at https://lvsn.github.io/real-svbrdf
Rain rendering for evaluating and improving robustness to bad weather
Sep 06, 2020

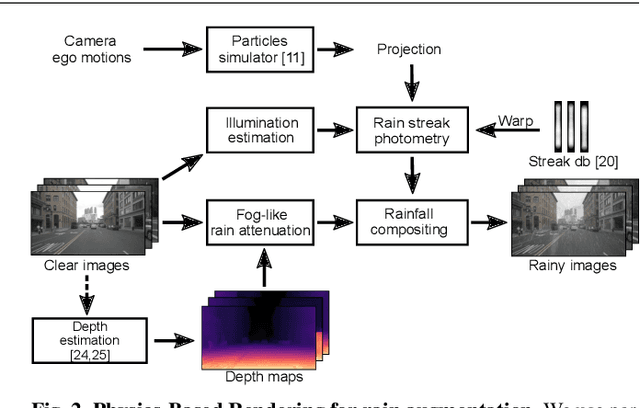
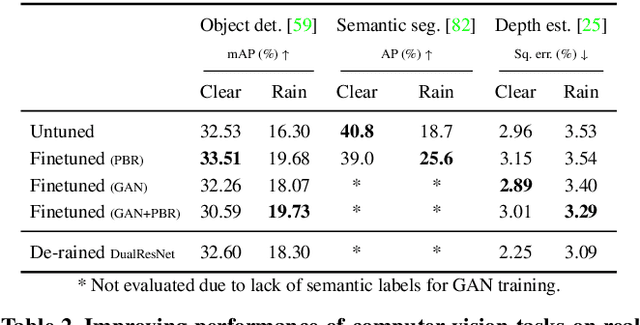
Rain fills the atmosphere with water particles, which breaks the common assumption that light travels unaltered from the scene to the camera. While it is well-known that rain affects computer vision algorithms, quantifying its impact is difficult. In this context, we present a rain rendering pipeline that enables the systematic evaluation of common computer vision algorithms to controlled amounts of rain. We present three different ways to add synthetic rain to existing images datasets: completely physic-based; completely data-driven; and a combination of both. The physic-based rain augmentation combines a physical particle simulator and accurate rain photometric modeling. We validate our rendering methods with a user study, demonstrating our rain is judged as much as 73% more realistic than the state-of-theart. Using our generated rain-augmented KITTI, Cityscapes, and nuScenes datasets, we conduct a thorough evaluation of object detection, semantic segmentation, and depth estimation algorithms and show that their performance decreases in degraded weather, on the order of 15% for object detection, 60% for semantic segmentation, and 6-fold increase in depth estimation error. Finetuning on our augmented synthetic data results in improvements of 21% on object detection, 37% on semantic segmentation, and 8% on depth estimation.