 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvenio: Discovering Hidden Relationships Between Tasks/Domains Using Structured Meta Learning
Nov 24, 2019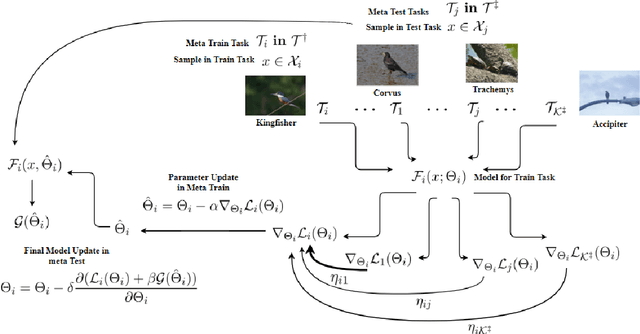
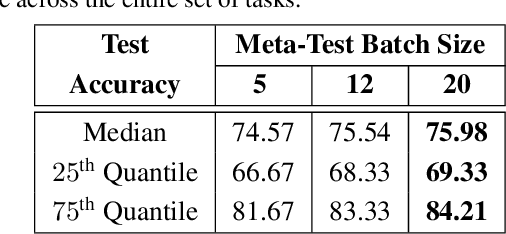

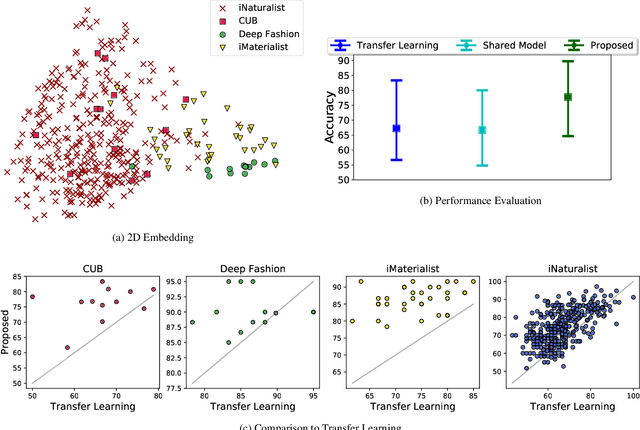
Exploiting known semantic relationships between fine-grained tasks is critical to the success of recent model agnostic approaches. These approaches often rely on meta-optimization to make a model robust to systematic task or domain shifts. However, in practice, the performance of these methods can suffer, when there are no coherent semantic relationships between the tasks (or domains). We present Invenio, a structured meta-learning algorithm to infer semantic similarities between a given set of tasks and to provide insights into the complexity of transferring knowledge between different tasks. In contrast to existing techniques such as Task2Vec and Taskonomy, which measure similarities between pre-trained models, our approach employs a novel self-supervised learning strategy to discover these relationships in the training loop and at the same time utilizes them to update task-specific models in the meta-update step. Using challenging task and domain databases, under few-shot learning settings, we show that Invenio can discover intricate dependencies between tasks or domains, and can provide significant gains over existing approaches in terms of generalization performance. The learned semantic structure between tasks/domains from Invenio is interpretable and can be used to construct meaningful priors for tasks or domains.
Heteroscedastic Calibration of Uncertainty Estimators in Deep Learning
Oct 30, 2019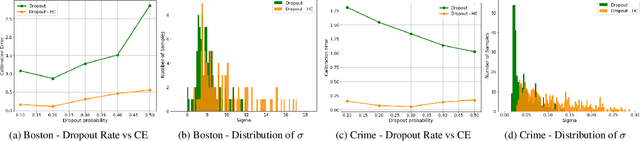
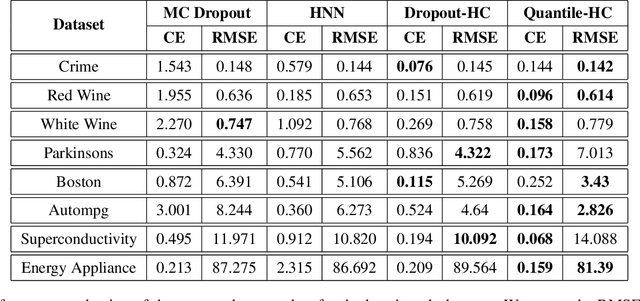
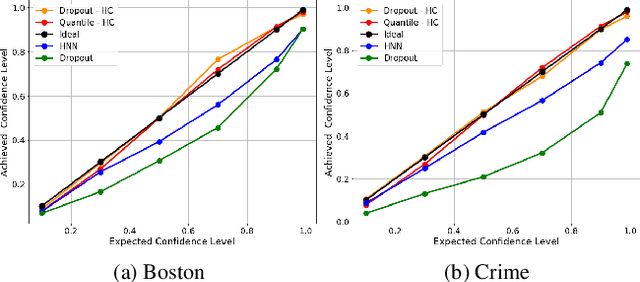
The role of uncertainty quantification (UQ) in deep learning has become crucial with growing use of predictive models in high-risk applications. Though a large class of methods exists for measuring deep uncertainties, in practice, the resulting estimates are found to be poorly calibrated, thus making it challenging to translate them into actionable insights. A common workaround is to utilize a separate recalibration step, which adjusts the estimates to compensate for the miscalibration. Instead, we propose to repurpose the heteroscedastic regression objective as a surrogate for calibration and enable any existing uncertainty estimator to be inherently calibrated. In addition to eliminating the need for recalibration, this also regularizes the training process. Using regression experiments, we demonstrate the effectiveness of the proposed heteroscedastic calibration with two popular uncertainty estimators.
Learn-By-Calibrating: Using Calibration as a Training Objective
Oct 30, 2019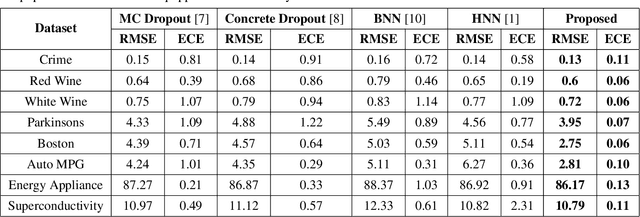
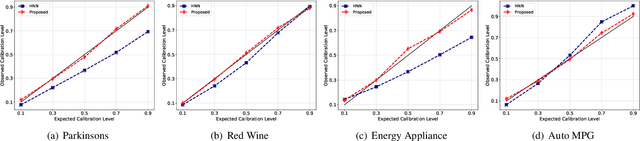
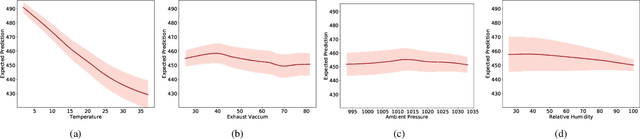
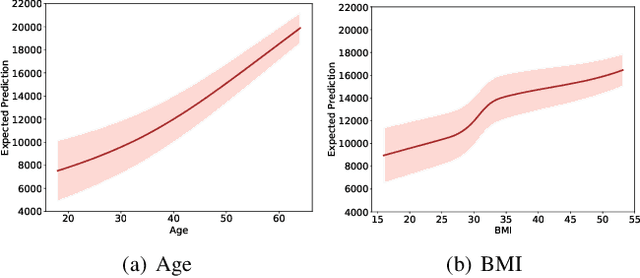
Calibration error is commonly adopted for evaluating the quality of uncertainty estimators in deep neural networks. In this paper, we argue that such a metric is highly beneficial for training predictive models, even when we do not explicitly measure the uncertainties. This is conceptually similar to heteroscedastic neural networks that produce variance estimates for each prediction, with the key difference that we do not place a Gaussian prior on the predictions. We propose a novel algorithm that performs simultaneous interval estimation for different calibration levels and effectively leverages the intervals to refine the mean estimates. Our results show that, our approach is consistently superior to existing regularization strategies in deep regression models. Finally, we propose to augment partial dependence plots, a model-agnostic interpretability tool, with expected prediction intervals to reveal interesting dependencies between data and the target.
Improving Limited Angle CT Reconstruction with a Robust GAN Prior
Oct 14, 2019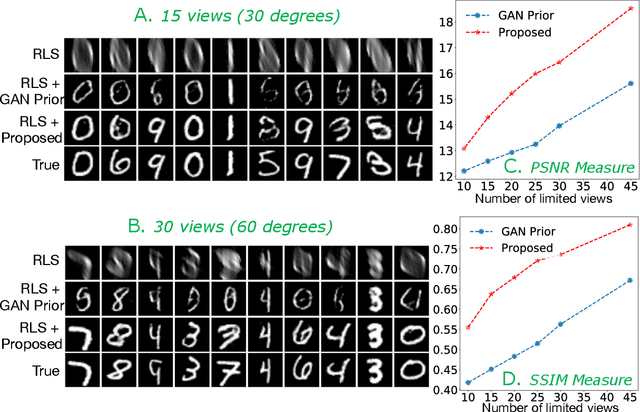
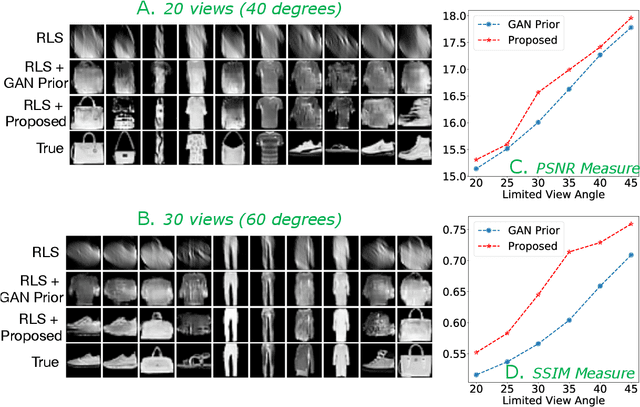
Limited angle CT reconstruction is an under-determined linear inverse problem that requires appropriate regularization techniques to be solved. In this work we study how pre-trained generative adversarial networks (GANs) can be used to clean noisy, highly artifact laden reconstructions from conventional techniques, by effectively projecting onto the inferred image manifold. In particular, we use a robust version of the popularly used GAN prior for inverse problems, based on a recent technique called corruption mimicking, that significantly improves the reconstruction quality. The proposed approach operates in the image space directly, as a result of which it does not need to be trained or require access to the measurement model, is scanner agnostic, and can work over a wide range of sensing scenarios.
Exploring Generative Physics Models with Scientific Priors in Inertial Confinement Fusion
Oct 03, 2019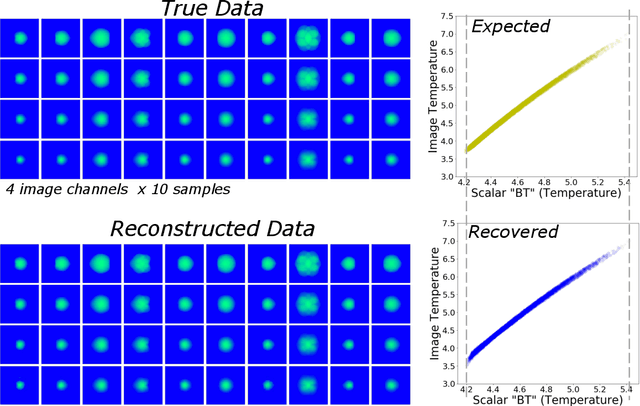
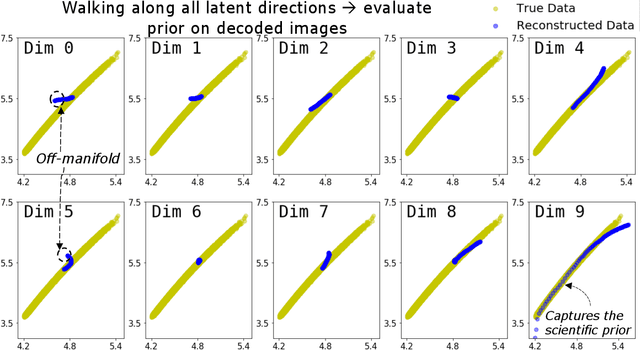
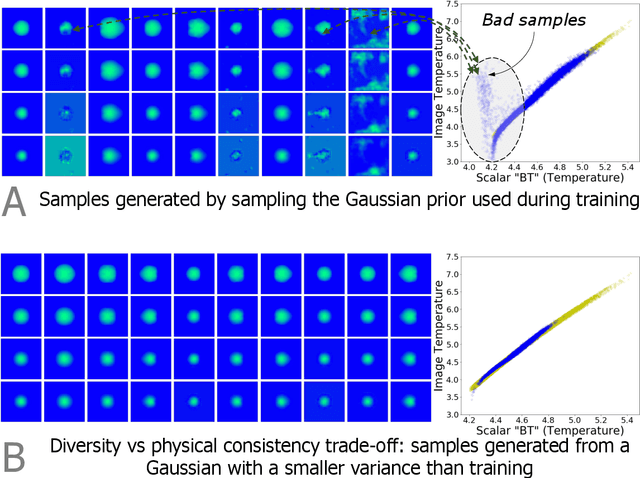
There is significant interest in using modern neural networks for scientific applications due to their effectiveness in modeling highly complex, non-linear problems in a data-driven fashion. However, a common challenge is to verify the scientific plausibility or validity of outputs predicted by a neural network. This work advocates the use of known scientific constraints as a lens into evaluating, exploring, and understanding such predictions for the problem of inertial confinement fusion.
Function Preserving Projection for Scalable Exploration of High-Dimensional Data
Sep 25, 2019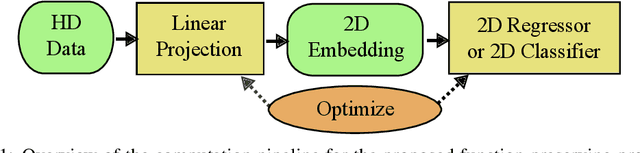
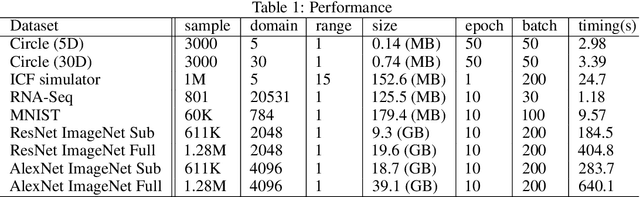
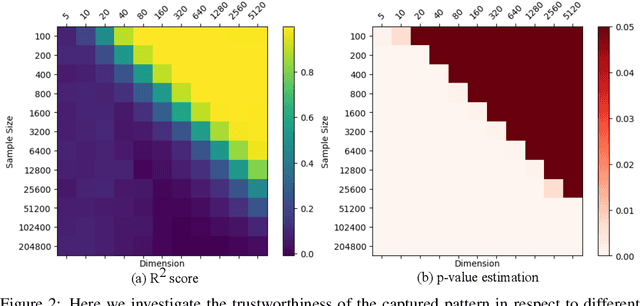
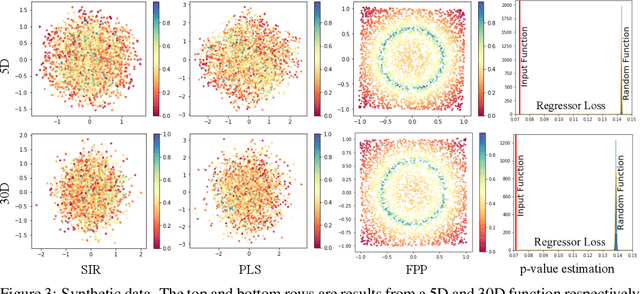
We present function preserving projections (FPP), a scalable linear projection technique for discovering interpretable relationships in high-dimensional data. Conventional dimension reduction methods aim to maximally preserve the global and/or local geometric structure of a dataset. However, in practice one is often more interested in determining how one or multiple user-selected response function(s) can be explained by the data. To intuitively connect the responses to the data, FPP constructs 2D linear embeddings optimized to reveal interpretable yet potentially non-linear patterns of the response functions. More specifically, FPP is designed to (i) produce human-interpretable embeddings; (ii) capture non-linear relationships; (iii) allow the simultaneous use of multiple response functions; and (iv) scale to millions of samples. Using FPP on real-world datasets, one can obtain fundamentally new insights about high-dimensional relationships in large-scale data that could not be achieved using existing dimension reduction methods.
Building Calibrated Deep Models via Uncertainty Matching with Auxiliary Interval Predictors
Sep 09, 2019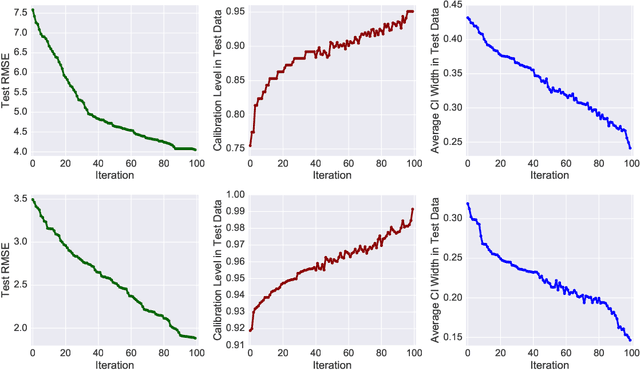
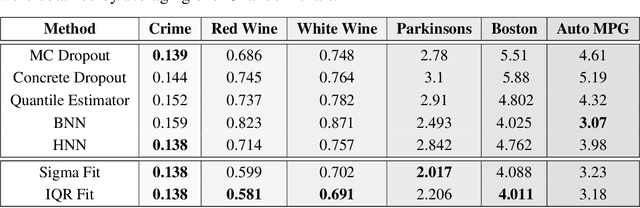
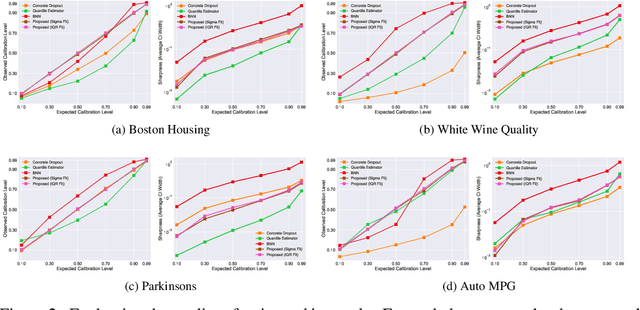
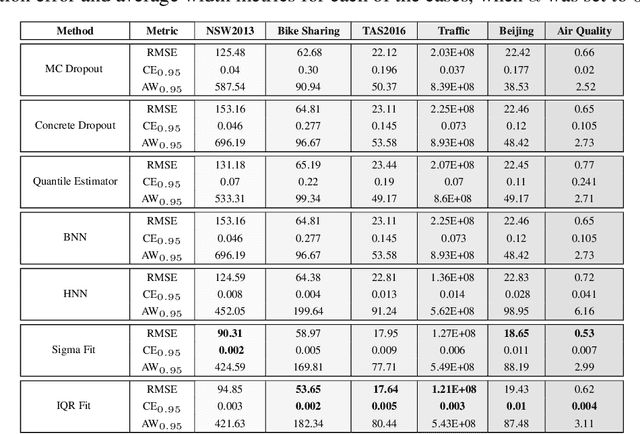
With rapid adoption of deep learning in high-regret applications, the question of when and how much to trust these models often arises, which drives the need to quantify the inherent uncertainties. While identifying all sources that account for the stochasticity of learned models is challenging, it is common to augment predictions with confidence intervals to convey the expected variations in a model's behavior. In general, we require confidence intervals to be well-calibrated, reflect the true uncertainties, and to be sharp. However, most existing techniques for obtaining confidence intervals are known to produce unsatisfactory results in terms of at least one of those criteria. To address this challenge, we develop a novel approach for building calibrated estimators. More specifically, we construct separate models for predicting the target variable, and for estimating the confidence intervals, and pose a bi-level optimization problem that allows the predictive model to leverage estimates from the interval estimator through an \textit{uncertainty matching} strategy. Using experiments in regression, time-series forecasting, and object localization, we show that our approach achieves significant improvements over existing uncertainty quantification methods, both in terms of model fidelity and calibration error.
Distill-to-Label: Weakly Supervised Instance Labeling Using Knowledge Distillation
Jul 26, 2019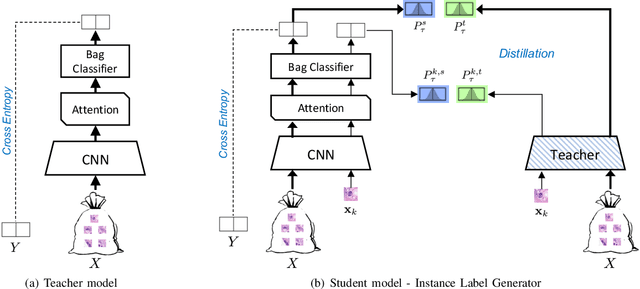
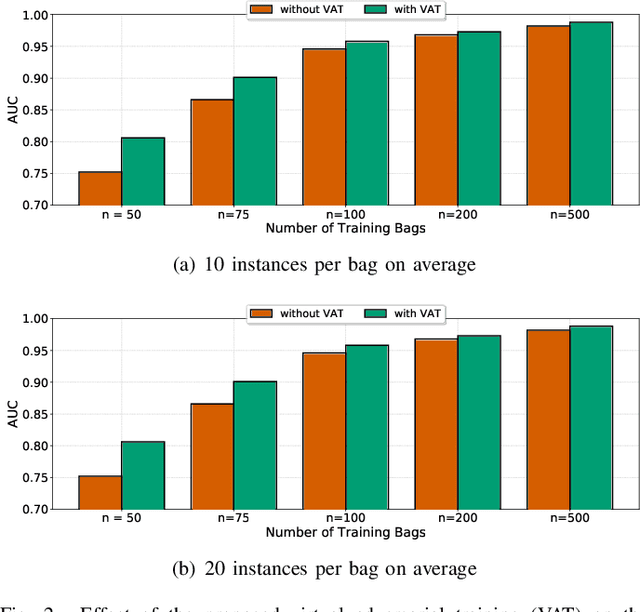
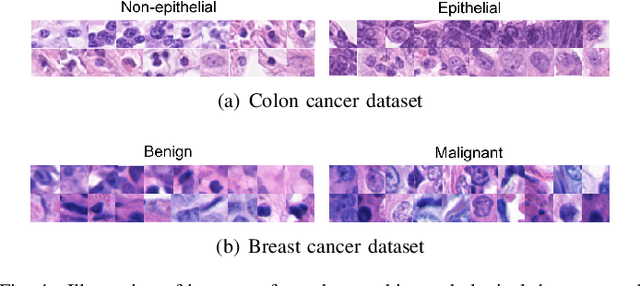
Weakly supervised instance labeling using only image-level labels, in lieu of expensive fine-grained pixel annotations, is crucial in several applications including medical image analysis. In contrast to conventional instance segmentation scenarios in computer vision, the problems that we consider are characterized by a small number of training images and non-local patterns that lead to the diagnosis. In this paper, we explore the use of multiple instance learning (MIL) to design an instance label generator under this weakly supervised setting. Motivated by the observation that an MIL model can handle bags of varying sizes, we propose to repurpose an MIL model originally trained for bag-level classification to produce reliable predictions for single instances, i.e., bags of size $1$. To this end, we introduce a novel regularization strategy based on virtual adversarial training for improving MIL training, and subsequently develop a knowledge distillation technique for repurposing the trained MIL model. Using empirical studies on colon cancer and breast cancer detection from histopathological images, we show that the proposed approach produces high-quality instance-level prediction and significantly outperforms state-of-the MIL methods.
Scalable Topological Data Analysis and Visualization for Evaluating Data-Driven Models in Scientific Applications
Jul 19, 2019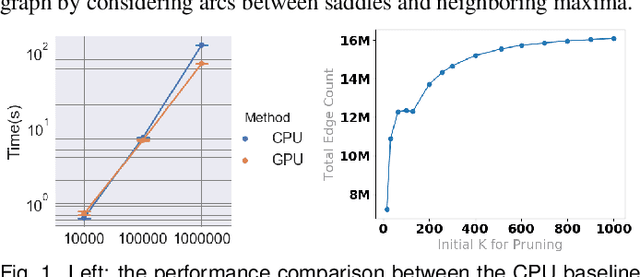
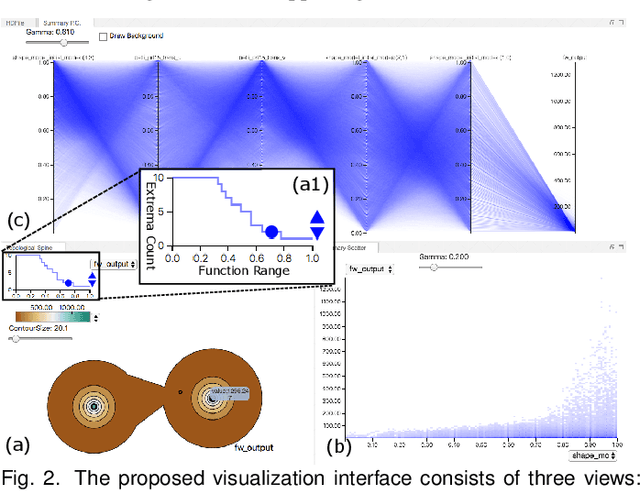
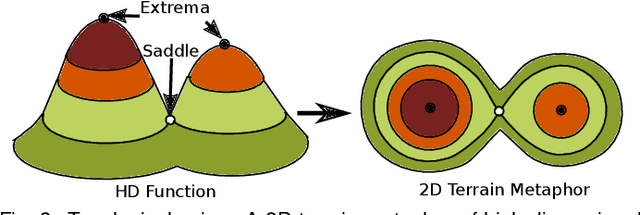
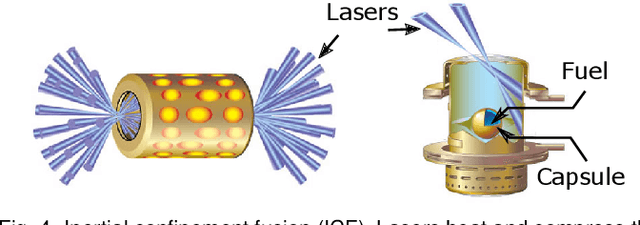
With the rapid adoption of machine learning techniques for large-scale applications in science and engineering comes the convergence of two grand challenges in visualization. First, the utilization of black box models (e.g., deep neural networks) calls for advanced techniques in exploring and interpreting model behaviors. Second, the rapid growth in computing has produced enormous datasets that require techniques that can handle millions or more samples. Although some solutions to these interpretability challenges have been proposed, they typically do not scale beyond thousands of samples, nor do they provide the high-level intuition scientists are looking for. Here, we present the first scalable solution to explore and analyze high-dimensional functions often encountered in the scientific data analysis pipeline. By combining a new streaming neighborhood graph construction, the corresponding topology computation, and a novel data aggregation scheme, namely topology aware datacubes, we enable interactive exploration of both the topological and the geometric aspect of high-dimensional data. Following two use cases from high-energy-density (HED) physics and computational biology, we demonstrate how these capabilities have led to crucial new insights in both applications.
SALT: Subspace Alignment as an Auxiliary Learning Task for Domain Adaptation
Jun 11, 2019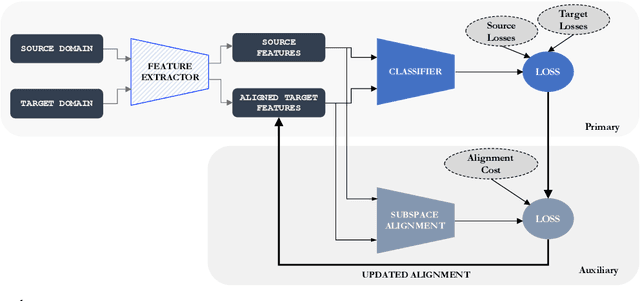
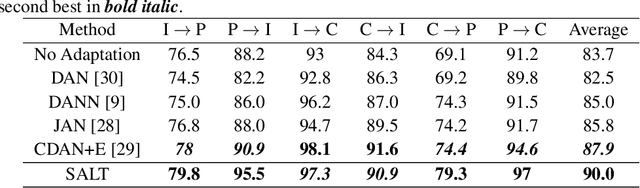
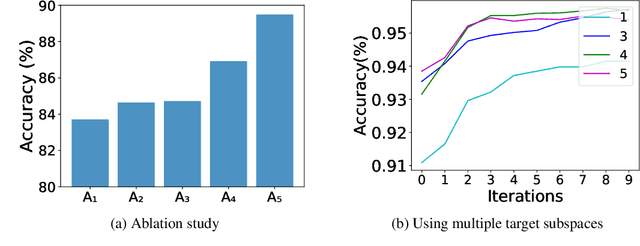
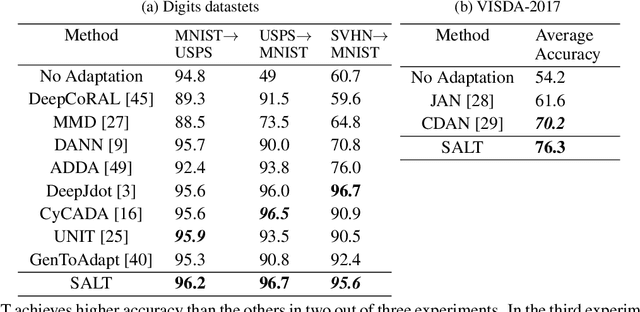
Unsupervised domain adaptation aims to transfer and adapt knowledge learned from a labeled source domain to an unlabeled target domain. Key components of unsupervised domain adaptation include: (a) maximizing performance on the source, and (b) aligning the source and target domains. Traditionally, these tasks have either been considered as separate, or assumed to be implicitly addressed together with high-capacity feature extractors. In this paper, we advance a third broad approach; which we term SALT. The core idea is to consider alignment as an auxiliary task to the primary task of maximizing performance on the source. The auxiliary task is made rather simple by assuming a tractable data geometry in the form of subspaces. We synergistically allow certain parameters derived from the closed-form auxiliary solution, to be affected by gradients from the primary task. The proposed approach represents a unique fusion of geometric and model-based alignment with gradient-flows from a data-driven primary task. SALT is simple, rooted in theory, and outperforms state-of-the-art on multiple standard benchmarks.