 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoiding a Tragedy of the Commons in the Peer Review Process
Dec 18, 2018
Peer review is the foundation of scientific publication, and the task of reviewing has long been seen as a cornerstone of professional service. However, the massive growth in the field of machine learning has put this community benefit under stress, threatening both the sustainability of an effective review process and the overall progress of the field. In this position paper, we argue that a tragedy of the commons outcome may be avoided by emphasizing the professional aspects of this service. In particular, we propose a rubric to hold reviewers to an objective standard for review quality. In turn, we also propose that reviewers be given appropriate incentive. As one possible such incentive, we explore the idea of financial compensation on a per-review basis. We suggest reasonable funding models and thoughts on long term effects.
Deep Bayesian Bandits Showdown: An Empirical Comparison of Bayesian Deep Networks for Thompson Sampling
Feb 26, 2018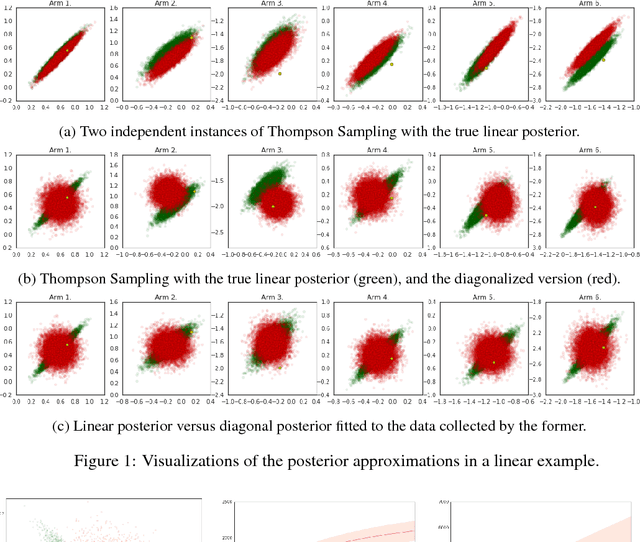
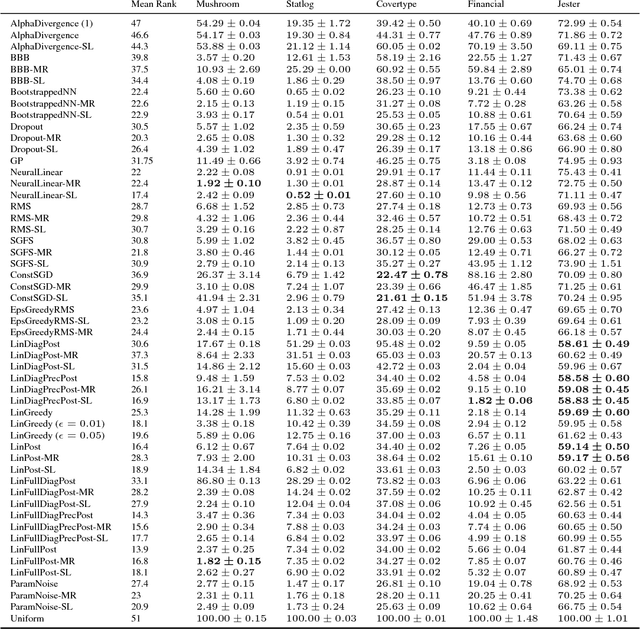
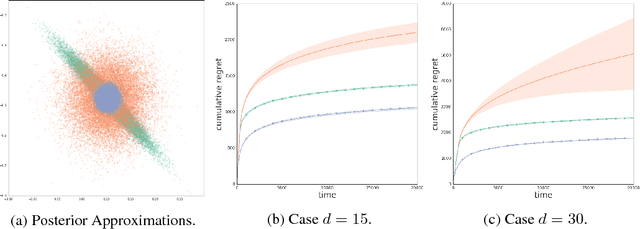

Recent advances in deep reinforcement learning have made significant strides in performance on applications such as Go and Atari games. However, developing practical methods to balance exploration and exploitation in complex domains remains largely unsolved. Thompson Sampling and its extension to reinforcement learning provide an elegant approach to exploration that only requires access to posterior samples of the model. At the same time, advances in approximate Bayesian methods have made posterior approximation for flexible neural network models practical. Thus, it is attractive to consider approximate Bayesian neural networks in a Thompson Sampling framework. To understand the impact of using an approximate posterior on Thompson Sampling, we benchmark well-established and recently developed methods for approximate posterior sampling combined with Thompson Sampling over a series of contextual bandit problems. We found that many approaches that have been successful in the supervised learning setting underperformed in the sequential decision-making scenario. In particular, we highlight the challenge of adapting slowly converging uncertainty estimates to the online setting.
Learning Latent Permutations with Gumbel-Sinkhorn Networks
Feb 23, 2018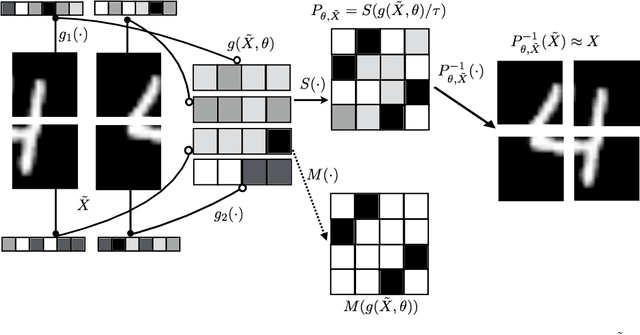
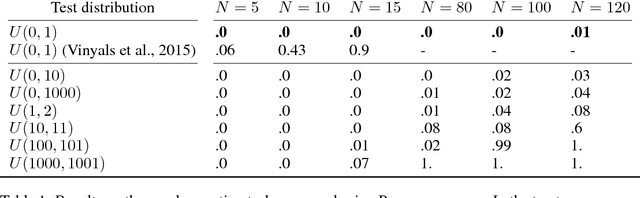
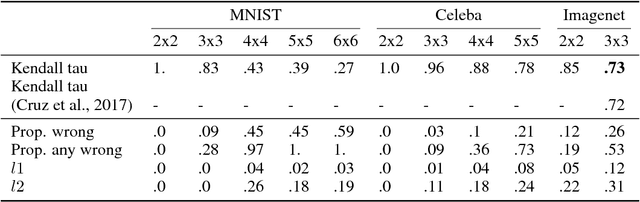

Permutations and matchings are core building blocks in a variety of latent variable models, as they allow us to align, canonicalize, and sort data. Learning in such models is difficult, however, because exact marginalization over these combinatorial objects is intractable. In response, this paper introduces a collection of new methods for end-to-end learning in such models that approximate discrete maximum-weight matching using the continuous Sinkhorn operator. Sinkhorn iteration is attractive because it functions as a simple, easy-to-implement analog of the softmax operator. With this, we can define the Gumbel-Sinkhorn method, an extension of the Gumbel-Softmax method (Jang et al. 2016, Maddison2016 et al. 2016) to distributions over latent matchings. We demonstrate the effectiveness of our method by outperforming competitive baselines on a range of qualitatively different tasks: sorting numbers, solving jigsaw puzzles, and identifying neural signals in worms.
Scalable Bayesian Optimization Using Deep Neural Networks
Jul 13, 2015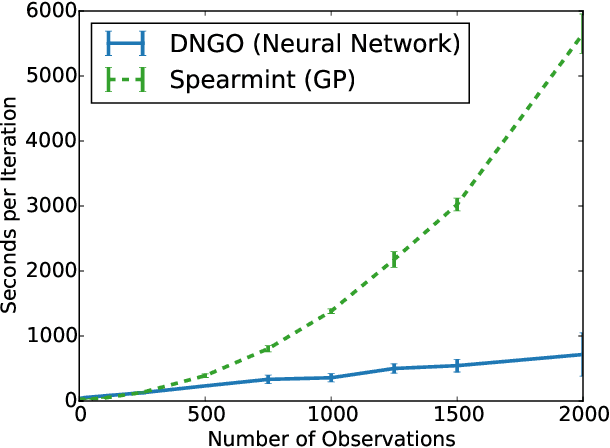
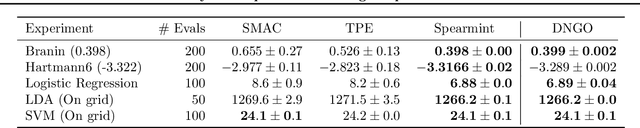
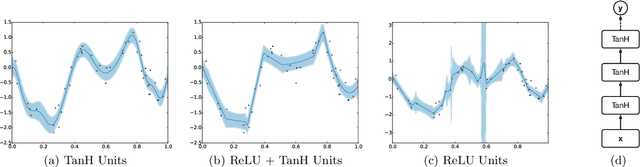

Bayesian optimization is an effective methodology for the global optimization of functions with expensive evaluations. It relies on querying a distribution over functions defined by a relatively cheap surrogate model. An accurate model for this distribution over functions is critical to the effectiveness of the approach, and is typically fit using Gaussian processes (GPs). However, since GPs scale cubically with the number of observations, it has been challenging to handle objectives whose optimization requires many evaluations, and as such, massively parallelizing the optimization. In this work, we explore the use of neural networks as an alternative to GPs to model distributions over functions. We show that performing adaptive basis function regression with a neural network as the parametric form performs competitively with state-of-the-art GP-based approaches, but scales linearly with the number of data rather than cubically. This allows us to achieve a previously intractable degree of parallelism, which we apply to large scale hyperparameter optimization, rapidly finding competitive models on benchmark object recognition tasks using convolutional networks, and image caption generation using neural language models.
Spectral Representations for Convolutional Neural Networks
Jun 11, 2015
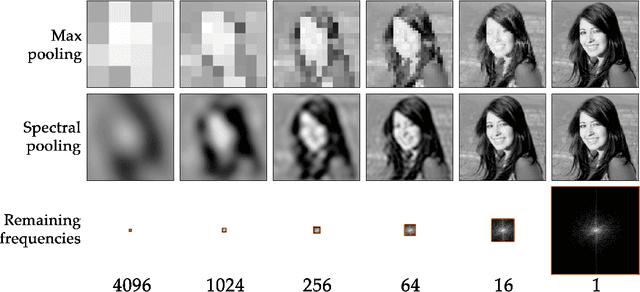

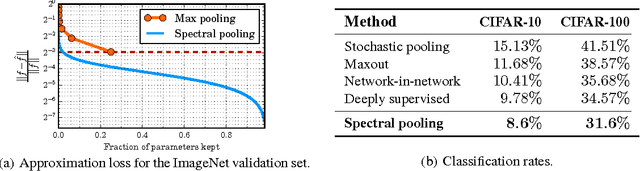
Discrete Fourier transforms provide a significant speedup in the computation of convolutions in deep learning. In this work, we demonstrate that, beyond its advantages for efficient computation, the spectral domain also provides a powerful representation in which to model and train convolutional neural networks (CNNs). We employ spectral representations to introduce a number of innovations to CNN design. First, we propose spectral pooling, which performs dimensionality reduction by truncating the representation in the frequency domain. This approach preserves considerably more information per parameter than other pooling strategies and enables flexibility in the choice of pooling output dimensionality. This representation also enables a new form of stochastic regularization by randomized modification of resolution. We show that these methods achieve competitive results on classification and approximation tasks, without using any dropout or max-pooling. Finally, we demonstrate the effectiveness of complex-coefficient spectral parameterization of convolutional filters. While this leaves the underlying model unchanged, it results in a representation that greatly facilitates optimization. We observe on a variety of popular CNN configurations that this leads to significantly faster convergence during training.
Raiders of the Lost Architecture: Kernels for Bayesian Optimization in Conditional Parameter Spaces
Sep 14, 2014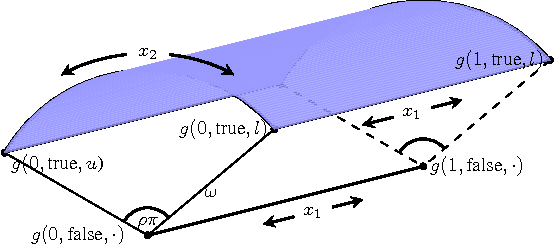

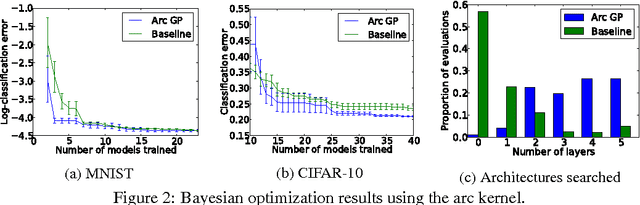
In practical Bayesian optimization, we must often search over structures with differing numbers of parameters. For instance, we may wish to search over neural network architectures with an unknown number of layers. To relate performance data gathered for different architectures, we define a new kernel for conditional parameter spaces that explicitly includes information about which parameters are relevant in a given structure. We show that this kernel improves model quality and Bayesian optimization results over several simpler baseline kernels.
Freeze-Thaw Bayesian Optimization
Jun 16, 2014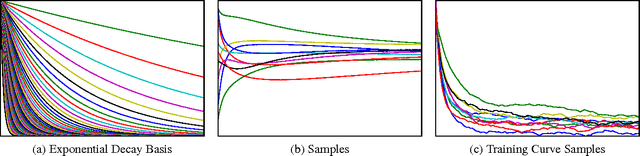
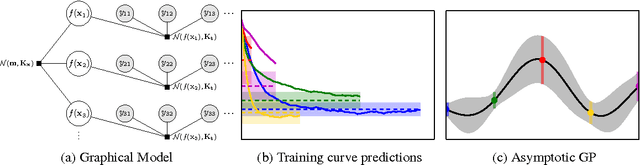
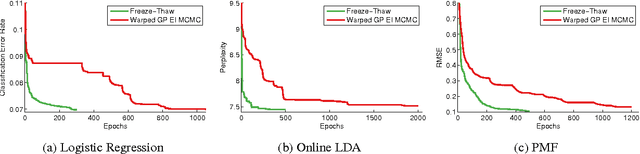
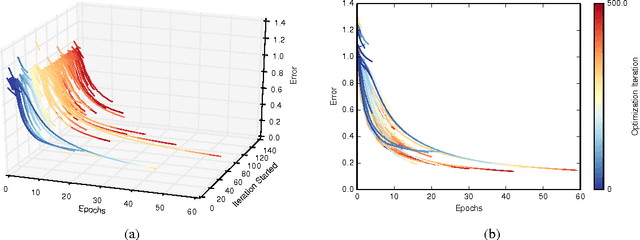
In this paper we develop a dynamic form of Bayesian optimization for machine learning models with the goal of rapidly finding good hyperparameter settings. Our method uses the partial information gained during the training of a machine learning model in order to decide whether to pause training and start a new model, or resume the training of a previously-considered model. We specifically tailor our method to machine learning problems by developing a novel positive-definite covariance kernel to capture a variety of training curves. Furthermore, we develop a Gaussian process prior that scales gracefully with additional temporal observations. Finally, we provide an information-theoretic framework to automate the decision process. Experiments on several common machine learning models show that our approach is extremely effective in practice.
Input Warping for Bayesian Optimization of Non-stationary Functions
Jun 11, 2014


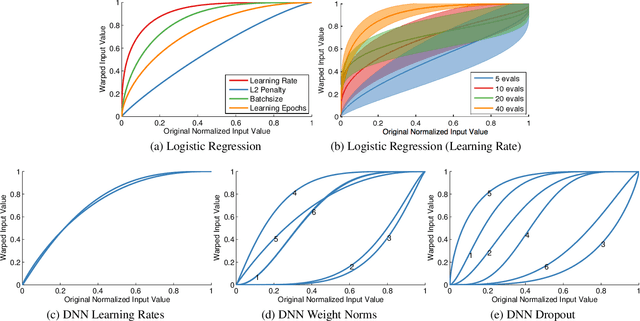
Bayesian optimization has proven to be a highly effective methodology for the global optimization of unknown, expensive and multimodal functions. The ability to accurately model distributions over functions is critical to the effectiveness of Bayesian optimization. Although Gaussian processes provide a flexible prior over functions which can be queried efficiently, there are various classes of functions that remain difficult to model. One of the most frequently occurring of these is the class of non-stationary functions. The optimization of the hyperparameters of machine learning algorithms is a problem domain in which parameters are often manually transformed a priori, for example by optimizing in "log-space," to mitigate the effects of spatially-varying length scale. We develop a methodology for automatically learning a wide family of bijective transformations or warpings of the input space using the Beta cumulative distribution function. We further extend the warping framework to multi-task Bayesian optimization so that multiple tasks can be warped into a jointly stationary space. On a set of challenging benchmark optimization tasks, we observe that the inclusion of warping greatly improves on the state-of-the-art, producing better results faster and more reliably.
Bayesian Optimization with Unknown Constraints
Mar 22, 2014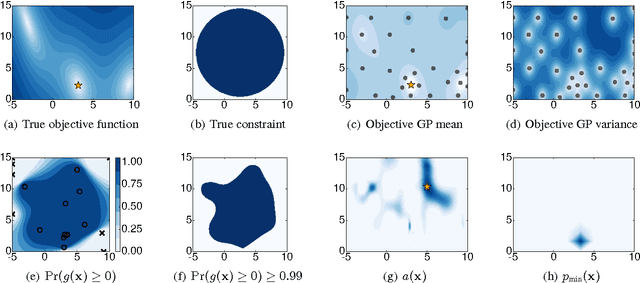

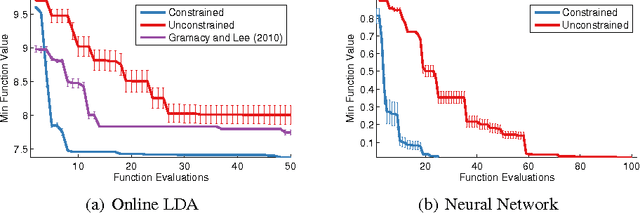
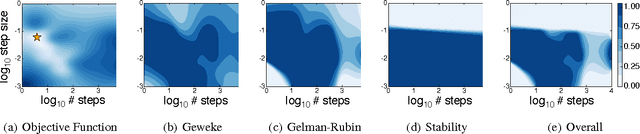
Recent work on Bayesian optimization has shown its effectiveness in global optimization of difficult black-box objective functions. Many real-world optimization problems of interest also have constraints which are unknown a priori. In this paper, we study Bayesian optimization for constrained problems in the general case that noise may be present in the constraint functions, and the objective and constraints may be evaluated independently. We provide motivating practical examples, and present a general framework to solve such problems. We demonstrate the effectiveness of our approach on optimizing the performance of online latent Dirichlet allocation subject to topic sparsity constraints, tuning a neural network given test-time memory constraints, and optimizing Hamiltonian Monte Carlo to achieve maximal effectiveness in a fixed time, subject to passing standard convergence diagnostics.
Practical Bayesian Optimization of Machine Learning Algorithms
Aug 29, 2012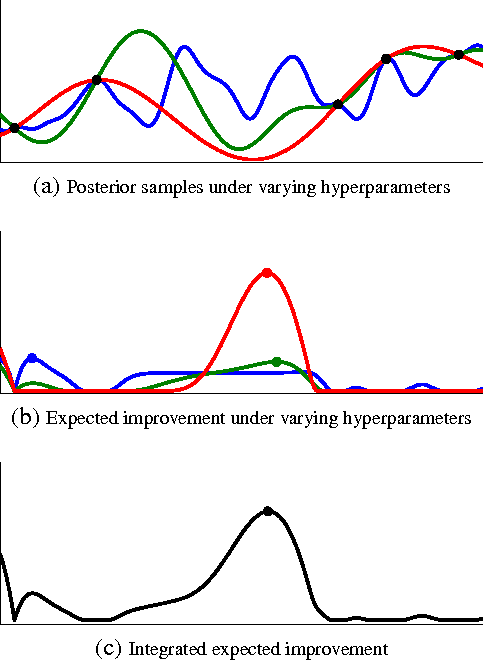
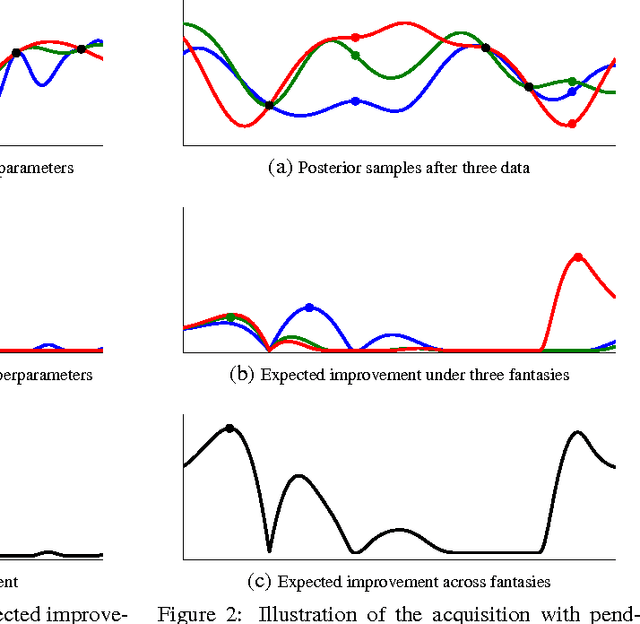
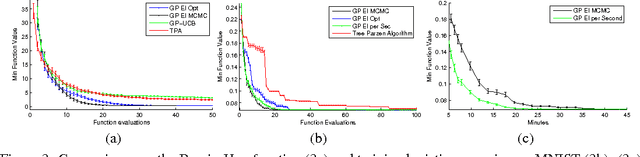
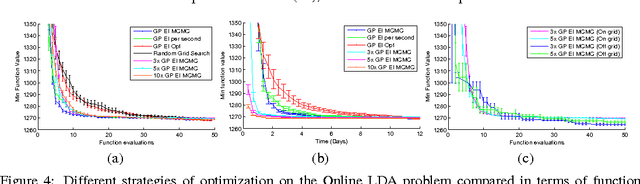
Machine learning algorithms frequently require careful tuning of model hyperparameters, regularization terms, and optimization parameters. Unfortunately, this tuning is often a "black art" that requires expert experience, unwritten rules of thumb, or sometimes brute-force search. Much more appealing is the idea of developing automatic approaches which can optimize the performance of a given learning algorithm to the task at hand. In this work, we consider the automatic tuning problem within the framework of Bayesian optimization, in which a learning algorithm's generalization performance is modeled as a sample from a Gaussian process (GP). The tractable posterior distribution induced by the GP leads to efficient use of the information gathered by previous experiments, enabling optimal choices about what parameters to try next. Here we show how the effects of the Gaussian process prior and the associated inference procedure can have a large impact on the success or failure of Bayesian optimization. We show that thoughtful choices can lead to results that exceed expert-level performance in tuning machine learning algorithms. We also describe new algorithms that take into account the variable cost (duration) of learning experiments and that can leverage the presence of multiple cores for parallel experimentation. We show that these proposed algorithms improve on previous automatic procedures and can reach or surpass human expert-level optimization on a diverse set of contemporary algorithms including latent Dirichlet allocation, structured SVMs and convolutional neural networks.