 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Translation System Selection from Bandit Feedback
Feb 22, 2020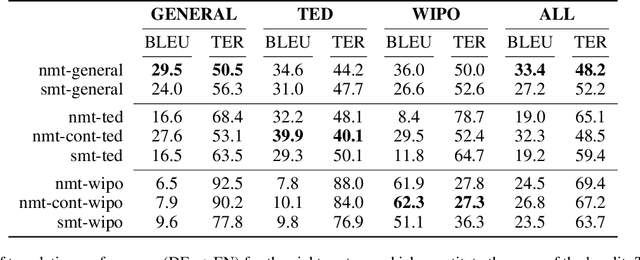
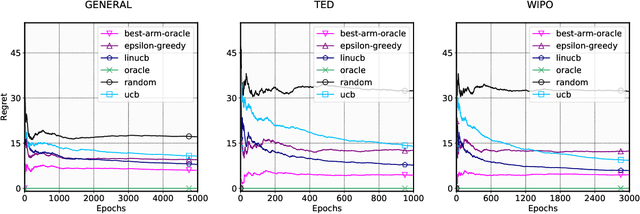
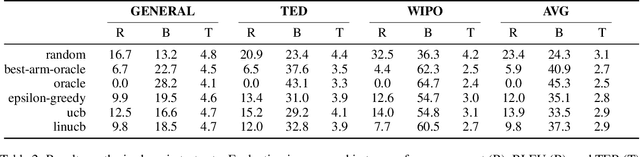
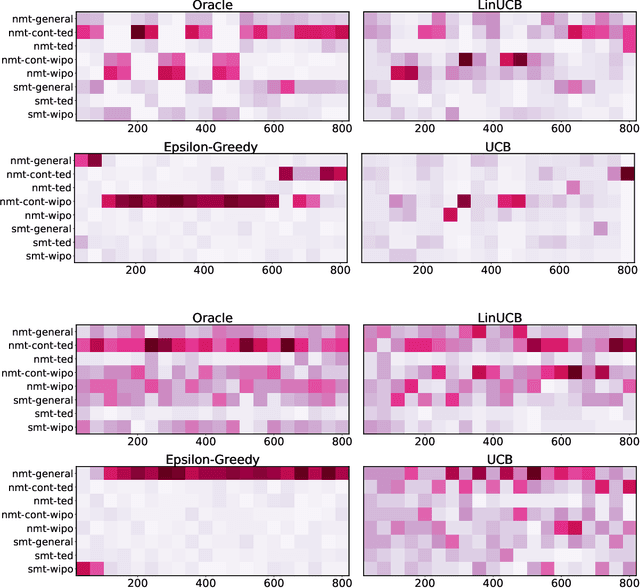
Adapting machine translation systems in the real world is a difficult problem. In contrast to offline training, users cannot provide the type of fine-grained feedback typically used for improving the system. Moreover, users have different translation needs, and even a single user's needs may change over time. In this work we take a different approach, treating the problem of adapting as one of selection. Instead of adapting a single system, we train many translation systems using different architectures and data partitions. Using bandit learning techniques on simulated user feedback, we learn a policy to choose which system to use for a particular translation task. We show that our approach can (1) quickly adapt to address domain changes in translation tasks, (2) outperform the single best system in mixed-domain translation tasks, and (3) make effective instance-specific decisions when using contextual bandit strategies.
Emergent Communication with World Models
Feb 22, 2020

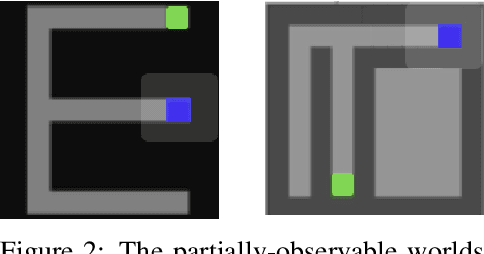
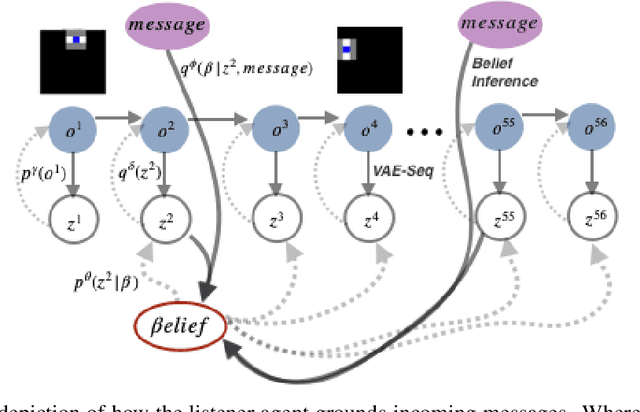
We introduce Language World Models, a class of language-conditional generative model which interpret natural language messages by predicting latent codes of future observations. This provides a visual grounding of the message, similar to an enhanced observation of the world, which may include objects outside of the listening agent's field-of-view. We incorporate this "observation" into a persistent memory state, and allow the listening agent's policy to condition on it, akin to the relationship between memory and controller in a World Model. We show this improves effective communication and task success in 2D gridworld speaker-listener navigation tasks. In addition, we develop two losses framed specifically for our model-based formulation to promote positive signalling and positive listening. Finally, because messages are interpreted in a generative model, we can visualize the model beliefs to gain insight into how the communication channel is utilized.
Meta-learning Extractors for Music Source Separation
Feb 17, 2020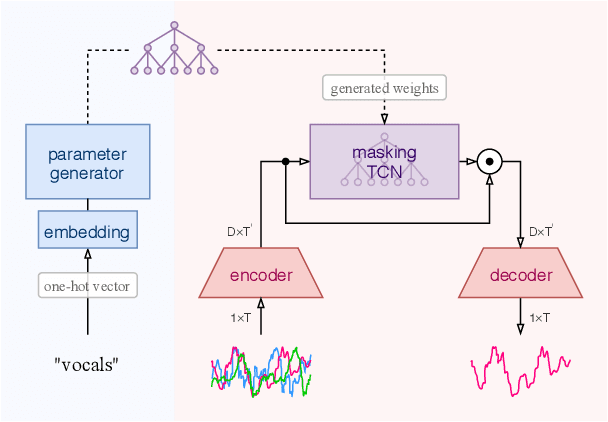
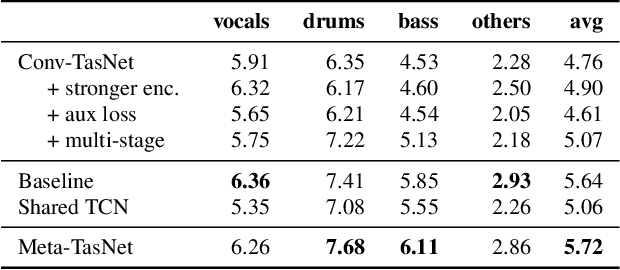
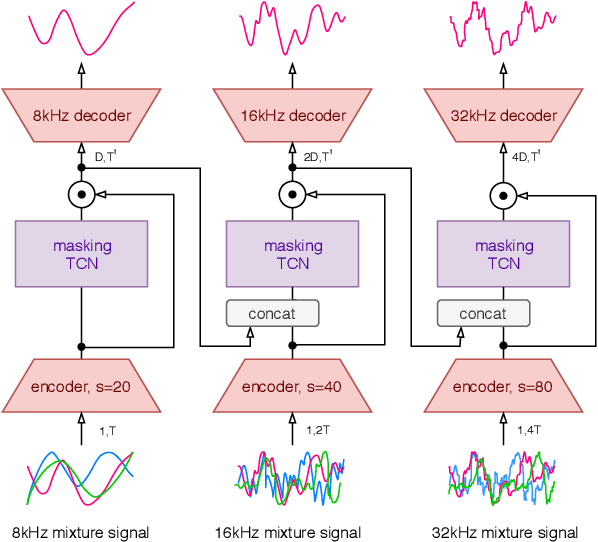
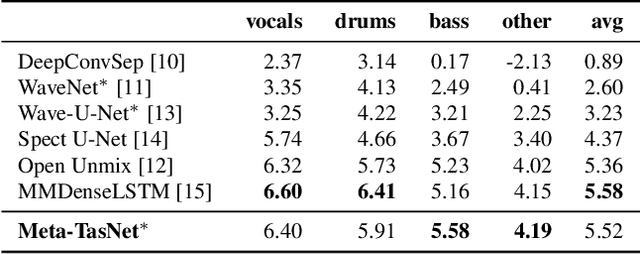
We propose a hierarchical meta-learning-inspired model for music source separation (Meta-TasNet) in which a generator model is used to predict the weights of individual extractor models. This enables efficient parameter-sharing, while still allowing for instrument-specific parameterization. Meta-TasNet is shown to be more effective than the models trained independently or in a multi-task setting, and achieve performance comparable with state-of-the-art methods. In comparison to the latter, our extractors contain fewer parameters and have faster run-time performance. We discuss important architectural considerations, and explore the costs and benefits of this approach.
A Structured Variational Autoencoder for Contextual Morphological Inflection
Jun 10, 2018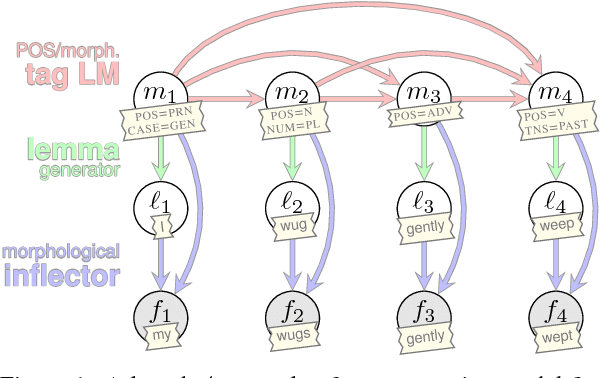

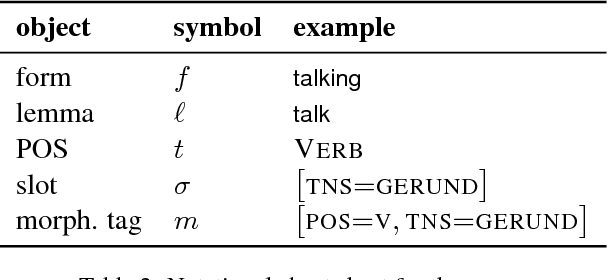
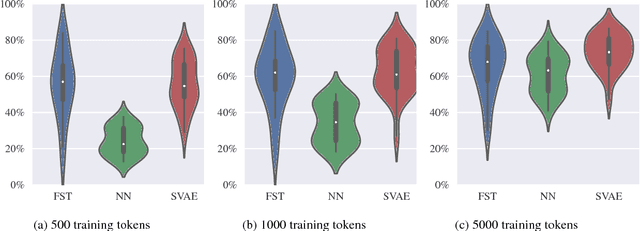
Statistical morphological inflectors are typically trained on fully supervised, type-level data. One remaining open research question is the following: How can we effectively exploit raw, token-level data to improve their performance? To this end, we introduce a novel generative latent-variable model for the semi-supervised learning of inflection generation. To enable posterior inference over the latent variables, we derive an efficient variational inference procedure based on the wake-sleep algorithm. We experiment on 23 languages, using the Universal Dependencies corpora in a simulated low-resource setting, and find improvements of over 10% absolute accuracy in some cases.
Hypothesis Only Baselines in Natural Language Inference
May 02, 2018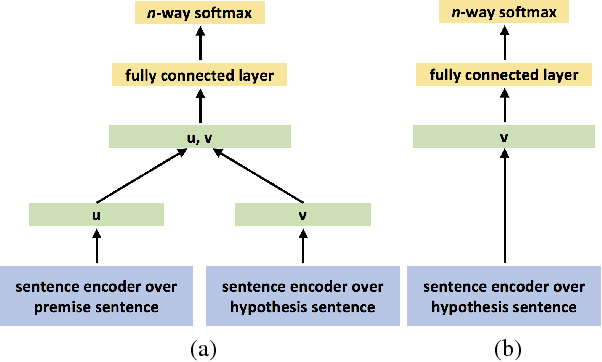
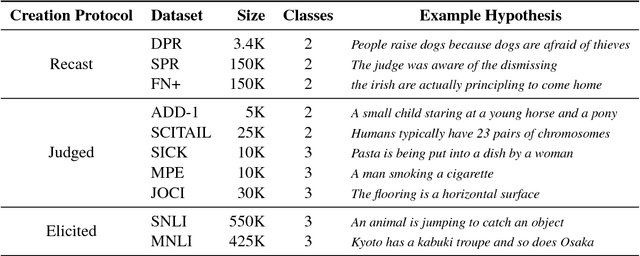
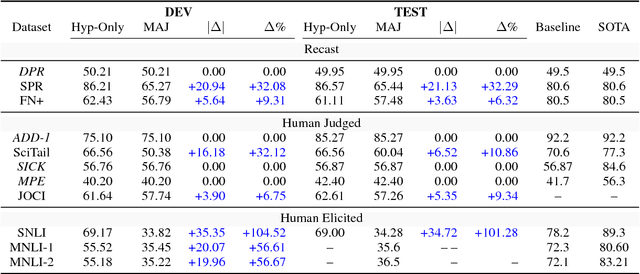
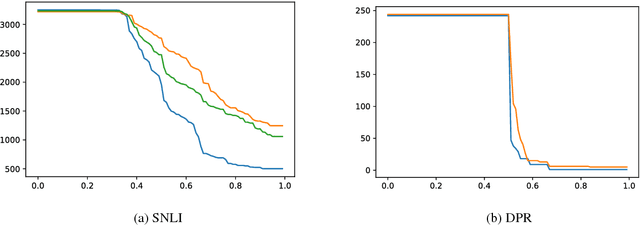
We propose a hypothesis only baseline for diagnosing Natural Language Inference (NLI). Especially when an NLI dataset assumes inference is occurring based purely on the relationship between a context and a hypothesis, it follows that assessing entailment relations while ignoring the provided context is a degenerate solution. Yet, through experiments on ten distinct NLI datasets, we find that this approach, which we refer to as a hypothesis-only model, is able to significantly outperform a majority class baseline across a number of NLI datasets. Our analysis suggests that statistical irregularities may allow a model to perform NLI in some datasets beyond what should be achievable without access to the context.
Gender Bias in Coreference Resolution
Apr 25, 2018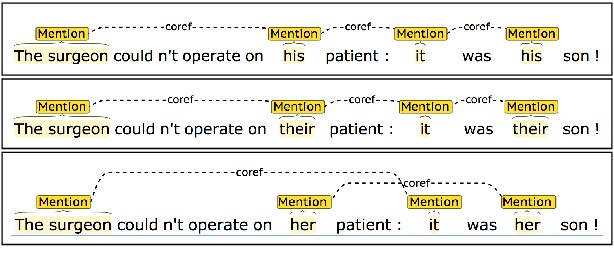
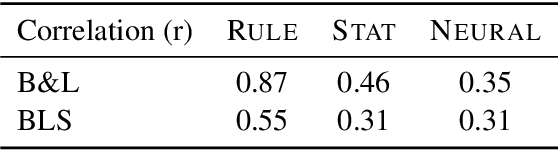


We present an empirical study of gender bias in coreference resolution systems. We first introduce a novel, Winograd schema-style set of minimal pair sentences that differ only by pronoun gender. With these "Winogender schemas," we evaluate and confirm systematic gender bias in three publicly-available coreference resolution systems, and correlate this bias with real-world and textual gender statistics.
Break it Down for Me: A Study in Automated Lyric Annotation
Aug 11, 2017



Comprehending lyrics, as found in songs and poems, can pose a challenge to human and machine readers alike. This motivates the need for systems that can understand the ambiguity and jargon found in such creative texts, and provide commentary to aid readers in reaching the correct interpretation. We introduce the task of automated lyric annotation (ALA). Like text simplification, a goal of ALA is to rephrase the original text in a more easily understandable manner. However, in ALA the system must often include additional information to clarify niche terminology and abstract concepts. To stimulate research on this task, we release a large collection of crowdsourced annotations for song lyrics. We analyze the performance of translation and retrieval models on this task, measuring performance with both automated and human evaluation. We find that each model captures a unique type of information important to the task.
Programming with a Differentiable Forth Interpreter
Jul 23, 2017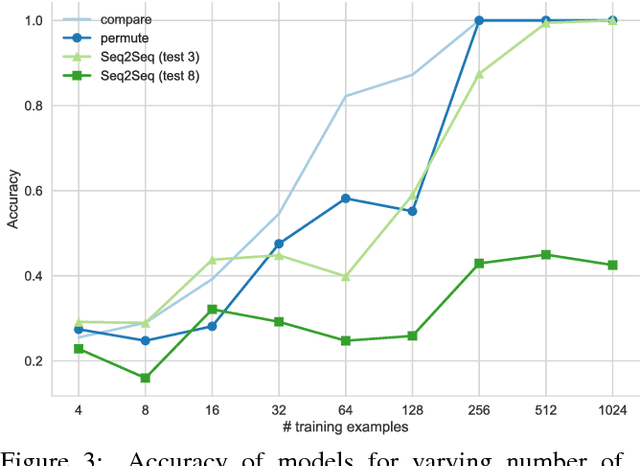
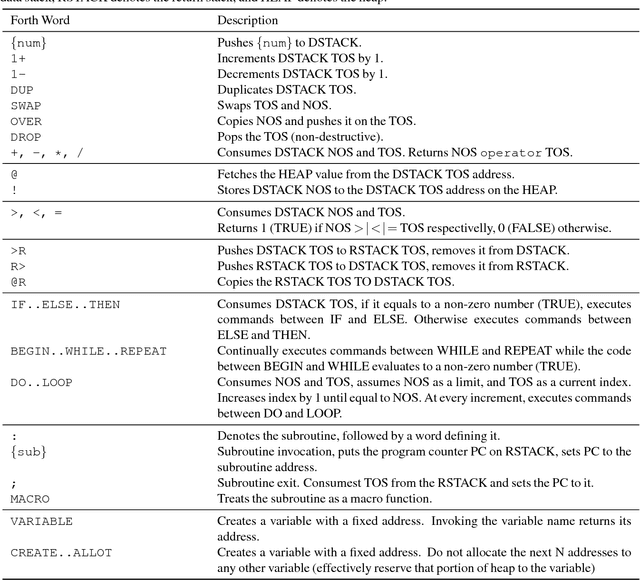
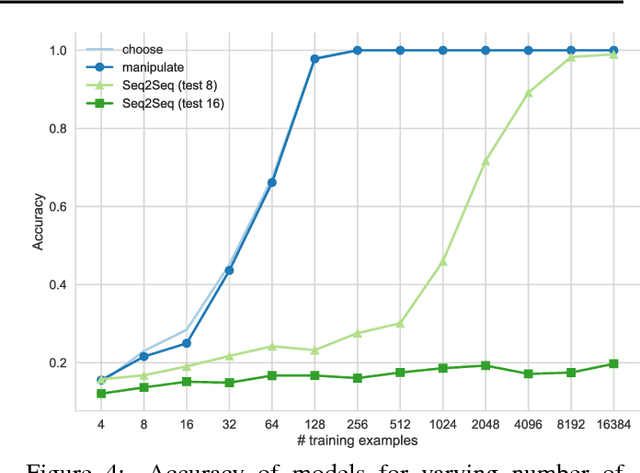
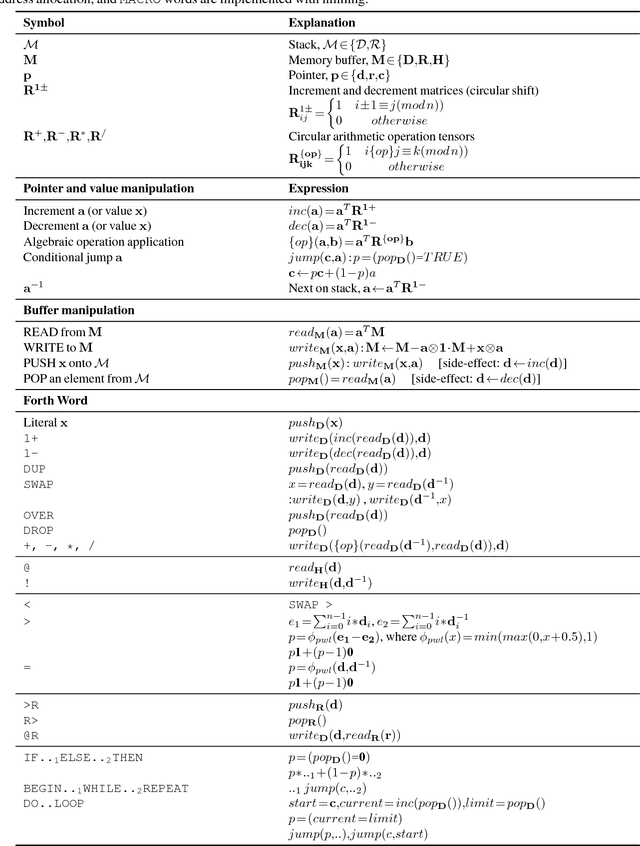
Given that in practice training data is scarce for all but a small set of problems, a core question is how to incorporate prior knowledge into a model. In this paper, we consider the case of prior procedural knowledge for neural networks, such as knowing how a program should traverse a sequence, but not what local actions should be performed at each step. To this end, we present an end-to-end differentiable interpreter for the programming language Forth which enables programmers to write program sketches with slots that can be filled with behaviour trained from program input-output data. We can optimise this behaviour directly through gradient descent techniques on user-specified objectives, and also integrate the program into any larger neural computation graph. We show empirically that our interpreter is able to effectively leverage different levels of prior program structure and learn complex behaviours such as sequence sorting and addition. When connected to outputs of an LSTM and trained jointly, our interpreter achieves state-of-the-art accuracy for end-to-end reasoning about quantities expressed in natural language stories.
Represent, Aggregate, and Constrain: A Novel Architecture for Machine Reading from Noisy Sources
Oct 30, 2016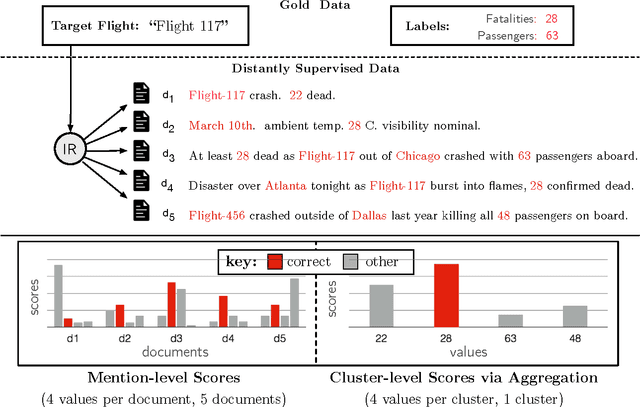
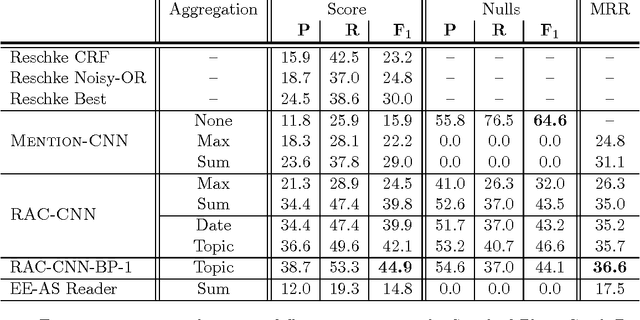
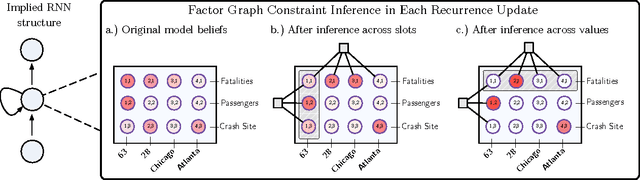
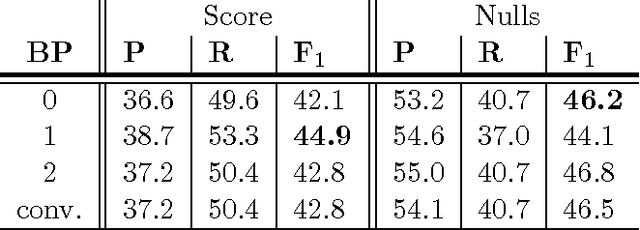
In order to extract event information from text, a machine reading model must learn to accurately read and interpret the ways in which that information is expressed. But it must also, as the human reader must, aggregate numerous individual value hypotheses into a single coherent global analysis, applying global constraints which reflect prior knowledge of the domain. In this work we focus on the task of extracting plane crash event information from clusters of related news articles whose labels are derived via distant supervision. Unlike previous machine reading work, we assume that while most target values will occur frequently in most clusters, they may also be missing or incorrect. We introduce a novel neural architecture to explicitly model the noisy nature of the data and to deal with these aforementioned learning issues. Our models are trained end-to-end and achieve an improvement of more than 12.1 F$_1$ over previous work, despite using far less linguistic annotation. We apply factor graph constraints to promote more coherent event analyses, with belief propagation inference formulated within the transitions of a recurrent neural network. We show this technique additionally improves maximum F$_1$ by up to 2.8 points, resulting in a relative improvement of $50\%$ over the previous state-of-the-art.