 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProperly learning decision trees in almost polynomial time
Sep 01, 2021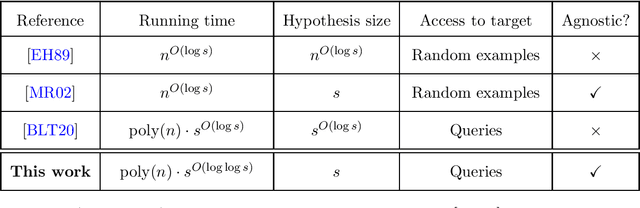


We give an $n^{O(\log\log n)}$-time membership query algorithm for properly and agnostically learning decision trees under the uniform distribution over $\{\pm 1\}^n$. Even in the realizable setting, the previous fastest runtime was $n^{O(\log n)}$, a consequence of a classic algorithm of Ehrenfeucht and Haussler. Our algorithm shares similarities with practical heuristics for learning decision trees, which we augment with additional ideas to circumvent known lower bounds against these heuristics. To analyze our algorithm, we prove a new structural result for decision trees that strengthens a theorem of O'Donnell, Saks, Schramm, and Servedio. While the OSSS theorem says that every decision tree has an influential variable, we show how every decision tree can be "pruned" so that every variable in the resulting tree is influential.
Decision tree heuristics can fail, even in the smoothed setting
Jul 02, 2021Greedy decision tree learning heuristics are mainstays of machine learning practice, but theoretical justification for their empirical success remains elusive. In fact, it has long been known that there are simple target functions for which they fail badly (Kearns and Mansour, STOC 1996). Recent work of Brutzkus, Daniely, and Malach (COLT 2020) considered the smoothed analysis model as a possible avenue towards resolving this disconnect. Within the smoothed setting and for targets $f$ that are $k$-juntas, they showed that these heuristics successfully learn $f$ with depth-$k$ decision tree hypotheses. They conjectured that the same guarantee holds more generally for targets that are depth-$k$ decision trees. We provide a counterexample to this conjecture: we construct targets that are depth-$k$ decision trees and show that even in the smoothed setting, these heuristics build trees of depth $2^{\Omega(k)}$ before achieving high accuracy. We also show that the guarantees of Brutzkus et al. cannot extend to the agnostic setting: there are targets that are very close to $k$-juntas, for which these heuristics build trees of depth $2^{\Omega(k)}$ before achieving high accuracy.
Learning stochastic decision trees
May 08, 2021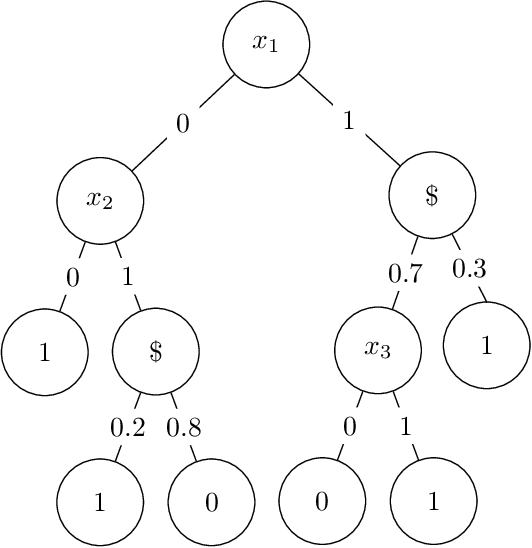
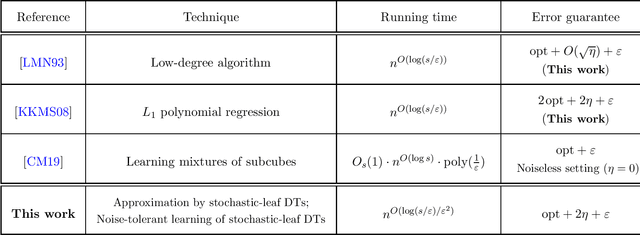

We give a quasipolynomial-time algorithm for learning stochastic decision trees that is optimally resilient to adversarial noise. Given an $\eta$-corrupted set of uniform random samples labeled by a size-$s$ stochastic decision tree, our algorithm runs in time $n^{O(\log(s/\varepsilon)/\varepsilon^2)}$ and returns a hypothesis with error within an additive $2\eta + \varepsilon$ of the Bayes optimal. An additive $2\eta$ is the information-theoretic minimum. Previously no non-trivial algorithm with a guarantee of $O(\eta) + \varepsilon$ was known, even for weaker noise models. Our algorithm is furthermore proper, returning a hypothesis that is itself a decision tree; previously no such algorithm was known even in the noiseless setting.
Testing and reconstruction via decision trees
Dec 16, 2020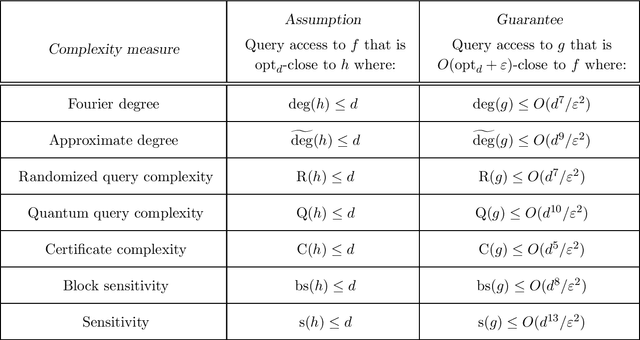


We study sublinear and local computation algorithms for decision trees, focusing on testing and reconstruction. Our first result is a tester that runs in $\mathrm{poly}(\log s, 1/\varepsilon)\cdot n\log n$ time, makes $\mathrm{poly}(\log s,1/\varepsilon)\cdot \log n$ queries to an unknown function $f$, and: $\circ$ Accepts if $f$ is $\varepsilon$-close to a size-$s$ decision tree; $\circ$ Rejects if $f$ is $\Omega(\varepsilon)$-far from decision trees of size $s^{\tilde{O}((\log s)^2/\varepsilon^2)}$. Existing testers distinguish size-$s$ decision trees from those that are $\varepsilon$-far from from size-$s$ decision trees in $\mathrm{poly}(s^s,1/\varepsilon)\cdot n$ time with $\tilde{O}(s/\varepsilon)$ queries. We therefore solve an incomparable problem, but achieve doubly-exponential-in-$s$ and exponential-in-$s$ improvements in time and query complexities respectively. We obtain our tester by designing a reconstruction algorithm for decision trees: given query access to a function $f$ that is close to a small decision tree, this algorithm provides fast query access to a small decision tree that is close to $f$. By known relationships, our results yield reconstruction algorithms for numerous other boolean function properties -- Fourier degree, randomized and quantum query complexities, certificate complexity, sensitivity, etc. -- which in turn yield new testers for these properties. Finally, we give a hardness result for testing whether an unknown function is $\varepsilon$-close-to or $\Omega(\varepsilon)$-far-from size-$s$ decision trees. We show that an efficient algorithm for this task would yield an efficient algorithm for properly learning decision trees, a central open problem of learning theory. It has long been known that proper learning algorithms for any class $\mathcal{H}$ yield property testers for $\mathcal{H}$; this provides an example of a converse.
Estimating decision tree learnability with polylogarithmic sample complexity
Nov 03, 2020
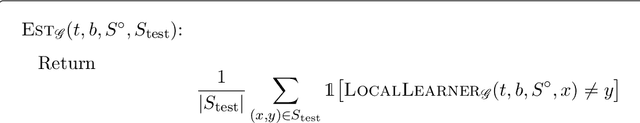
We show that top-down decision tree learning heuristics are amenable to highly efficient learnability estimation: for monotone target functions, the error of the decision tree hypothesis constructed by these heuristics can be estimated with polylogarithmically many labeled examples, exponentially smaller than the number necessary to run these heuristics, and indeed, exponentially smaller than information-theoretic minimum required to learn a good decision tree. This adds to a small but growing list of fundamental learning algorithms that have been shown to be amenable to learnability estimation. En route to this result, we design and analyze sample-efficient minibatch versions of top-down decision tree learning heuristics and show that they achieve the same provable guarantees as the full-batch versions. We further give "active local" versions of these heuristics: given a test point $x^\star$, we show how the label $T(x^\star)$ of the decision tree hypothesis $T$ can be computed with polylogarithmically many labeled examples, exponentially smaller than the number necessary to learn $T$.
Universal guarantees for decision tree induction via a higher-order splitting criterion
Oct 16, 2020We propose a simple extension of top-down decision tree learning heuristics such as ID3, C4.5, and CART. Our algorithm achieves provable guarantees for all target functions $f: \{-1,1\}^n \to \{-1,1\}$ with respect to the uniform distribution, circumventing impossibility results showing that existing heuristics fare poorly even for simple target functions. The crux of our extension is a new splitting criterion that takes into account the correlations between $f$ and small subsets of its attributes. The splitting criteria of existing heuristics (e.g. Gini impurity and information gain), in contrast, are based solely on the correlations between $f$ and its individual attributes. Our algorithm satisfies the following guarantee: for all target functions $f : \{-1,1\}^n \to \{-1,1\}$, sizes $s\in \mathbb{N}$, and error parameters $\epsilon$, it constructs a decision tree of size $s^{\tilde{O}((\log s)^2/\epsilon^2)}$ that achieves error $\le O(\mathsf{opt}_s) + \epsilon$, where $\mathsf{opt}_s$ denotes the error of the optimal size $s$ decision tree. A key technical notion that drives our analysis is the noise stability of $f$, a well-studied smoothness measure.
Provable guarantees for decision tree induction: the agnostic setting
Jun 01, 2020

We give strengthened provable guarantees on the performance of widely employed and empirically successful {\sl top-down decision tree learning heuristics}. While prior works have focused on the realizable setting, we consider the more realistic and challenging {\sl agnostic} setting. We show that for all monotone functions~$f$ and parameters $s\in \mathbb{N}$, these heuristics construct a decision tree of size $s^{\tilde{O}((\log s)/\varepsilon^2)}$ that achieves error $\le \mathsf{opt}_s + \varepsilon$, where $\mathsf{opt}_s$ denotes the error of the optimal size-$s$ decision tree for $f$. Previously, such a guarantee was not known to be achievable by any algorithm, even one that is not based on top-down heuristics. We complement our algorithmic guarantee with a near-matching $s^{\tilde{\Omega}(\log s)}$ lower bound.
Top-down induction of decision trees: rigorous guarantees and inherent limitations
Nov 18, 2019
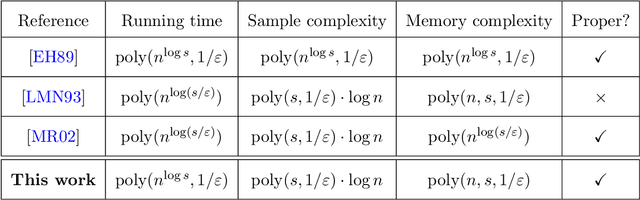
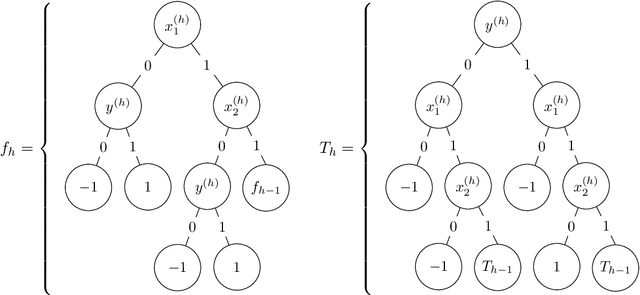
Consider the following heuristic for building a decision tree for a function $f : \{0,1\}^n \to \{\pm 1\}$. Place the most influential variable $x_i$ of $f$ at the root, and recurse on the subfunctions $f_{x_i=0}$ and $f_{x_i=1}$ on the left and right subtrees respectively; terminate once the tree is an $\varepsilon$-approximation of $f$. We analyze the quality of this heuristic, obtaining near-matching upper and lower bounds: $\circ$ Upper bound: For every $f$ with decision tree size $s$ and every $\varepsilon \in (0,\frac1{2})$, this heuristic builds a decision tree of size at most $s^{O(\log(s/\varepsilon)\log(1/\varepsilon))}$. $\circ$ Lower bound: For every $\varepsilon \in (0,\frac1{2})$ and $s \le 2^{\tilde{O}(\sqrt{n})}$, there is an $f$ with decision tree size $s$ such that this heuristic builds a decision tree of size $s^{\tilde{\Omega}(\log s)}$. We also obtain upper and lower bounds for monotone functions: $s^{O(\sqrt{\log s}/\varepsilon)}$ and $s^{\tilde{\Omega}(\sqrt[4]{\log s } )}$ respectively. The lower bound disproves conjectures of Fiat and Pechyony (2004) and Lee (2009). Our upper bounds yield new algorithms for properly learning decision trees under the uniform distribution. We show that these algorithms---which are motivated by widely employed and empirically successful top-down decision tree learning heuristics such as ID3, C4.5, and CART---achieve provable guarantees that compare favorably with those of the current fastest algorithm (Ehrenfeucht and Haussler, 1989). Our lower bounds shed new light on the limitations of these heuristics. Finally, we revisit the classic work of Ehrenfeucht and Haussler. We extend it to give the first uniform-distribution proper learning algorithm that achieves polynomial sample and memory complexity, while matching its state-of-the-art quasipolynomial runtime.