 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractalBench: Diagnosing Visual-Mathematical Reasoning Through Recursive Program Synthesis
Nov 09, 2025Mathematical reasoning requires abstracting symbolic rules from visual patterns -- inferring the infinite from the finite. We investigate whether multimodal AI systems possess this capability through FractalBench, a benchmark evaluating fractal program synthesis from images. Fractals provide ideal test cases: Iterated Function Systems with only a few contraction maps generate complex self-similar patterns through simple recursive rules, requiring models to bridge visual perception with mathematical abstraction. We evaluate four leading MLLMs -- GPT-4o, Claude 3.7 Sonnet, Gemini 2.5 Flash, and Qwen 2.5-VL -- on 12 canonical fractals. Models must generate executable Python code reproducing the fractal, enabling objective evaluation. Results reveal a striking disconnect: 76% generate syntactically valid code but only 4% capture mathematical structure. Success varies systematically -- models handle geometric transformations (Koch curves: 17-21%) but fail at branching recursion (trees: <2%), revealing fundamental gaps in mathematical abstraction. FractalBench provides a contamination-resistant diagnostic for visual-mathematical reasoning and is available at https://github.com/NaiveNeuron/FractalBench
Robotic Dough Shaping
Jul 31, 2022

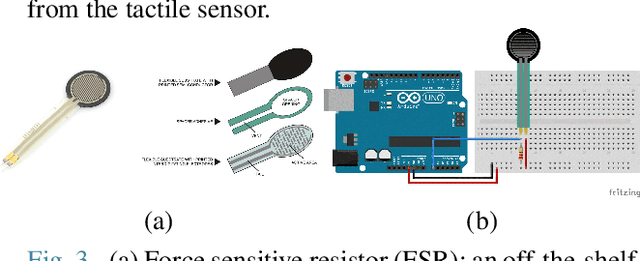
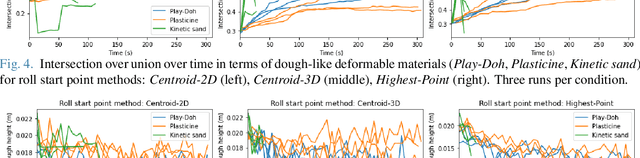
We address the problem of shaping a piece of dough-like deformable material into a 2D target shape presented upfront. We use a 6 degree-of-freedom WidowX-250 Robot Arm equipped with a rolling pin and information collected from an RGB-D camera and a tactile sensor. We present and compare several control policies, including a dough shrinking action, in extensive experiments across three kinds of deformable materials and across three target dough shape sizes, achieving the intersection over union (IoU) of 0.90. Our results show that: i) rolling dough from the highest dough point is more efficient than from the 2D/3D dough centroid; ii) it might be better to stop the roll movement at the current dough boundary as opposed to the target shape outline; iii) the shrink action might be beneficial only if properly tuned with respect to the exapand action; and iv) the Play-Doh material is easier to shape to a target shape as compared to Plasticine or Kinetic sand. Video demonstrations of our work are available at https://youtu.be/ZzLMxuITdt4
Human-Robot Commensality: Bite Timing Prediction for Robot-Assisted Feeding in Groups
Jul 07, 2022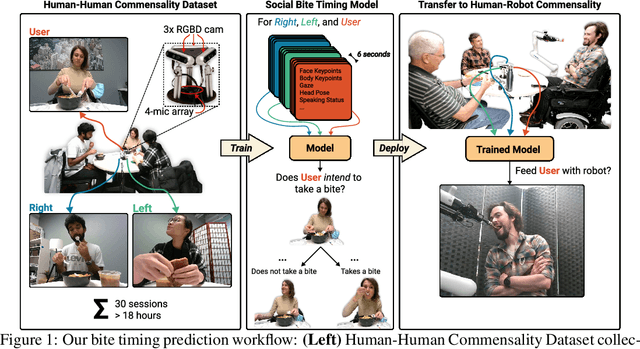
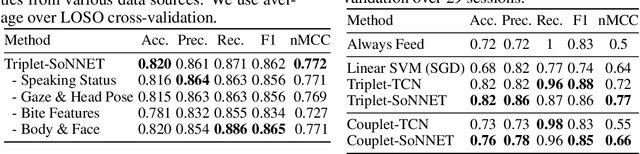
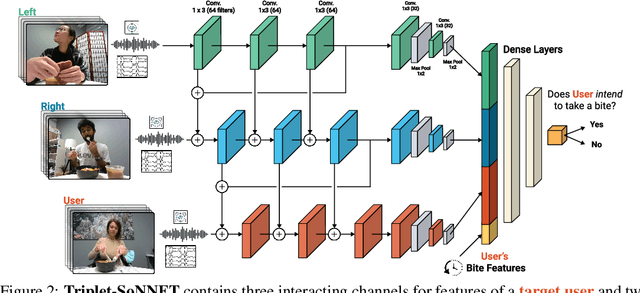
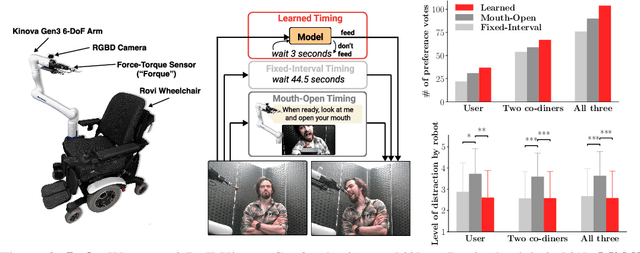
We develop data-driven models to predict when a robot should feed during social dining scenarios. Being able to eat independently with friends and family is considered one of the most memorable and important activities for people with mobility limitations. Robots can potentially help with this activity but robot-assisted feeding is a multi-faceted problem with challenges in bite acquisition, bite timing, and bite transfer. Bite timing in particular becomes uniquely challenging in social dining scenarios due to the possibility of interrupting a social human-robot group interaction during commensality. Our key insight is that bite timing strategies that take into account the delicate balance of social cues can lead to seamless interactions during robot-assisted feeding in a social dining scenario. We approach this problem by collecting a multimodal Human-Human Commensality Dataset (HHCD) containing 30 groups of three people eating together. We use this dataset to analyze human-human commensality behaviors and develop bite timing prediction models in social dining scenarios. We also transfer these models to human-robot commensality scenarios. Our user studies show that prediction improves when our algorithm uses multimodal social signaling cues between diners to model bite timing. The HHCD dataset, videos of user studies, and code will be publicly released after acceptance.