 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming challenges of translating deep-learning models for glioblastoma: the ZGBM consortium
May 07, 2024Objective: To report imaging protocol and scheduling variance in routine care of glioblastoma patients in order to demonstrate challenges of integrating deep-learning models in glioblastoma care pathways. Additionally, to understand the most common imaging studies and image contrasts to inform the development of potentially robust deep-learning models. Methods: MR imaging data were analysed from a random sample of five patients from the prospective cohort across five participating sites of the ZGBM consortium. Reported clinical and treatment data alongside DICOM header information were analysed to understand treatment pathway imaging schedules. Results: All sites perform all structural imaging at every stage in the pathway except for the presurgical study, where in some sites only contrast-enhanced T1-weighted imaging is performed. Diffusion MRI is the most common non-structural imaging type, performed at every site. Conclusion: The imaging protocol and scheduling varies across the UK, making it challenging to develop machine-learning models that could perform robustly at other centres. Structural imaging is performed most consistently across all centres. Advances in knowledge: Successful translation of deep-learning models will likely be based on structural post-treatment imaging unless there is significant effort made to standardise non-structural or peri-operative imaging protocols and schedules.
Combining keyphrase extraction and lexical diversity to characterize ideas in publication titles
Aug 30, 2022
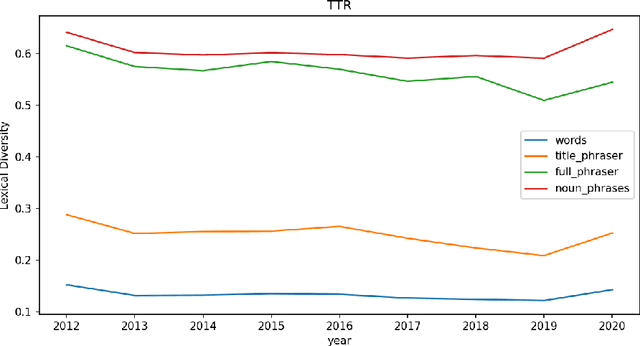
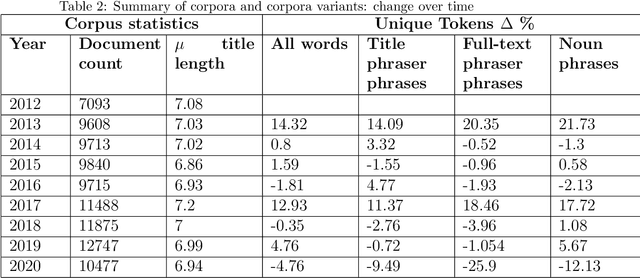
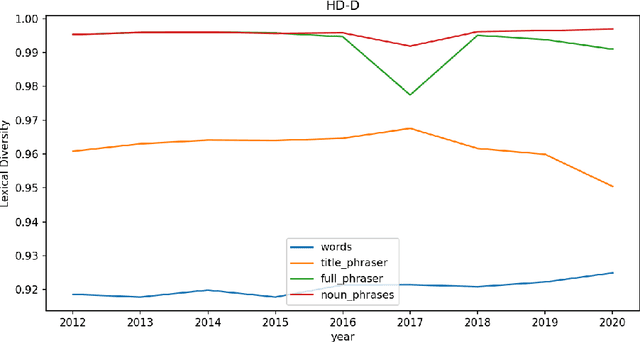
Beyond bibliometrics, there is interest in characterizing the evolution of the number of ideas in scientific papers. A common approach for investigating this involves analyzing the titles of publications to detect vocabulary changes over time. With the notion that phrases, or more specifically keyphrases, represent concepts, lexical diversity metrics are applied to phrased versions of the titles. Thus changes in lexical diversity are treated as indicators of shifts, and possibly expansion, of research. Therefore, optimizing detection of keyphrases is an important aspect of this process. Rather than just one, we propose to use multiple phrase detection models with the goal to produce a more comprehensive set of keyphrases from the source corpora. Another potential advantage to this approach is that the union and difference of these sets may provide automated techniques for identifying and omitting non-specific phrases. We compare the performance of several phrase detection models, analyze the keyphrase sets output of each, and calculate lexical diversity of corpora variants incorporating keyphrases from each model, using four common lexical diversity metrics.
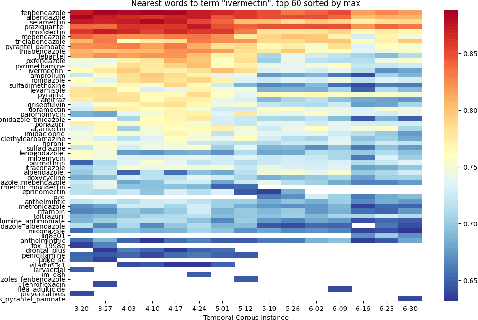
Diachronic Text Mining Investigation of Therapeutic Candidates for COVID-19
Oct 26, 2021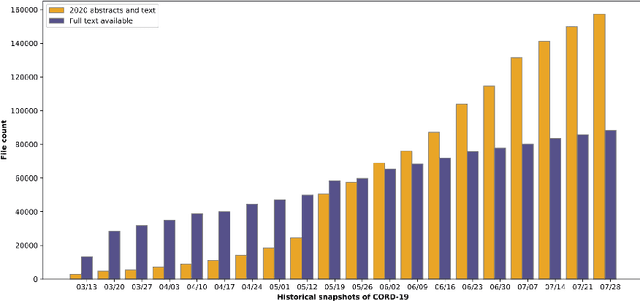
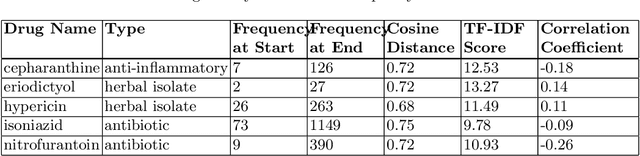
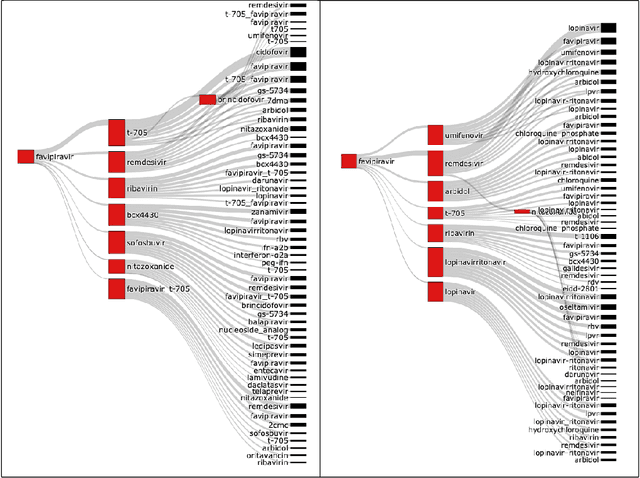

Diachronic text mining has frequently been applied to long-term linguistic surveys of word meaning and usage shifts over time. In this paper we apply short-term diachronic text mining to a rapidly growing corpus of scientific publications on COVID-19 captured in the CORD-19 dataset in order to identify co-occurrences and analyze the behavior of potential candidate treatments. We used a data set associated with a COVID-19 drug re-purposing study from Oak Ridge National Laboratory. This study identified existing candidate coronavirus treatments, including drugs and approved compounds, which had been analyzed and ranked according to their potential for blocking the ability of the SARS-COV-2 virus to invade human cells. We investigated the occurrence of these candidates in temporal instances of the CORD-19 corpus. We found that at least 25% of the identified terms occurred in temporal instances of the corpus to the extent that their frequency and contextual dynamics could be evaluated. We identified three classes of behaviors: those where frequency and contextual shifts were small and positively correlated; those where there was no correlation between frequency and contextual changes; and those where there was a negative correlation between frequency and contextual shift. We speculate that the latter two patterns are indicative that a target candidate therapeutics is undergoing active evaluation. The patterns we detected demonstrate the potential benefits of using diachronic text mining techniques with a large dynamic text corpus to track drug-repurposing activities across international clinical and laboratory settings.
Human-in-the-Loop Refinement of Word Embeddings
Oct 06, 2021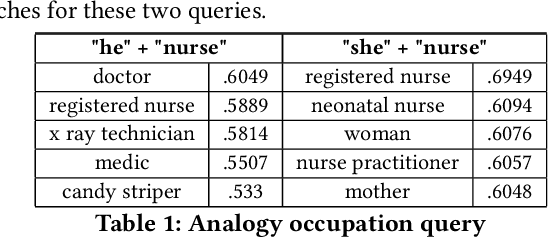
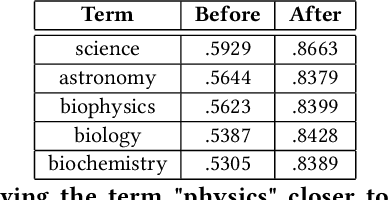
Word embeddings are a fixed, distributional representation of the context of words in a corpus learned from word co-occurrences. Despite their proven utility in machine learning tasks, word embedding models may capture uneven semantic and syntactic representations, and can inadvertently reflect various kinds of bias present within corpora upon which they were trained. It has been demonstrated that post-processing of word embeddings to apply information found in lexical dictionaries can improve the semantic associations, thus improving their quality. Building on this idea, we propose a system that incorporates an adaptation of word embedding post-processing, which we call "interactive refitting", to address some of the most daunting qualitative problems found in word embeddings. Our approach allows a human to identify and address potential quality issues with word embeddings interactively. This has the advantage of negating the question of who decides what constitutes bias or what other quality issues may affect downstream tasks. It allows each organization or entity to address concerns they may have at a fine grained level and to do so in an iterative and interactive fashion. It also allows for better insight into what effect word embeddings, and refinements to word embeddings, have on machine learning pipelines.
Tracking Short-Term Temporal Linguistic Dynamics to Characterize Candidate Therapeutics for COVID-19 in the CORD-19 Corpus
Jan 09, 2021
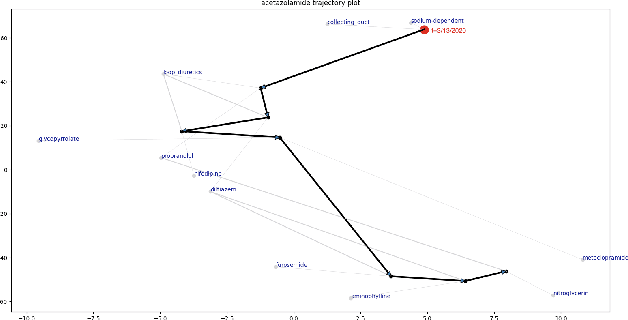
Scientific literature tends to grow as a function of funding and interest in a given field. Mining such literature can reveal trends that may not be immediately apparent. The CORD-19 corpus represents a growing corpus of scientific literature associated with COVID-19. We examined the intersection of a set of candidate therapeutics identified in a drug-repurposing study with temporal instances of the CORD-19 corpus to determine if it was possible to find and measure changes associated with them over time. We propose that the techniques we used could form the basis of a tool to pre-screen new candidate therapeutics early in the research process.
Interactive Re-Fitting as a Technique for Improving Word Embeddings
Sep 30, 2020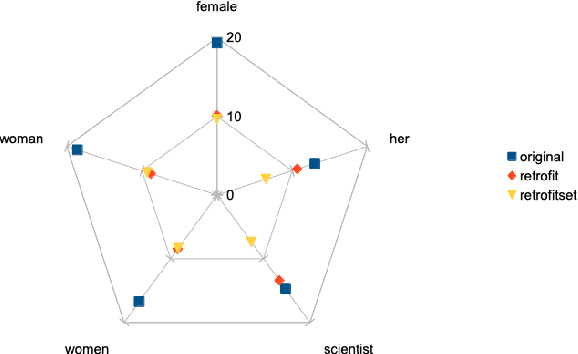
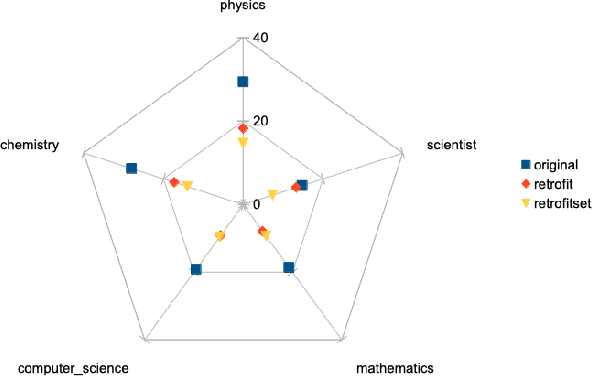
Word embeddings are a fixed, distributional representation of the context of words in a corpus learned from word co-occurrences. While word embeddings have proven to have many practical uses in natural language processing tasks, they reflect the attributes of the corpus upon which they are trained. Recent work has demonstrated that post-processing of word embeddings to apply information found in lexical dictionaries can improve their quality. We build on this post-processing technique by making it interactive. Our approach makes it possible for humans to adjust portions of a word embedding space by moving sets of words closer to one another. One motivating use case for this capability is to enable users to identify and reduce the presence of bias in word embeddings. Our approach allows users to trigger selective post-processing as they interact with and assess potential bias in word embeddings.