 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining keyphrase extraction and lexical diversity to characterize ideas in publication titles
Aug 30, 2022
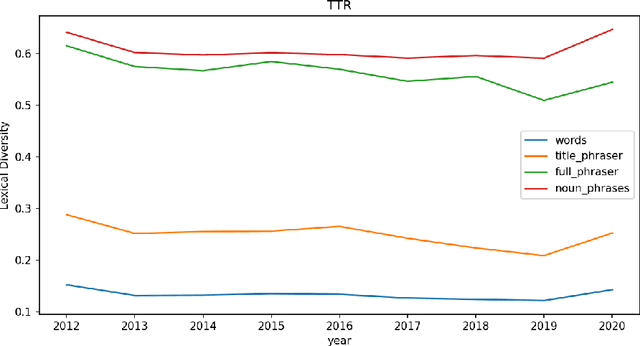
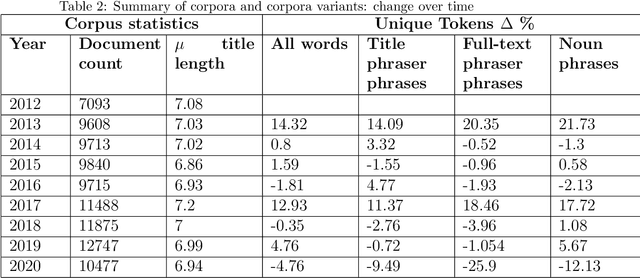
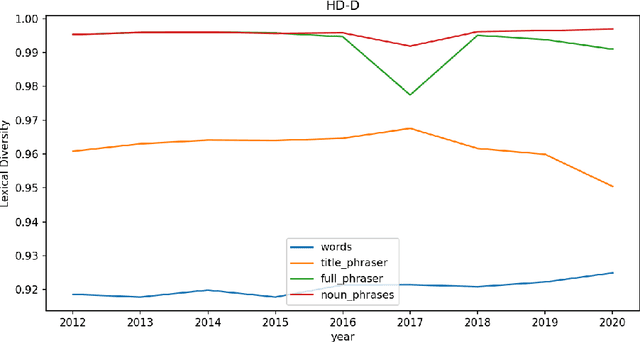
Beyond bibliometrics, there is interest in characterizing the evolution of the number of ideas in scientific papers. A common approach for investigating this involves analyzing the titles of publications to detect vocabulary changes over time. With the notion that phrases, or more specifically keyphrases, represent concepts, lexical diversity metrics are applied to phrased versions of the titles. Thus changes in lexical diversity are treated as indicators of shifts, and possibly expansion, of research. Therefore, optimizing detection of keyphrases is an important aspect of this process. Rather than just one, we propose to use multiple phrase detection models with the goal to produce a more comprehensive set of keyphrases from the source corpora. Another potential advantage to this approach is that the union and difference of these sets may provide automated techniques for identifying and omitting non-specific phrases. We compare the performance of several phrase detection models, analyze the keyphrase sets output of each, and calculate lexical diversity of corpora variants incorporating keyphrases from each model, using four common lexical diversity metrics.
Human-in-the-Loop Refinement of Word Embeddings
Oct 06, 2021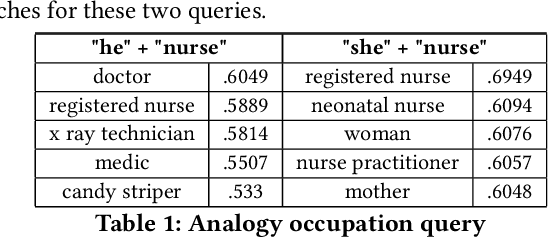
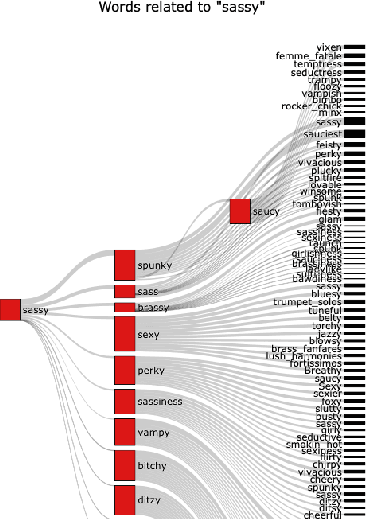
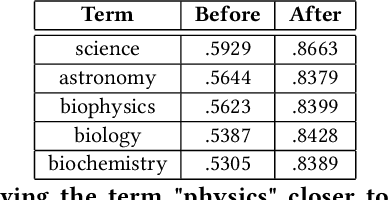
Word embeddings are a fixed, distributional representation of the context of words in a corpus learned from word co-occurrences. Despite their proven utility in machine learning tasks, word embedding models may capture uneven semantic and syntactic representations, and can inadvertently reflect various kinds of bias present within corpora upon which they were trained. It has been demonstrated that post-processing of word embeddings to apply information found in lexical dictionaries can improve the semantic associations, thus improving their quality. Building on this idea, we propose a system that incorporates an adaptation of word embedding post-processing, which we call "interactive refitting", to address some of the most daunting qualitative problems found in word embeddings. Our approach allows a human to identify and address potential quality issues with word embeddings interactively. This has the advantage of negating the question of who decides what constitutes bias or what other quality issues may affect downstream tasks. It allows each organization or entity to address concerns they may have at a fine grained level and to do so in an iterative and interactive fashion. It also allows for better insight into what effect word embeddings, and refinements to word embeddings, have on machine learning pipelines.
Evaluating Memento Service Optimizations
May 31, 2019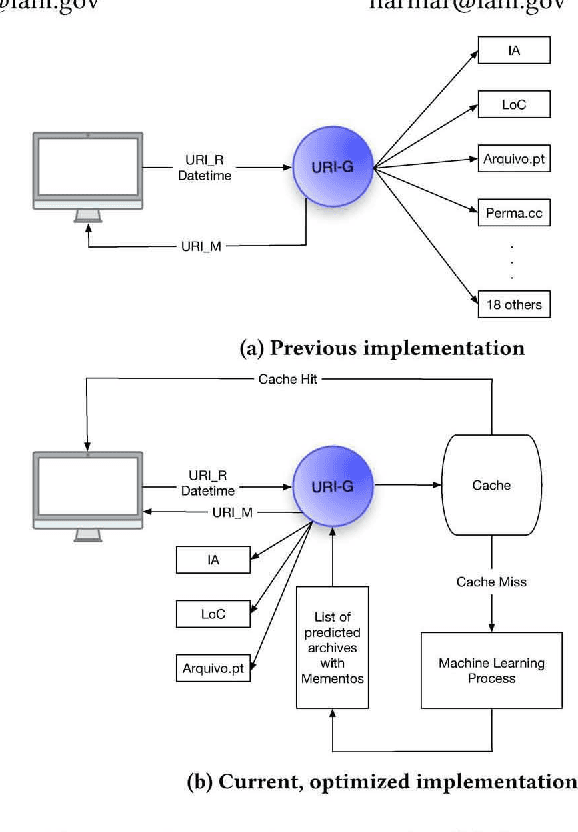
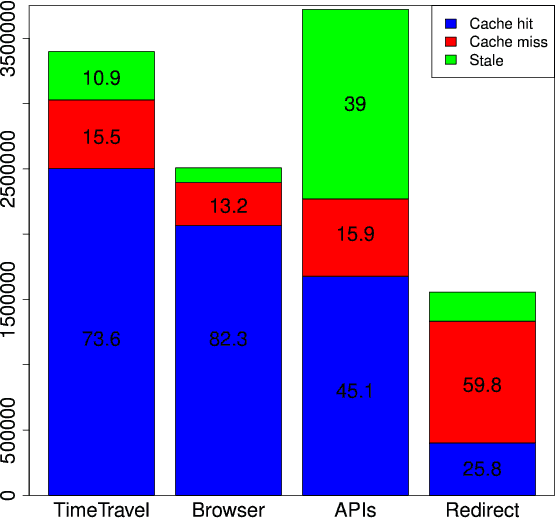
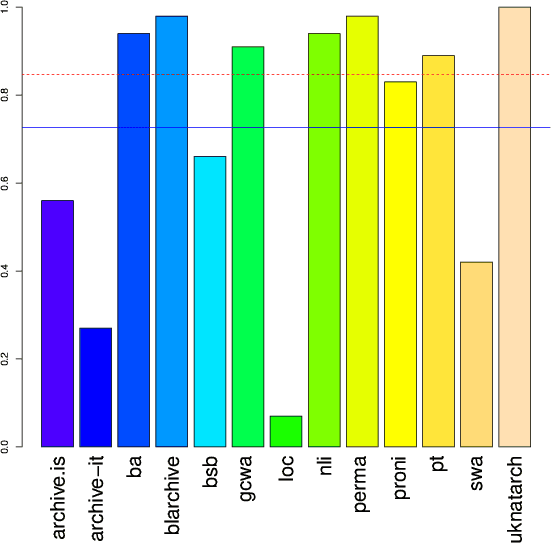
Services and applications based on the Memento Aggregator can suffer from slow response times due to the federated search across web archives performed by the Memento infrastructure. In an effort to decrease the response times, we established a cache system and experimented with machine learning models to predict archival holdings. We reported on the experimental results in previous work and can now, after these optimizations have been in production for two years, evaluate their efficiency, based on long-term log data. During our investigation we find that the cache is very effective with a 70-80% cache hit rate for human-driven services. The machine learning prediction operates at an acceptable average recall level of 0.727 but our results also show that a more frequent retraining of the models is needed to further improve prediction accuracy.