 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly predicting of hospital admission using machine learning algorithms: Priority queues approach
Jan 21, 2026Emergency Department overcrowding is a critical issue that compromises patient safety and operational efficiency, necessitating accurate demand forecasting for effective resource allocation. This study evaluates and compares three distinct predictive models: Seasonal AutoRegressive Integrated Moving Average with eXogenous regressors (SARIMAX), EXtreme Gradient Boosting (XGBoost) and Long Short-Term Memory (LSTM) networks for forecasting daily ED arrivals over a seven-day horizon. Utilizing data from an Australian tertiary referral hospital spanning January 2017 to December 2021, this research distinguishes itself by decomposing demand into eight specific ward categories and stratifying patients by clinical complexity. To address data distortions caused by the COVID-19 pandemic, the study employs the Prophet model to generate synthetic counterfactual values for the anomalous period. Experimental results demonstrate that all three proposed models consistently outperform a seasonal naive baseline. XGBoost demonstrated the highest accuracy for predicting total daily admissions with a Mean Absolute Error of 6.63, while the statistical SARIMAX model proved marginally superior for forecasting major complexity cases with an MAE of 3.77. The study concludes that while these techniques successfully reproduce regular day-to-day patterns, they share a common limitation in underestimating sudden, infrequent surges in patient volume.
PersonaLedger: Generating Realistic Financial Transactions with Persona Conditioned LLMs and Rule Grounded Feedback
Jan 06, 2026Strict privacy regulations limit access to real transaction data, slowing open research in financial AI. Synthetic data can bridge this gap, but existing generators do not jointly achieve behavioral diversity and logical groundedness. Rule-driven simulators rely on hand-crafted workflows and shallow stochasticity, which miss the richness of human behavior. Learning-based generators such as GANs capture correlations yet often violate hard financial constraints and still require training on private data. We introduce PersonaLedger, a generation engine that uses a large language model conditioned on rich user personas to produce diverse transaction streams, coupled with an expert configurable programmatic engine that maintains correctness. The LLM and engine interact in a closed loop: after each event, the engine updates the user state, enforces financial rules, and returns a context aware "nextprompt" that guides the LLM toward feasible next actions. With this engine, we create a public dataset of 30 million transactions from 23,000 users and a benchmark suite with two tasks, illiquidity classification and identity theft segmentation. PersonaLedger offers a realistic, privacy preserving resource that supports rigorous evaluation of forecasting and anomaly detection models. PersonaLedger offers the community a rich, realistic, and privacy preserving resource -- complete with code, rules, and generation logs -- to accelerate innovation in financial AI and enable rigorous, reproducible evaluation.
Leveraging Deep Learning for Physical Model Bias of Global Air Quality Estimates
Aug 06, 2025Air pollution is the world's largest environmental risk factor for human disease and premature death, resulting in more than 6 million permature deaths in 2019. Currently, there is still a challenge to model one of the most important air pollutants, surface ozone, particularly at scales relevant for human health impacts, with the drivers of global ozone trends at these scales largely unknown, limiting the practical use of physics-based models. We employ a 2D Convolutional Neural Network based architecture that estimate surface ozone MOMO-Chem model residuals, referred to as model bias. We demonstrate the potential of this technique in North America and Europe, highlighting its ability better to capture physical model residuals compared to a traditional machine learning method. We assess the impact of incorporating land use information from high-resolution satellite imagery to improve model estimates. Importantly, we discuss how our results can improve our scientific understanding of the factors impacting ozone bias at urban scales that can be used to improve environmental policy.
Uncertainty Quantification for Surface Ozone Emulators using Deep Learning
Aug 06, 2025Air pollution is a global hazard, and as of 2023, 94\% of the world's population is exposed to unsafe pollution levels. Surface Ozone (O3), an important pollutant, and the drivers of its trends are difficult to model, and traditional physics-based models fall short in their practical use for scales relevant to human-health impacts. Deep Learning-based emulators have shown promise in capturing complex climate patterns, but overall lack the interpretability necessary to support critical decision making for policy changes and public health measures. We implement an uncertainty-aware U-Net architecture to predict the Multi-mOdel Multi-cOnstituent Chemical data assimilation (MOMO-Chem) model's surface ozone residuals (bias) using Bayesian and quantile regression methods. We demonstrate the capability of our techniques in regional estimation of bias in North America and Europe for June 2019. We highlight the uncertainty quantification (UQ) scores between our two UQ methodologies and discern which ground stations are optimal and sub-optimal candidates for MOMO-Chem bias correction, and evaluate the impact of land-use information in surface ozone residual modeling.
PSI Draft Specification
May 02, 2022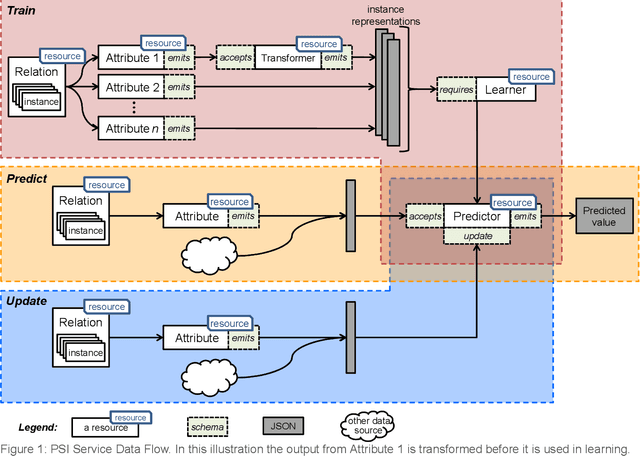
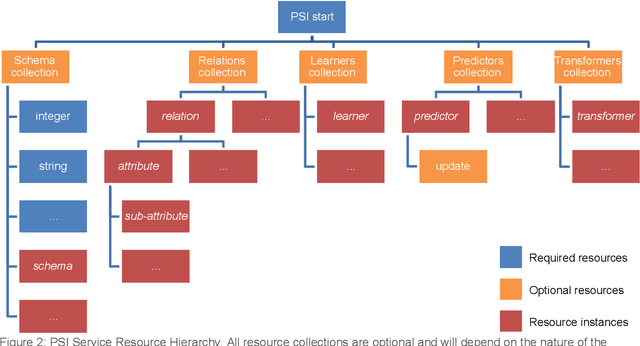
This document presents the draft specification for delivering machine learning services over HTTP, developed as part of the Protocols and Structures for Inference project, which concluded in 2013. It presents the motivation for providing machine learning as a service, followed by a description of the essential and optional components of such a service.