 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Identity from Utility: Privacy-by-Design Frameworks for Financial Ecosystems
Apr 16, 2026Financial institutions face tension between maximizing data utility and mitigating the re-identification risks inherent in traditional anonymization methods. This paper explores Differentially Private (DP) synthetic data as a robust "Privacy by Design" framework to resolve this conflict, ensuring output privacy while satisfying stringent regulatory obligations. We examine two distinct generative paradigms: Direct Tabular Synthesis, which reconstructs high-fidelity joint distributions from raw data, and DP-Seeded Agent-Based Modeling (ABM), which uses DP-protected aggregates to parameterize complex, stateful simulations. While tabular synthesis excels at reflecting static historical correlations for QA testing and business analytics, the DP-Seeded ABM offers a forward-looking "counterfactual laboratory" capable of modeling dynamic market behaviors and black swan events. By decoupling individual identities from data utility, these methodologies eliminate traditional data-clearing bottlenecks, enabling seamless cross-institutional research and compliant decision-making in an evolving regulatory landscape.
PersonaLedger: Generating Realistic Financial Transactions with Persona Conditioned LLMs and Rule Grounded Feedback
Jan 06, 2026Strict privacy regulations limit access to real transaction data, slowing open research in financial AI. Synthetic data can bridge this gap, but existing generators do not jointly achieve behavioral diversity and logical groundedness. Rule-driven simulators rely on hand-crafted workflows and shallow stochasticity, which miss the richness of human behavior. Learning-based generators such as GANs capture correlations yet often violate hard financial constraints and still require training on private data. We introduce PersonaLedger, a generation engine that uses a large language model conditioned on rich user personas to produce diverse transaction streams, coupled with an expert configurable programmatic engine that maintains correctness. The LLM and engine interact in a closed loop: after each event, the engine updates the user state, enforces financial rules, and returns a context aware "nextprompt" that guides the LLM toward feasible next actions. With this engine, we create a public dataset of 30 million transactions from 23,000 users and a benchmark suite with two tasks, illiquidity classification and identity theft segmentation. PersonaLedger offers a realistic, privacy preserving resource that supports rigorous evaluation of forecasting and anomaly detection models. PersonaLedger offers the community a rich, realistic, and privacy preserving resource -- complete with code, rules, and generation logs -- to accelerate innovation in financial AI and enable rigorous, reproducible evaluation.
A blockchain-orchestrated Federated Learning architecture for healthcare consortia
Oct 12, 2019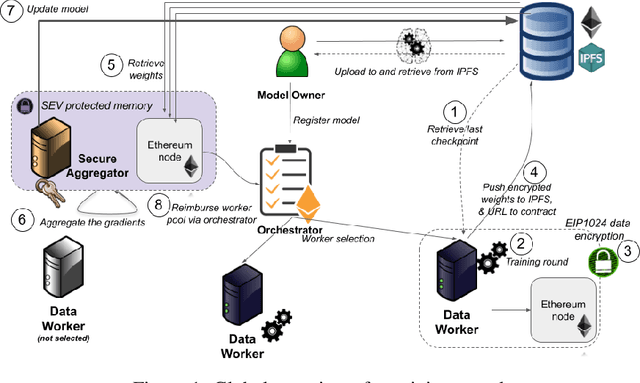
We propose a novel architecture for federated learning within healthcare consortia. At the heart of the solution is a unique integration of privacy preserving technologies, built upon native enterprise blockchain components available in the Ethereum ecosystem. We show how the specific characteristics and challenges of healthcare consortia informed our design choices, notably the conception of a new Secure Aggregation protocol assembled with a protected hardware component and an encryption toolkit native to Ethereum. Our architecture also brings in a privacy preserving audit trail that logs events in the network without revealing identities.