 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Navigation Planning for Long-term Autonomous Operation of Underwater Gliders
Feb 22, 2026Underwater glider robots have become an indispensable tool for ocean sampling. Although stakeholders are calling for tools to manage increasingly large fleets of gliders, successful autonomous long-term deployments have thus far been scarce, which hints at a lack of suitable methodologies and systems. In this work, we formulate glider navigation planning as a stochastic shortest-path Markov Decision Process and propose a sample-based online planner based on Monte Carlo Tree Search. Samples are generated by a physics-informed simulator that captures uncertain execution of controls and ocean current forecasts while remaining computationally tractable. The simulator parameters are fitted using historical glider data. We integrate these methods into an autonomous command-and-control system for Slocum gliders that enables closed-loop replanning at each surfacing. The resulting system was validated in two field deployments in the North Sea totalling approximately 3 months and 1000 km of autonomous operation. Results demonstrate improved efficiency compared to straight-to-goal navigation and show the practicality of sample-based planning for long-term marine autonomy.
Mostra: A Flexible Balancing Framework to Trade-off User, Artist and Platform Objectives for Music Sequencing
Apr 22, 2022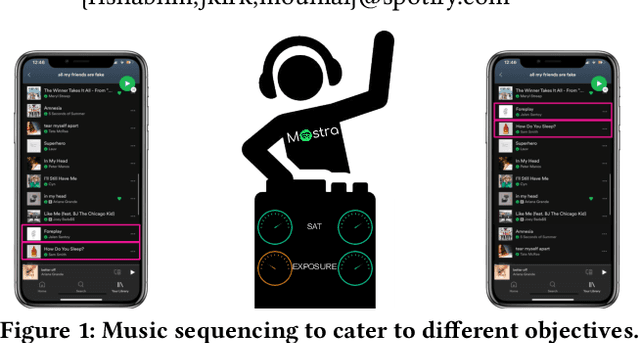
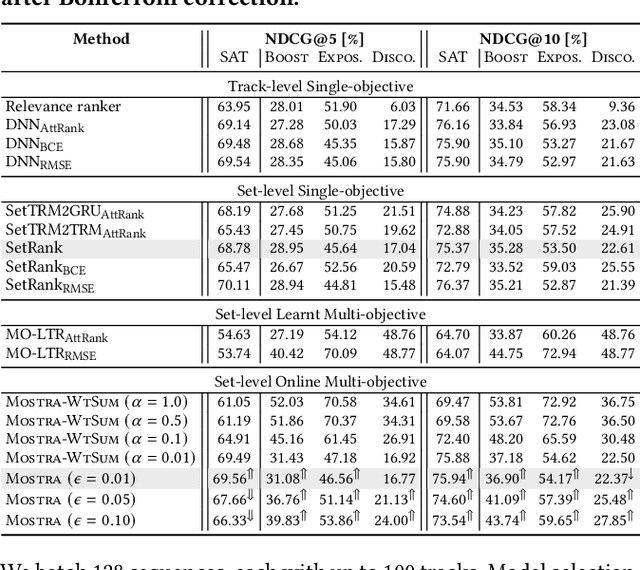

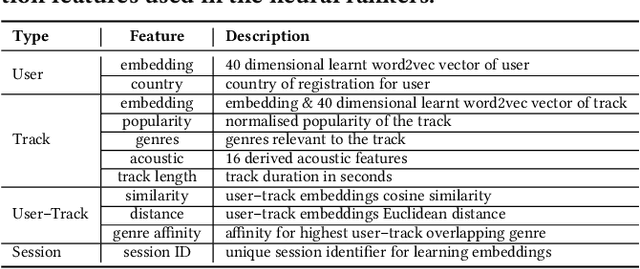
We consider the task of sequencing tracks on music streaming platforms where the goal is to maximise not only user satisfaction, but also artist- and platform-centric objectives, needed to ensure long-term health and sustainability of the platform. Grounding the work across four objectives: Sat, Discovery, Exposure and Boost, we highlight the need and the potential to trade-off performance across these objectives, and propose Mostra, a Set Transformer-based encoder-decoder architecture equipped with submodular multi-objective beam search decoding. The proposed model affords system designers the power to balance multiple goals, and dynamically control the impact on one objective to satisfy other objectives. Through extensive experiments on data from a large-scale music streaming platform, we present insights on the trade-offs that exist across different objectives, and demonstrate that the proposed framework leads to a superior, just-in-time balancing across the various metrics of interest.
A Computational Model for Situated Task Learning with Interactive Instruction
Apr 23, 2016
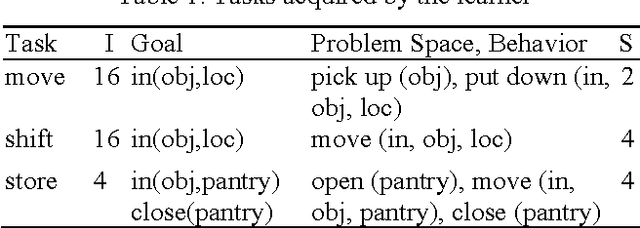
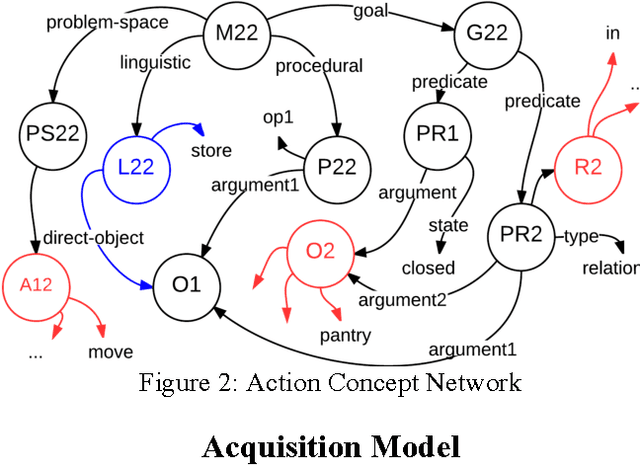
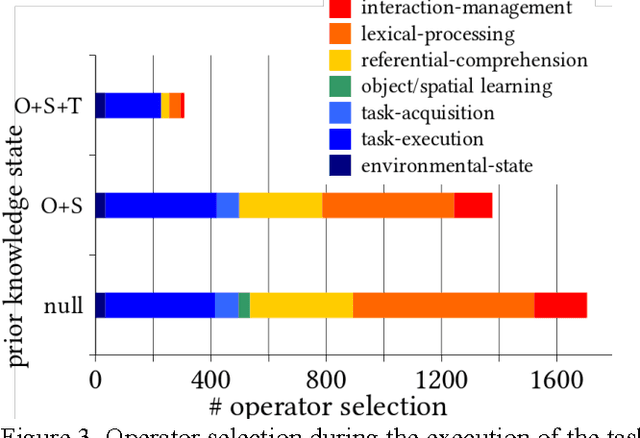
Learning novel tasks is a complex cognitive activity requiring the learner to acquire diverse declarative and procedural knowledge. Prior ACT-R models of acquiring task knowledge from instruction focused on learning procedural knowledge from declarative instructions encoded in semantic memory. In this paper, we identify the requirements for designing compu- tational models that learn task knowledge from situated task- oriented interactions with an expert and then describe and evaluate a model of learning from situated interactive instruc- tion that is implemented in the Soar cognitive architecture.