 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unstoppable Rise of Computational Linguistics in Deep Learning
Jun 11, 2020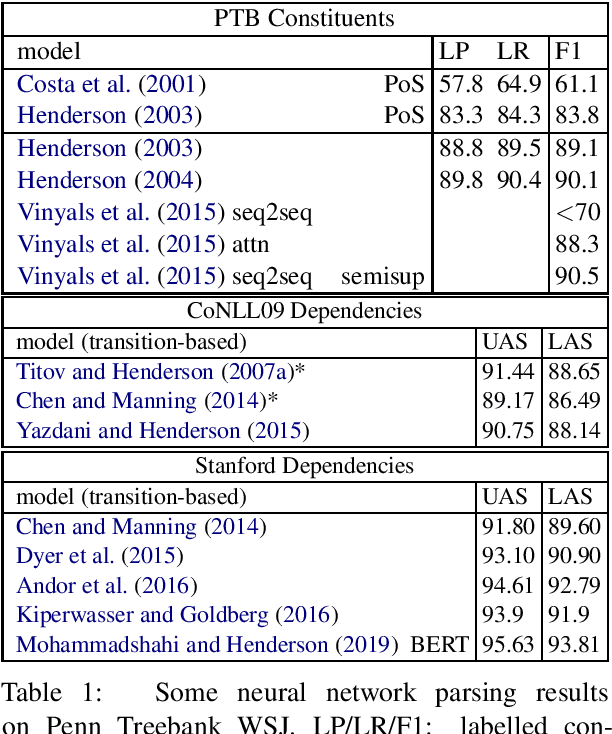
In this paper, we trace the history of neural networks applied to natural language understanding tasks, and identify key contributions which the nature of language has made to the development of neural network architectures. We focus on the importance of variable binding and its instantiation in attention-based models, and argue that Transformer is not a sequence model but an induced-structure model. This perspective leads to predictions of the challenges facing research in deep learning architectures for natural language understanding.
Recursive Non-Autoregressive Graph-to-Graph Transformer for Dependency Parsing with Iterative Refinement
Mar 29, 2020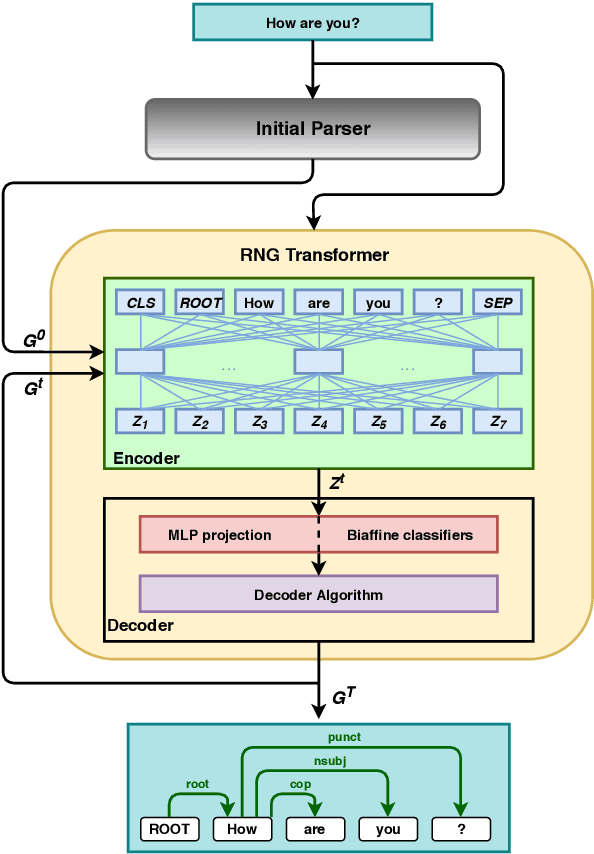
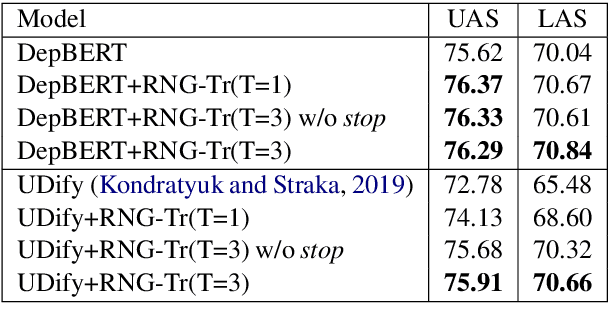
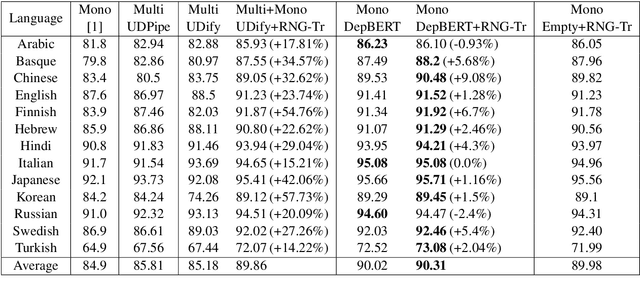
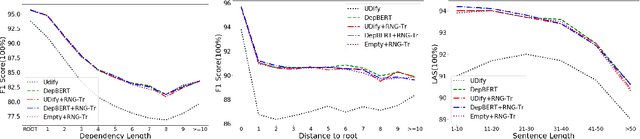
We propose the Recursive Non-autoregressive Graph-to-graph Transformer architecture (RNG-Tr) for the iterative refinement of arbitrary graphs through the recursive application of a non-autoregressive Graph-to-Graph Transformer and apply it to syntactic dependency parsing. The Graph-to-Graph Transformer architecture of \newcite{mohammadshahi2019graphtograph} has previously been used for autoregressive graph prediction, but here we use it to predict all edges of the graph independently, conditioned on a previous prediction of the same graph. We demonstrate the power and effectiveness of RNG-Tr on several dependency corpora, using a refinement model pre-trained with BERT \cite{devlin2018bert}. We also introduce Dependency BERT (DepBERT), a non-recursive parser similar to our refinement model. RNG-Tr is able to improve the accuracy of a variety of initial parsers on 13 languages from the Universal Dependencies Treebanks and the English and Chinese Penn Treebanks, even improving over the new state-of-the-art results achieved by DepBERT, significantly improving the state-of-the-art for all corpora tested.
Graph-to-Graph Transformer for Transition-based Dependency Parsing
Nov 08, 2019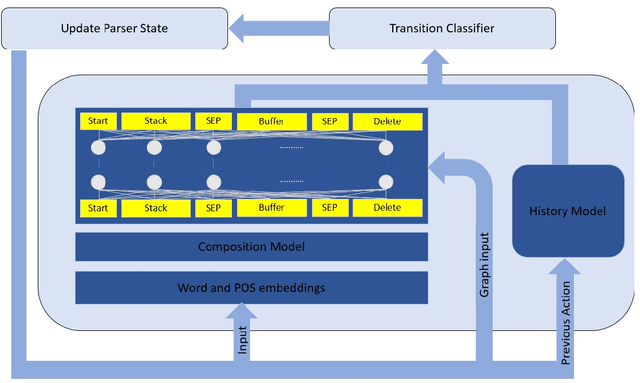
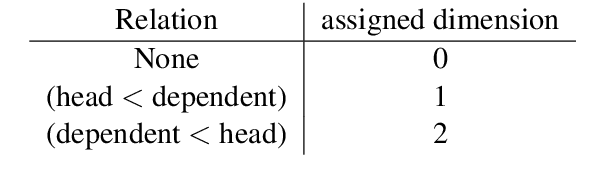
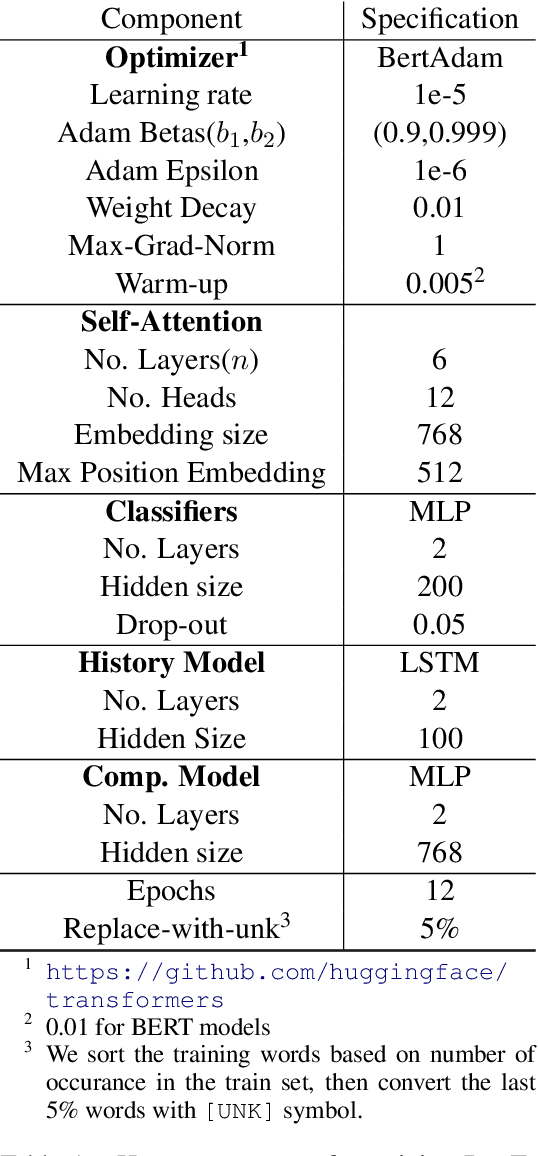
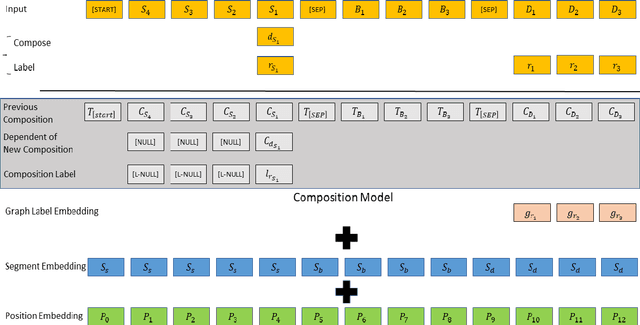
Transition-based dependency parsing is a challenging task for conditioning on and predicting structures. We demonstrate state-of-the-art results on this benchmark with the Graph2Graph Transformer architecture. This novel architecture supports both the input and output of arbitrary graphs via its attention mechanism. It can also be integrated both with previous neural network structured prediction techniques and with existing Transformer pre-trained models. Both with and without BERT pretraining, adding dependency graph inputs via the attention mechanism results in significant improvements over previously proposed mechanism for encoding the partial parse tree, resulting in accuracies which improve the state-of-the-art in transition-based dependency parsing, achieving 95.64% UAS and 93.81% LAS performance on Stanford WSJ dependencies. Graph2Graph Transformers are not restricted to tree structures and can be easily applied to a wide range of NLP tasks.
Simple but effective techniques to reduce biases
Sep 25, 2019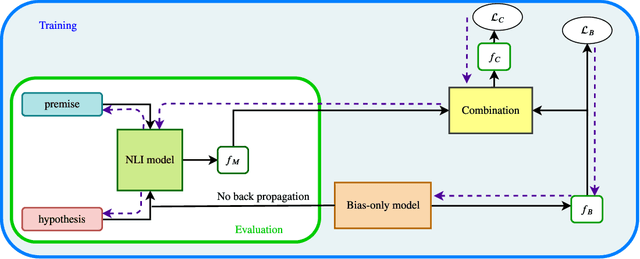
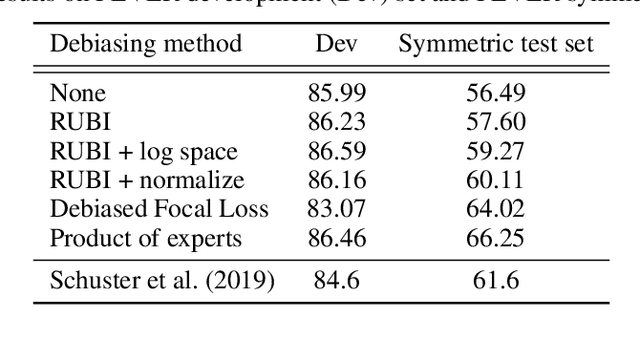
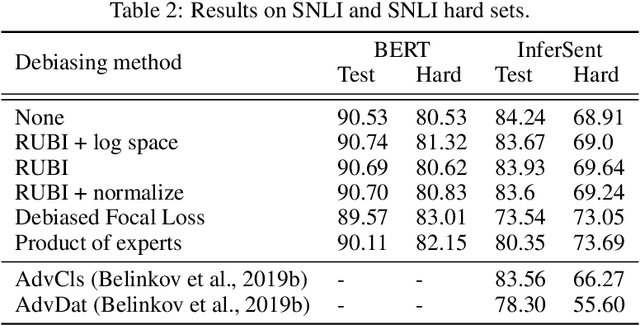
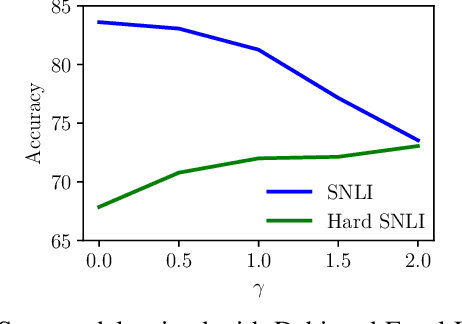
There have been several studies recently showing that strong natural language understanding (NLU) models are prone to relying on unwanted dataset biases without learning the underlying task, resulting in models which fail to generalize to out-of-domain datasets, and are likely to perform poorly in real-world scenarios. We propose several learning strategies to train neural models which are more robust to such biases and transfer better to out-of-domain datasets. We introduce an additional lightweight bias-only model which learns dataset biases and uses its prediction to adjust the loss of the base model to reduce the biases. In other words, our methods down-weight the importance of the biased examples, and focus training on hard examples, i.e. examples that cannot be correctly classified by only relying on biases. Our approaches are model agnostic and simple to implement. We experiment on large-scale natural language inference and fact verification datasets and their out-of-domain datasets and show that our debiased models significantly improve the robustness in all settings, including gaining 9.76 points on the FEVER symmetric evaluation dataset, 5.45 on the HANS dataset and 4.78 points on the SNLI hard set. These datasets are specifically designed to assess the robustness of models in the out-of-domain setting where typical biases in the training data do not exist in the evaluation set.
Partially-supervised Mention Detection
Aug 26, 2019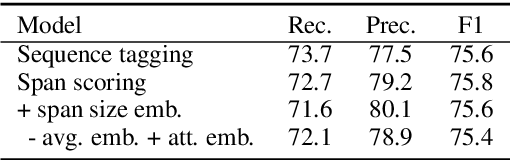
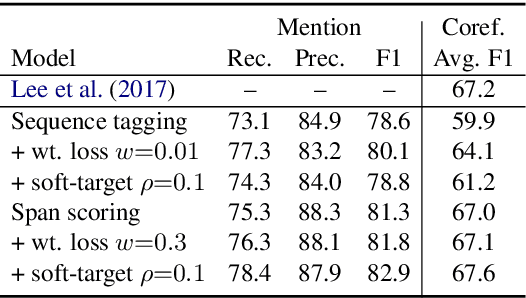
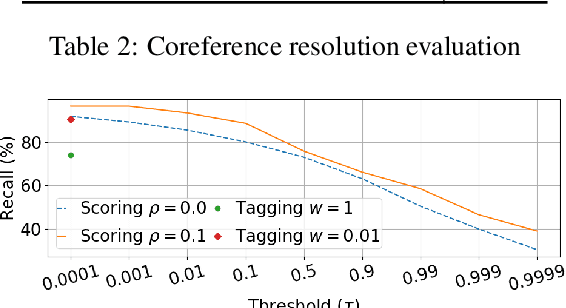
Learning to detect entity mentions without using syntactic information can be useful for integration and joint optimization with other tasks. However, it is common to have partially annotated data for this problem. Here, we investigate two approaches to deal with partial annotation of mentions: weighted loss and soft-target classification. We also propose two neural mention detection approaches: a sequence tagging, and an exhaustive search. We evaluate our methods with coreference resolution as a downstream task, using multitask learning. The results show that the recall and F1 score improve for all methods.
Regularization Advantages of Multilingual Neural Language Models for Low Resource Domains
May 29, 2019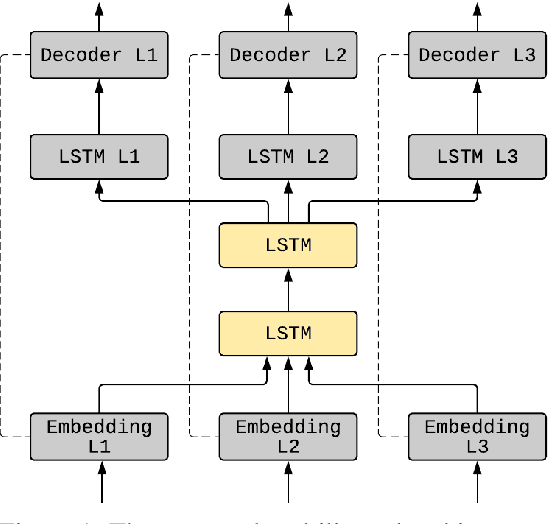
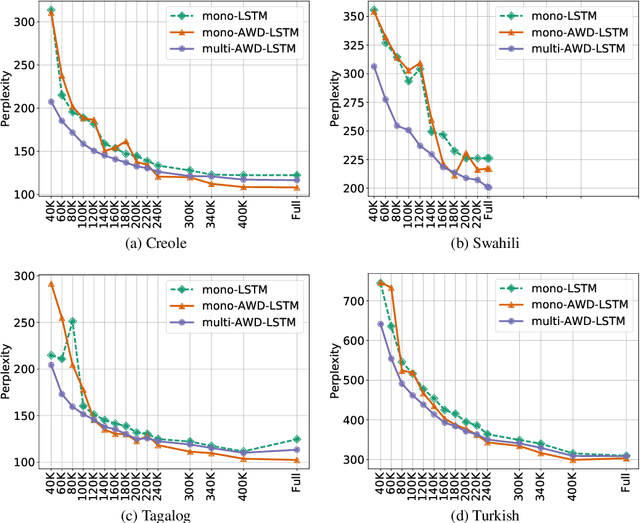
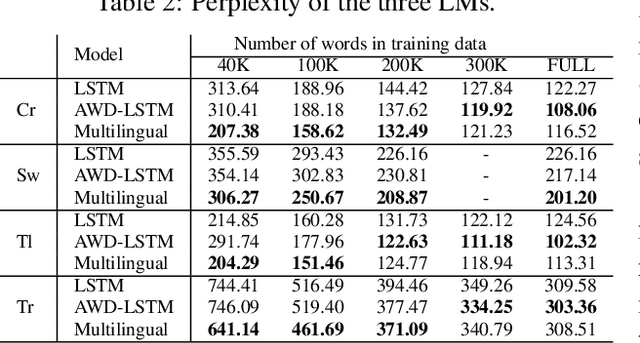
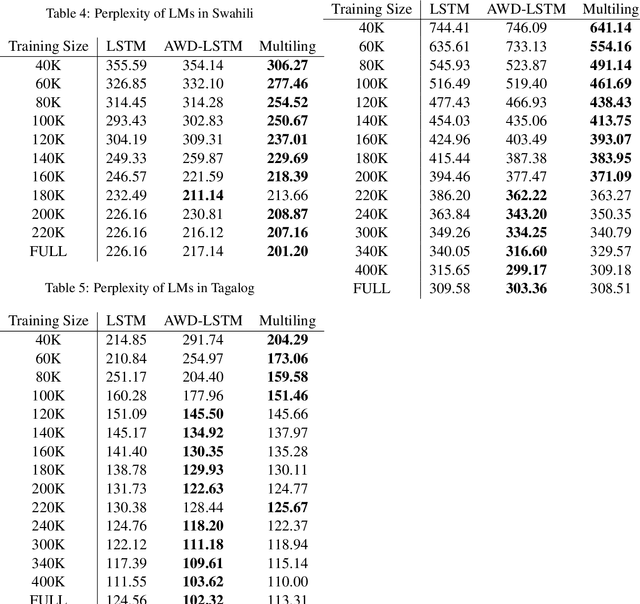
Neural language modeling (LM) has led to significant improvements in several applications, including Automatic Speech Recognition. However, they typically require large amounts of training data, which is not available for many domains and languages. In this study, we propose a multilingual neural language model architecture, trained jointly on the domain-specific data of several low-resource languages. The proposed multilingual LM consists of language specific word embeddings in the encoder and decoder, and one language specific LSTM layer, plus two LSTM layers with shared parameters across the languages. This multilingual LM model facilitates transfer learning across the languages, acting as an extra regularizer in very low-resource scenarios. We integrate our proposed multilingual approach with a state-of-the-art highly-regularized neural LM, and evaluate on the conversational data domain for four languages over a range of training data sizes. Compared to monolingual LMs, the results show significant improvements of our proposed multilingual LM when the amount of available training data is limited, indicating the advantages of cross-lingual parameter sharing in very low-resource language modeling.
Deep Residual Output Layers for Neural Language Generation
May 22, 2019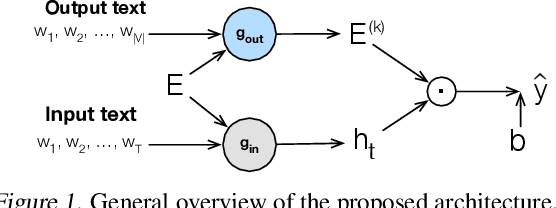
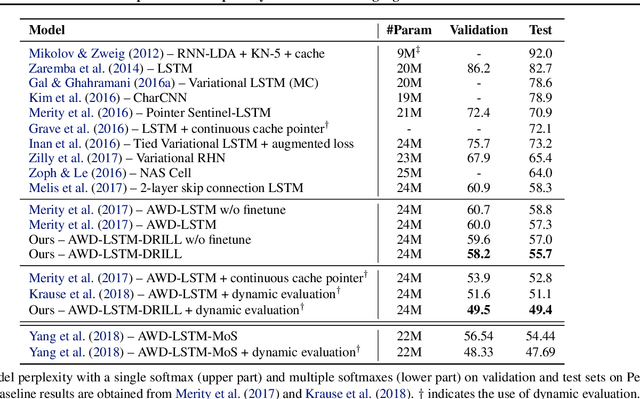
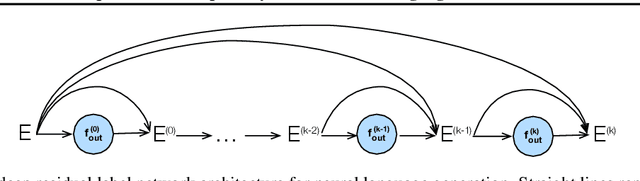
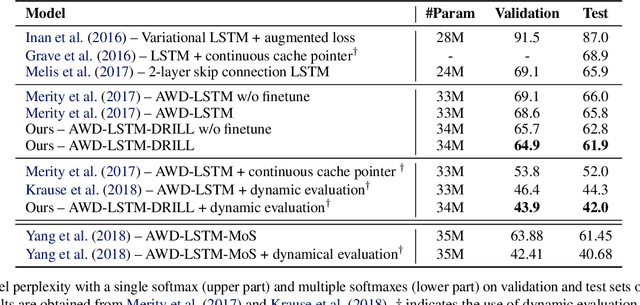
Many tasks, including language generation, benefit from learning the structure of the output space, particularly when the space of output labels is large and the data is sparse. State-of-the-art neural language models indirectly capture the output space structure in their classifier weights since they lack parameter sharing across output labels. Learning shared output label mappings helps, but existing methods have limited expressivity and are prone to overfitting. In this paper, we investigate the usefulness of more powerful shared mappings for output labels, and propose a deep residual output mapping with dropout between layers to better capture the structure of the output space and avoid overfitting. Evaluations on three language generation tasks show that our output label mapping can match or improve state-of-the-art recurrent and self-attention architectures, and suggest that the classifier does not necessarily need to be high-rank to better model natural language if it is better at capturing the structure of the output space.
Weakly-Supervised Concept-based Adversarial Learning for Cross-lingual Word Embeddings
Apr 20, 2019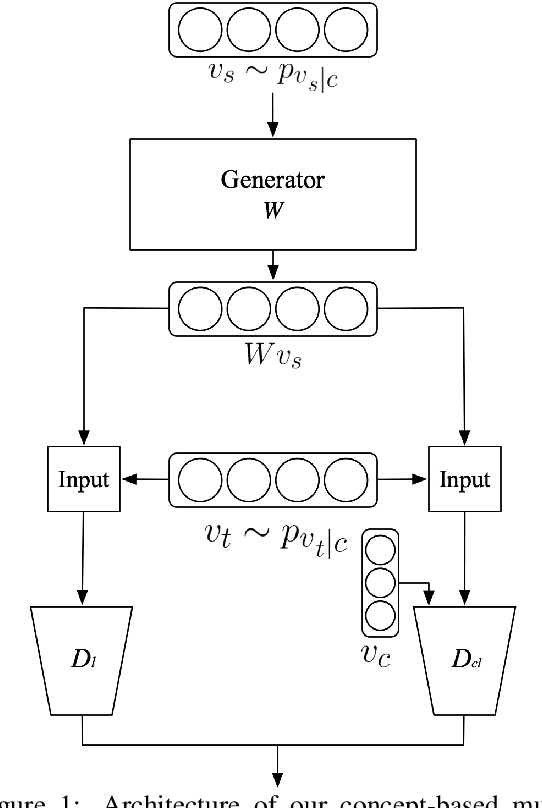
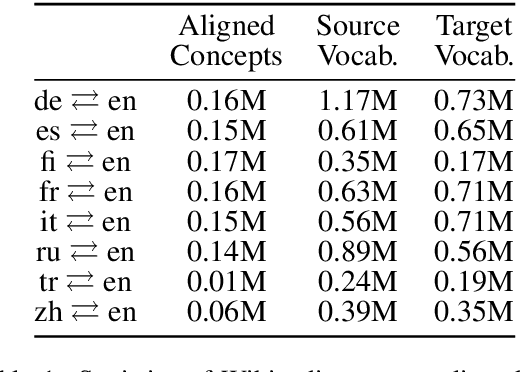
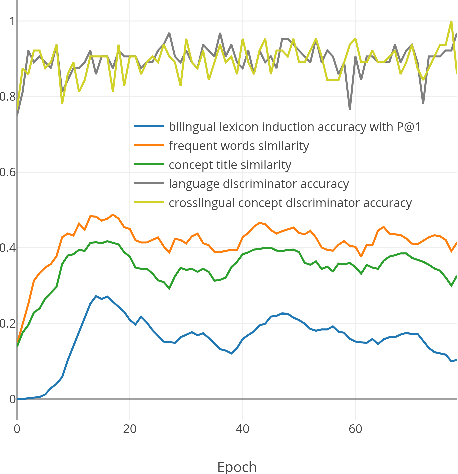
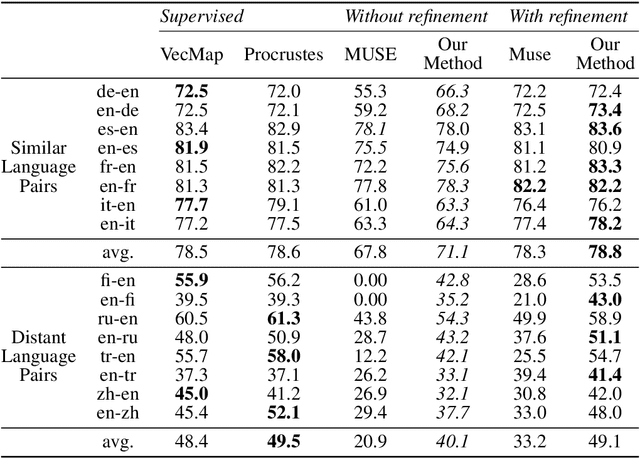
Distributed representations of words which map each word to a continuous vector have proven useful in capturing important linguistic information not only in a single language but also across different languages. Current unsupervised adversarial approaches show that it is possible to build a mapping matrix that align two sets of monolingual word embeddings together without high quality parallel data such as a dictionary or a sentence-aligned corpus. However, without post refinement, the performance of these methods' preliminary mapping is not good, leading to poor performance for typologically distant languages. In this paper, we propose a weakly-supervised adversarial training method to overcome this limitation, based on the intuition that mapping across languages is better done at the concept level than at the word level. We propose a concept-based adversarial training method which for most languages improves the performance of previous unsupervised adversarial methods, especially for typologically distant language pairs.
Document-Level Neural Machine Translation with Hierarchical Attention Networks
Oct 01, 2018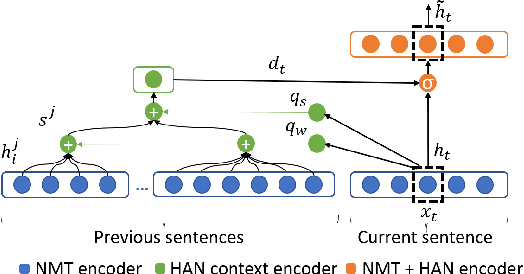
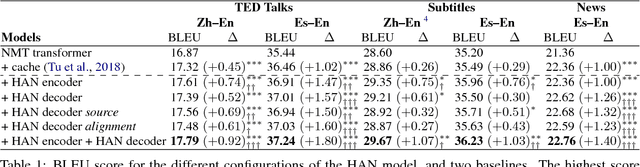
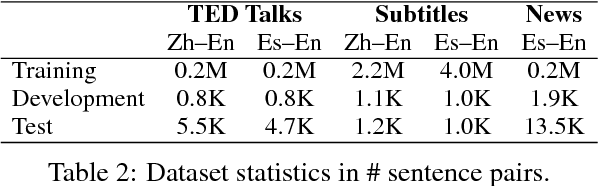
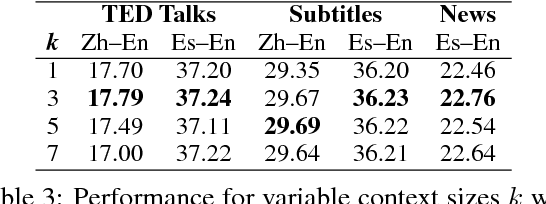
Neural Machine Translation (NMT) can be improved by including document-level contextual information. For this purpose, we propose a hierarchical attention model to capture the context in a structured and dynamic manner. The model is integrated in the original NMT architecture as another level of abstraction, conditioning on the NMT model's own previous hidden states. Experiments show that hierarchical attention significantly improves the BLEU score over a strong NMT baseline with the state-of-the-art in context-aware methods, and that both the encoder and decoder benefit from context in complementary ways.
Beyond Weight Tying: Learning Joint Input-Output Embeddings for Neural Machine Translation
Aug 31, 2018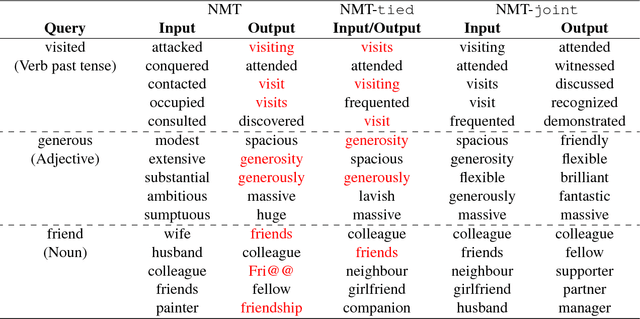
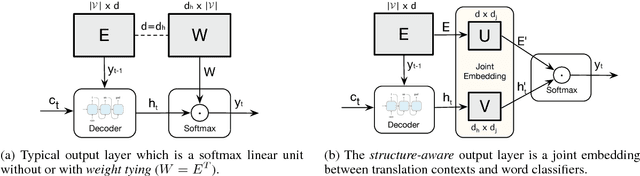
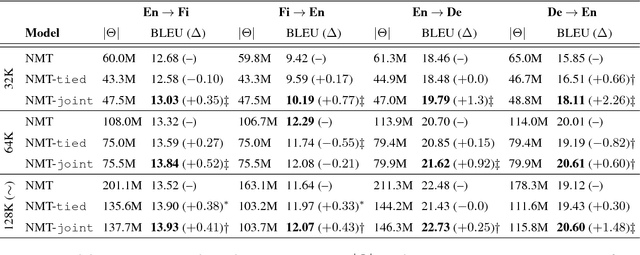
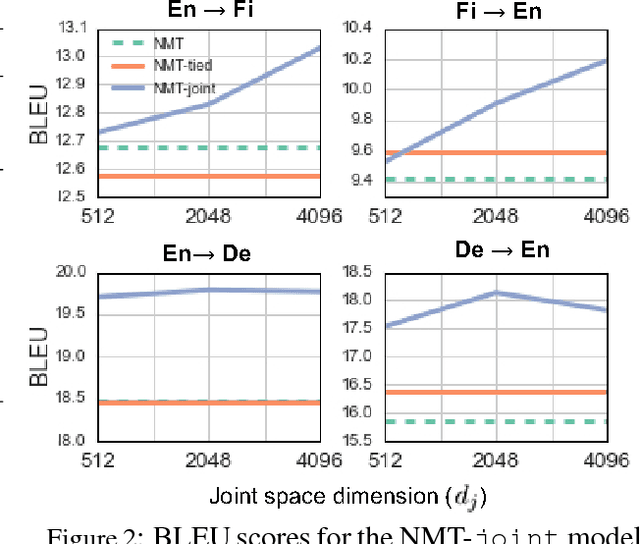
Tying the weights of the target word embeddings with the target word classifiers of neural machine translation models leads to faster training and often to better translation quality. Given the success of this parameter sharing, we investigate other forms of sharing in between no sharing and hard equality of parameters. In particular, we propose a structure-aware output layer which captures the semantic structure of the output space of words within a joint input-output embedding. The model is a generalized form of weight tying which shares parameters but allows learning a more flexible relationship with input word embeddings and allows the effective capacity of the output layer to be controlled. In addition, the model shares weights across output classifiers and translation contexts which allows it to better leverage prior knowledge about them. Our evaluation on English-to-Finnish and English-to-German datasets shows the effectiveness of the method against strong encoder-decoder baselines trained with or without weight tying.