 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularization Advantages of Multilingual Neural Language Models for Low Resource Domains
May 29, 2019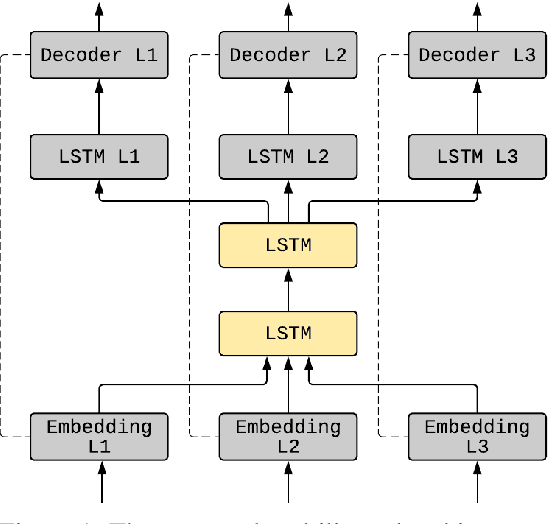
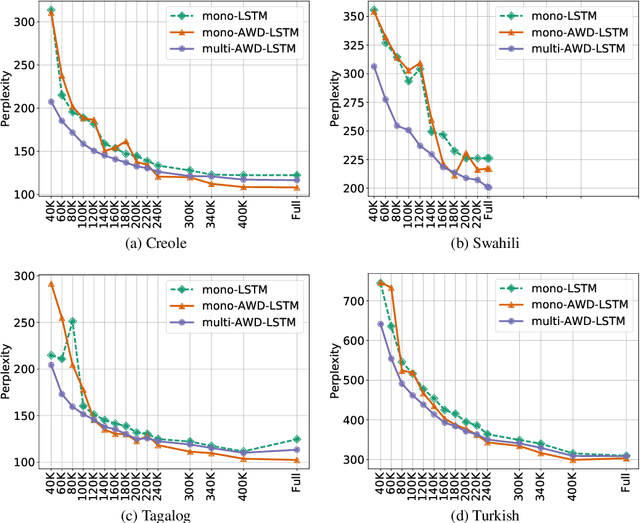
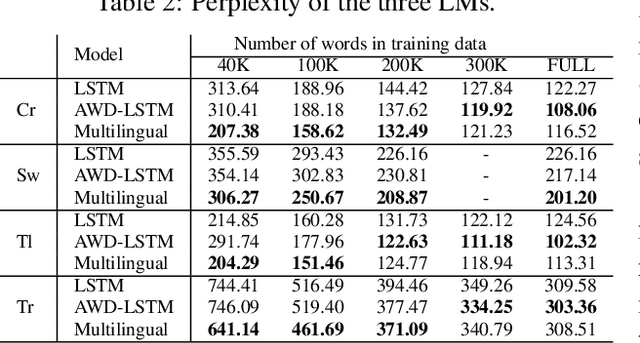
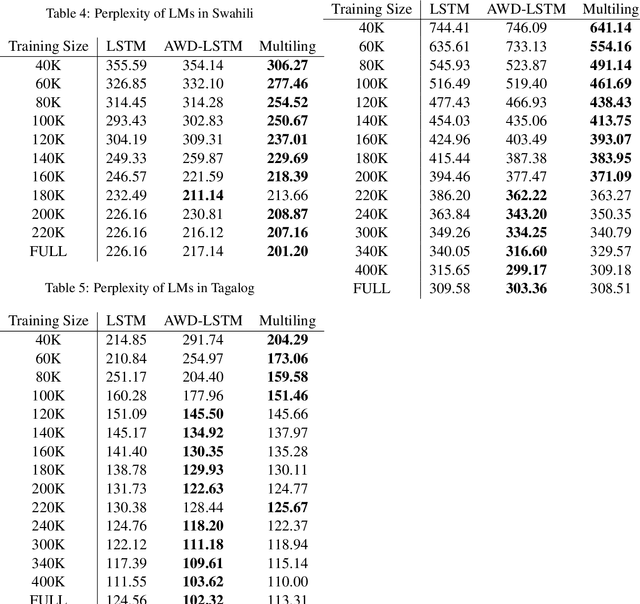
Neural language modeling (LM) has led to significant improvements in several applications, including Automatic Speech Recognition. However, they typically require large amounts of training data, which is not available for many domains and languages. In this study, we propose a multilingual neural language model architecture, trained jointly on the domain-specific data of several low-resource languages. The proposed multilingual LM consists of language specific word embeddings in the encoder and decoder, and one language specific LSTM layer, plus two LSTM layers with shared parameters across the languages. This multilingual LM model facilitates transfer learning across the languages, acting as an extra regularizer in very low-resource scenarios. We integrate our proposed multilingual approach with a state-of-the-art highly-regularized neural LM, and evaluate on the conversational data domain for four languages over a range of training data sizes. Compared to monolingual LMs, the results show significant improvements of our proposed multilingual LM when the amount of available training data is limited, indicating the advantages of cross-lingual parameter sharing in very low-resource language modeling.