 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGADePo: Graph-Assisted Declarative Pooling Transformers for Document-Level Relation Extraction
Aug 28, 2023Document-level relation extraction aims to identify relationships between entities within a document. Current methods rely on text-based encoders and employ various hand-coded pooling heuristics to aggregate information from entity mentions and associated contexts. In this paper, we replace these rigid pooling functions with explicit graph relations by leveraging the intrinsic graph processing capabilities of the Transformer model. We propose a joint text-graph Transformer model, and a graph-assisted declarative pooling (GADePo) specification of the input which provides explicit and high-level instructions for information aggregation. This allows the pooling process to be guided by domain-specific knowledge or desired outcomes but still learned by the Transformer, leading to more flexible and customizable pooling strategies. We extensively evaluate our method across diverse datasets and models, and show that our approach yields promising results that are comparable to those achieved by the hand-coded pooling functions.
TESS: Text-to-Text Self-Conditioned Simplex Diffusion
May 15, 2023



Diffusion models have emerged as a powerful paradigm for generation, obtaining strong performance in various domains with continuous-valued inputs. Despite the promises of fully non-autoregressive text generation, applying diffusion models to natural language remains challenging due to its discrete nature. In this work, we propose Text-to-text Self-conditioned Simplex Diffusion (TESS), a text diffusion model that is fully non-autoregressive, employs a new form of self-conditioning, and applies the diffusion process on the logit simplex space rather than the typical learned embedding space. Through extensive experiments on natural language understanding and generation tasks including summarization, text simplification, paraphrase generation, and question generation, we demonstrate that TESS outperforms state-of-the-art non-autoregressive models and is competitive with pretrained autoregressive sequence-to-sequence models.
RQUGE: Reference-Free Metric for Evaluating Question Generation by Answering the Question
Nov 09, 2022Existing metrics for evaluating the quality of automatically generated questions such as BLEU, ROUGE, BERTScore, and BLEURT compare the reference and predicted questions, providing a high score when there is a considerable lexical overlap or semantic similarity between the candidate and the reference questions. This approach has two major shortcomings. First, we need expensive human-provided reference questions. Second, it penalises valid questions that may not have high lexical or semantic similarity to the reference questions. In this paper, we propose a new metric, RQUGE, based on the answerability of the candidate question given the context. The metric consists of a question-answering and a span scorer module, in which we use pre-trained models from the existing literature, and therefore, our metric can be used without further training. We show that RQUGE has a higher correlation with human judgment without relying on the reference question. RQUGE is shown to be significantly more robust to several adversarial corruptions. Additionally, we illustrate that we can significantly improve the performance of QA models on out-of-domain datasets by fine-tuning on the synthetic data generated by a question generation model and re-ranked by RQUGE.
A Variational AutoEncoder for Transformers with Nonparametric Variational Information Bottleneck
Aug 12, 2022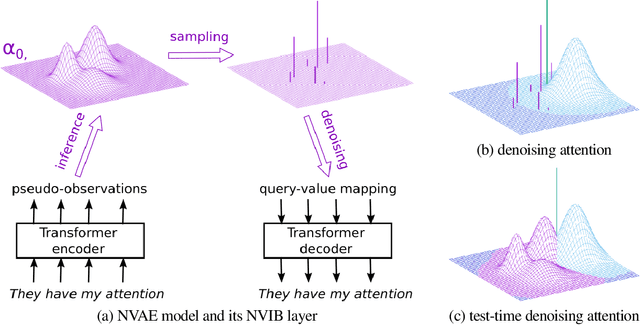
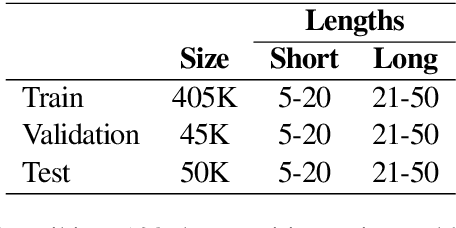
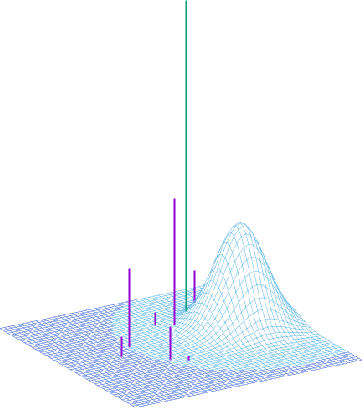
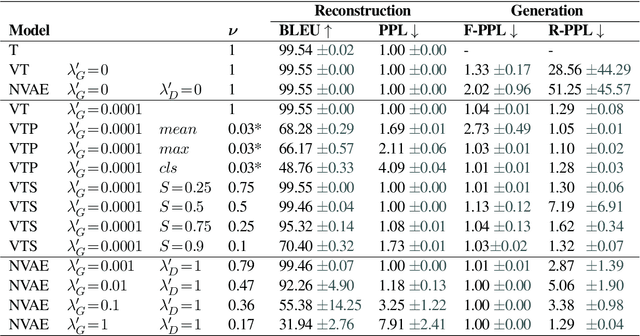
We propose a VAE for Transformers by developing a variational information bottleneck regulariser for Transformer embeddings. We formalise the embedding space of Transformer encoders as mixture probability distributions, and use Bayesian nonparametrics to derive a nonparametric variational information bottleneck (NVIB) for such attention-based embeddings. The variable number of mixture components supported by nonparametric methods captures the variable number of vectors supported by attention, and the exchangeability of our nonparametric distributions captures the permutation invariance of attention. This allows NVIB to regularise the number of vectors accessible with attention, as well as the amount of information in individual vectors. By regularising the cross-attention of a Transformer encoder-decoder with NVIB, we propose a nonparametric variational autoencoder (NVAE). Initial experiments on training a NVAE on natural language text show that the induced embedding space has the desired properties of a VAE for Transformers.
Multilingual Extraction and Categorization of Lexical Collocations with Graph-aware Transformers
May 23, 2022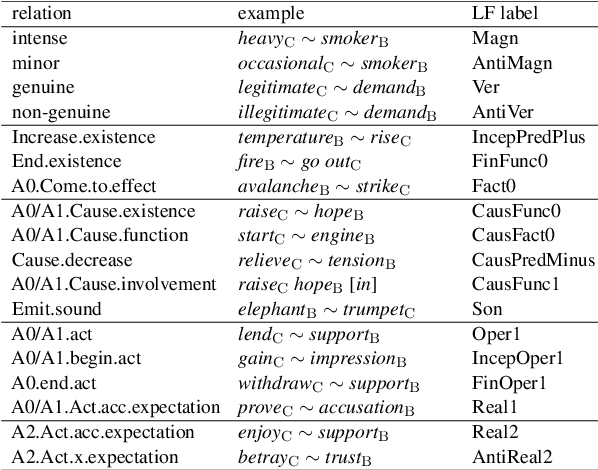
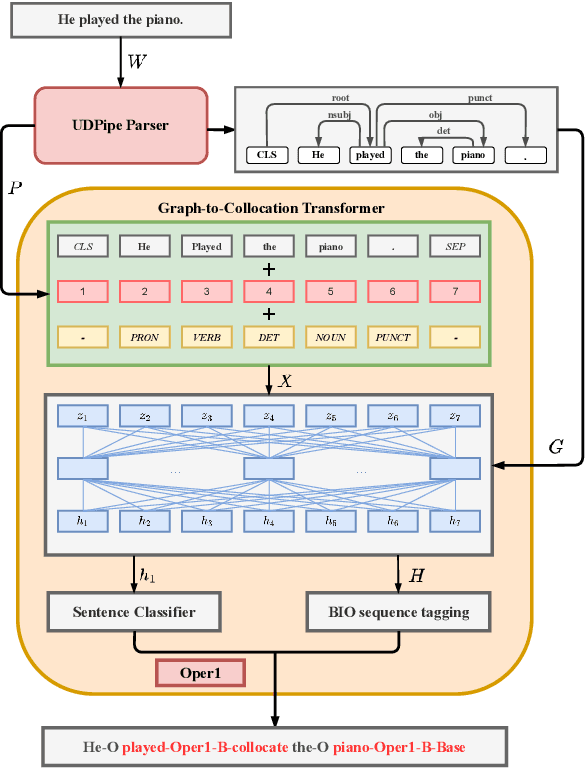
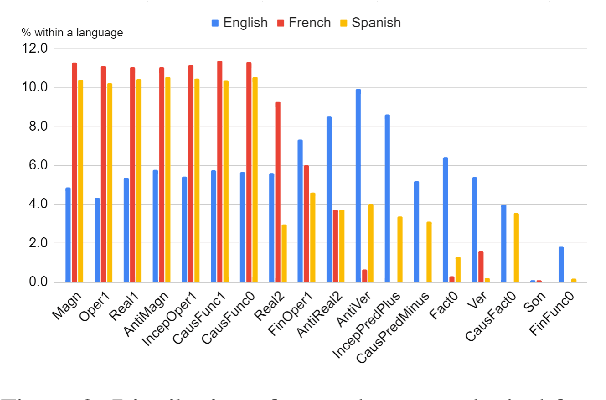
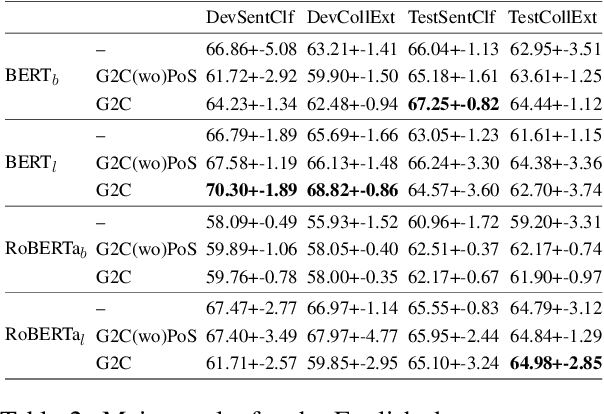
Recognizing and categorizing lexical collocations in context is useful for language learning, dictionary compilation and downstream NLP. However, it is a challenging task due to the varying degrees of frozenness lexical collocations exhibit. In this paper, we put forward a sequence tagging BERT-based model enhanced with a graph-aware transformer architecture, which we evaluate on the task of collocation recognition in context. Our results suggest that explicitly encoding syntactic dependencies in the model architecture is helpful, and provide insights on differences in collocation typification in English, Spanish and French.
What Do Compressed Multilingual Machine Translation Models Forget?
May 22, 2022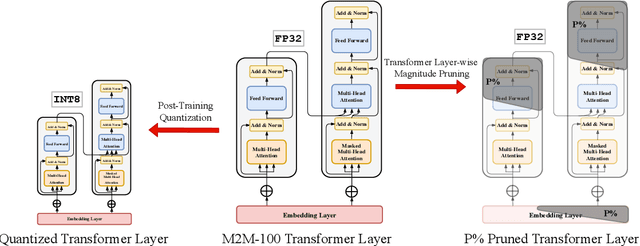

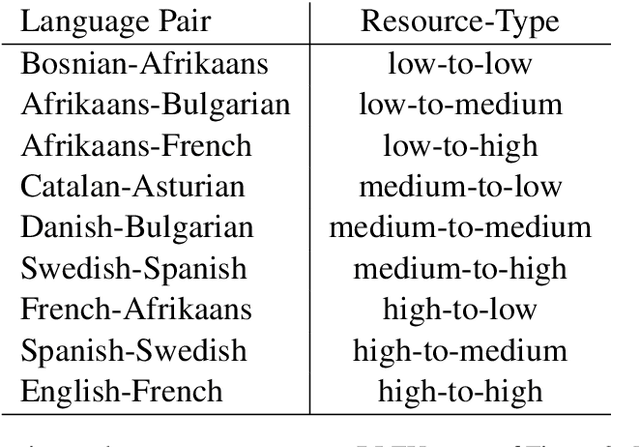
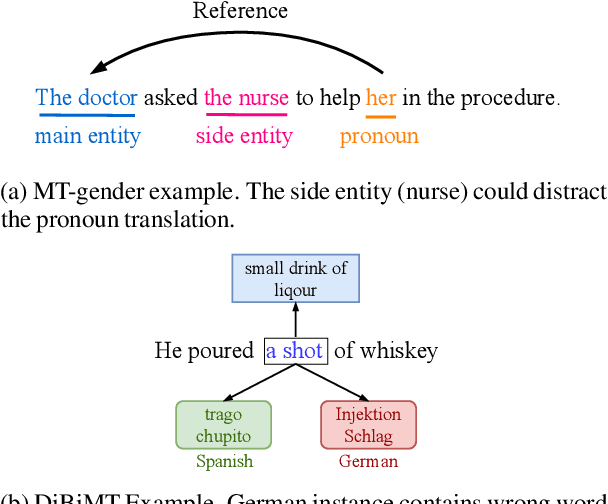
Recently, very large pre-trained models achieve state-of-the-art results in various natural language processing (NLP) tasks, but their size makes it more challenging to apply them in resource-constrained environments. Compression techniques allow to drastically reduce the size of the model and therefore its inference time with negligible impact on top-tier metrics. However, the general performance hides a drastic performance drop on under-represented features, which could result in the amplification of biases encoded by the model. In this work, we analyze the impacts of compression methods on Multilingual Neural Machine Translation models (MNMT) for various language groups and semantic features by extensive analysis of compressed models on different NMT benchmarks, e.g. FLORES-101, MT-Gender, and DiBiMT. Our experiments show that the performance of under-represented languages drops significantly, while the average BLEU metric slightly decreases. Interestingly, the removal of noisy memorization with the compression leads to a significant improvement for some medium-resource languages. Finally, we demonstrate that the compression amplifies intrinsic gender and semantic biases, even in high-resource languages.
PERFECT: Prompt-free and Efficient Few-shot Learning with Language Models
Apr 03, 2022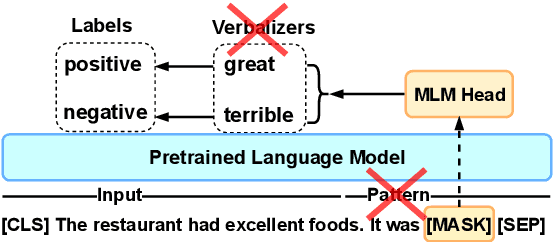
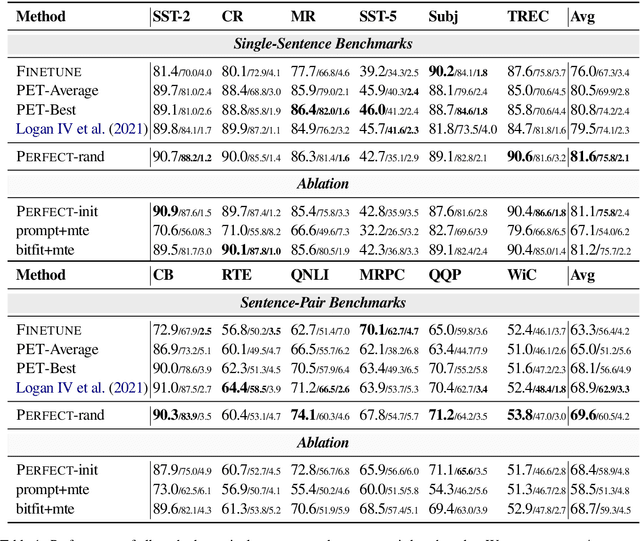
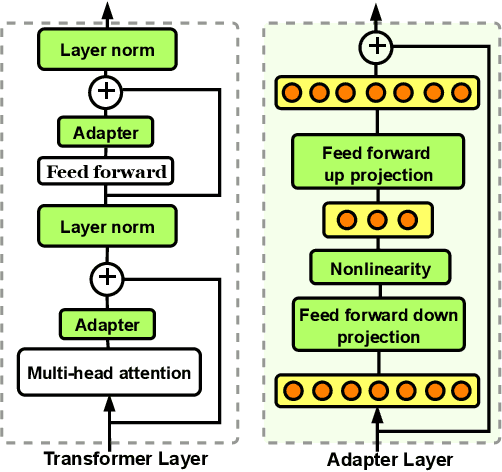
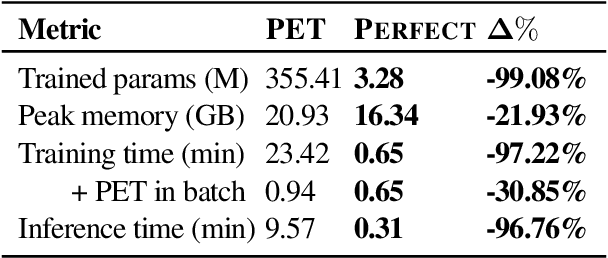
Current methods for few-shot fine-tuning of pretrained masked language models (PLMs) require carefully engineered prompts and verbalizers for each new task to convert examples into a cloze-format that the PLM can score. In this work, we propose PERFECT, a simple and efficient method for few-shot fine-tuning of PLMs without relying on any such handcrafting, which is highly effective given as few as 32 data points. PERFECT makes two key design choices: First, we show that manually engineered task prompts can be replaced with task-specific adapters that enable sample-efficient fine-tuning and reduce memory and storage costs by roughly factors of 5 and 100, respectively. Second, instead of using handcrafted verbalizers, we learn new multi-token label embeddings during fine-tuning, which are not tied to the model vocabulary and which allow us to avoid complex auto-regressive decoding. These embeddings are not only learnable from limited data but also enable nearly 100x faster training and inference. Experiments on a wide range of few-shot NLP tasks demonstrate that PERFECT, while being simple and efficient, also outperforms existing state-of-the-art few-shot learning methods. Our code is publicly available at https://github.com/rabeehk/perfect.
Graph Refinement for Coreference Resolution
Mar 30, 2022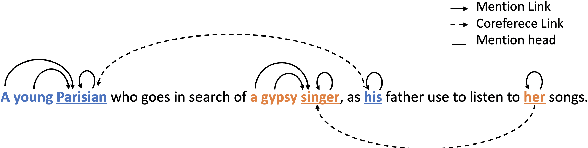
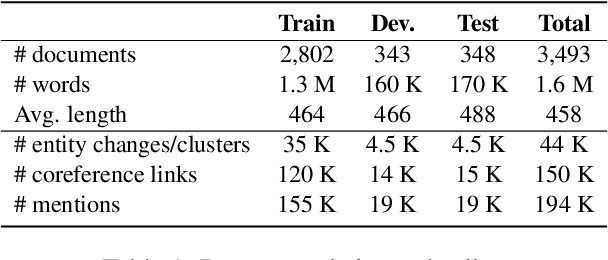
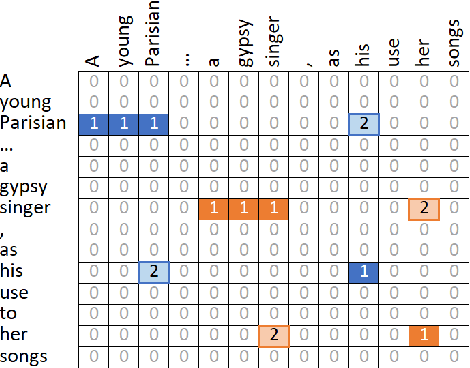
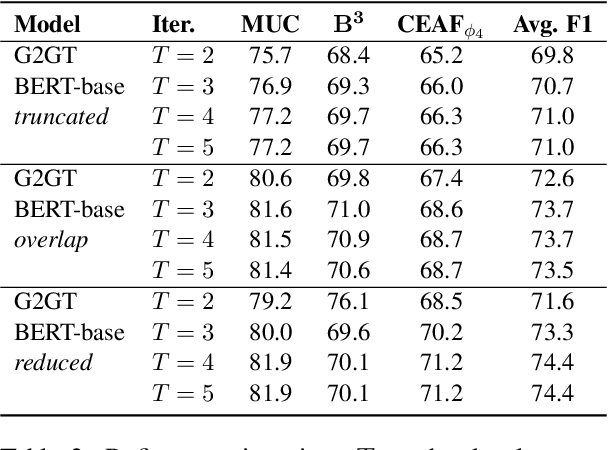
The state-of-the-art models for coreference resolution are based on independent mention pair-wise decisions. We propose a modelling approach that learns coreference at the document-level and takes global decisions. For this purpose, we model coreference links in a graph structure where the nodes are tokens in the text, and the edges represent the relationship between them. Our model predicts the graph in a non-autoregressive manner, then iteratively refines it based on previous predictions, allowing global dependencies between decisions. The experimental results show improvements over various baselines, reinforcing the hypothesis that document-level information improves conference resolution.
HyperMixer: An MLP-based Green AI Alternative to Transformers
Mar 07, 2022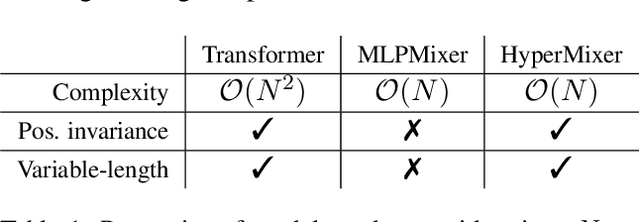
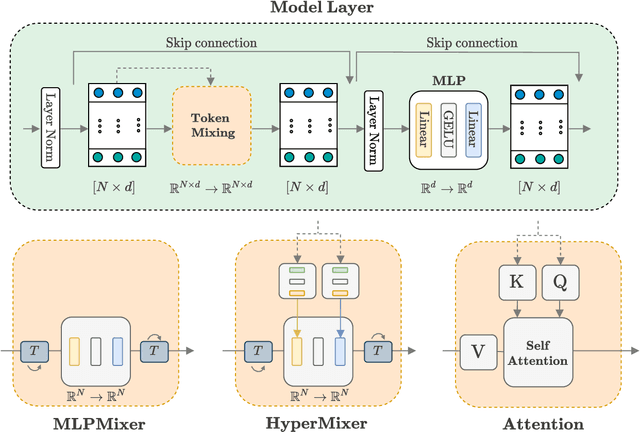
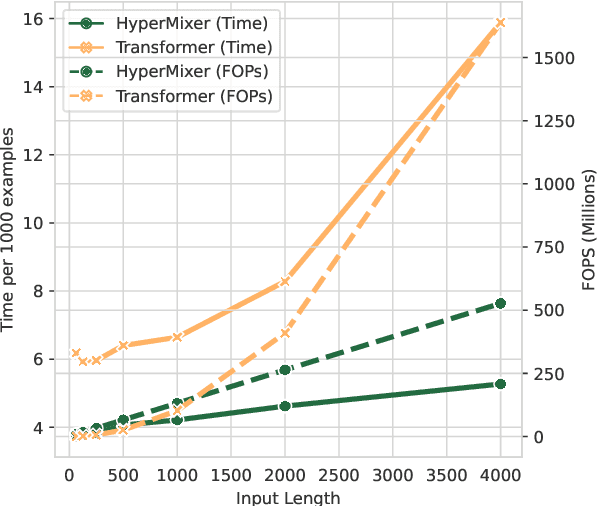
Transformer-based architectures are the model of choice for natural language understanding, but they come at a significant cost, as they have quadratic complexity in the input length and can be difficult to tune. In the pursuit of Green AI, we investigate simple MLP-based architectures. We find that existing architectures such as MLPMixer, which achieves token mixing through a static MLP applied to each feature independently, are too detached from the inductive biases required for natural language understanding. In this paper, we propose a simple variant, HyperMixer, which forms the token mixing MLP dynamically using hypernetworks. Empirically, we demonstrate that our model performs better than alternative MLP-based models, and on par with Transformers. In contrast to Transformers, HyperMixer achieves these results at substantially lower costs in terms of processing time, training data, and hyperparameter tuning.
Bag-of-Vectors Autoencoders for Unsupervised Conditional Text Generation
Oct 13, 2021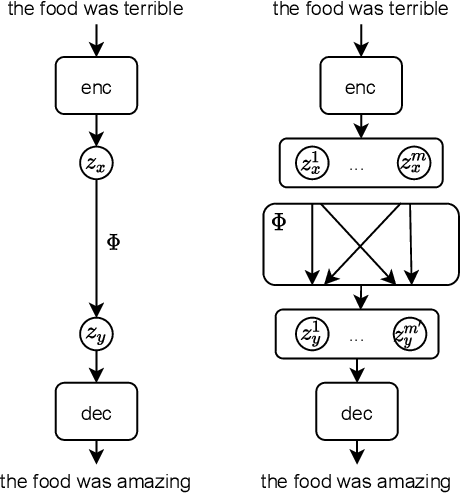
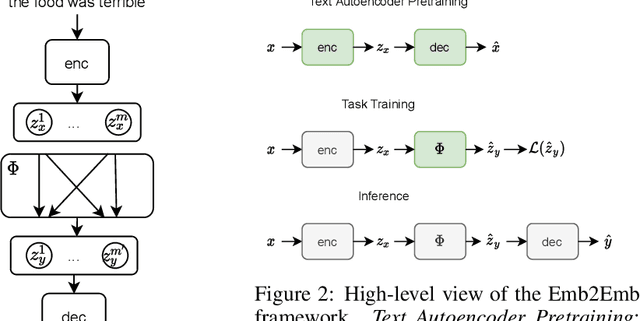
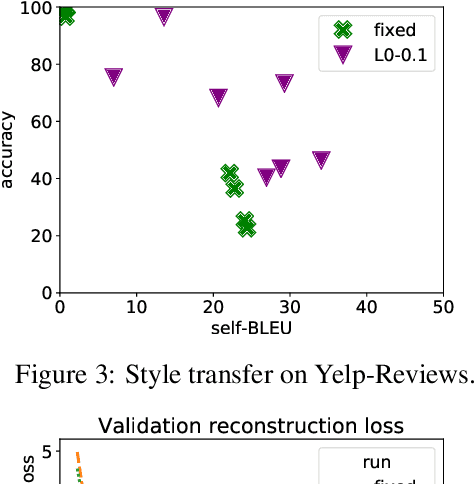
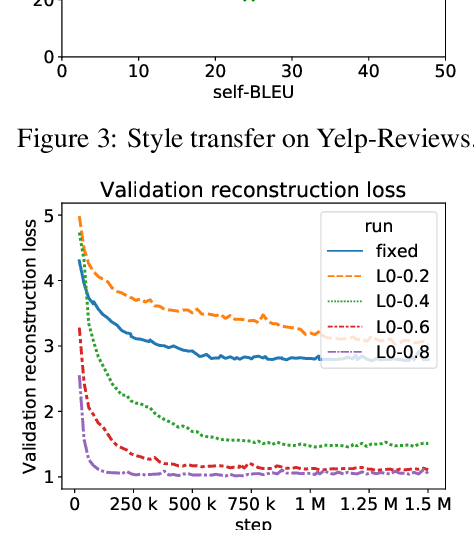
Text autoencoders are often used for unsupervised conditional text generation by applying mappings in the latent space to change attributes to the desired values. Recently, Mai et al. (2020) proposed Emb2Emb, a method to learn these mappings in the embedding space of an autoencoder. However, their method is restricted to autoencoders with a single-vector embedding, which limits how much information can be retained. We address this issue by extending their method to Bag-of-Vectors Autoencoders (BoV-AEs), which encode the text into a variable-size bag of vectors that grows with the size of the text, as in attention-based models. This allows to encode and reconstruct much longer texts than standard autoencoders. Analogous to conventional autoencoders, we propose regularization techniques that facilitate learning meaningful operations in the latent space. Finally, we adapt for a training scheme that learns to map an input bag to an output bag, including a novel loss function and neural architecture. Our experimental evaluations on unsupervised sentiment transfer and sentence summarization show that our method performs substantially better than a standard autoencoder.